







先说结论:BERT其实真没干啥
BERT其实就是在Transformer的基础上,只用了encoder部分,然后在输入端多了一个Segment Embedding(创新点1),用了两个预训练任务(Masked Language Model (MLM))和 Next Sentence Prediction (NSP)(创新点2),然后发明了先在大量无监督文本上预训练,然后针对下游任务进行微调(创新点3【我认为这个是最重要的】),然后就没了,就这三个创新点
所以BERT其实根本就没干啥
介绍
如果你关注自然语言处理技术的发展,那你一定听说过 BERT,它的诞生对自然语言处理领域具有着里程碑式的意义。本次实验将介绍 BERT 的模型结构,以及将其应用于文本分类实践。
知识点
- 语言模型和词向量
- BERT 结构详解
- BERT 文本分类
BERT 全称为 Bidirectional Encoder Representations from Transformer (基于 Transformer 的双向编码表示),是谷歌在 2018 年 10 月发布的语言表示模型。BERT 通过维基百科和书籍语料组成的庞大语料进行了预训练,使用时只要根据下游任务进行输出层的修改和模型微调训练,就可以得到很好的效果。BERT 发布之初,就在 GLUE、MultiNLI、SQuAD 等评价基准和数据集上取得了超越当时最好成绩的结果。但在深入了解 BERT 结构之前,先需要了解一下什么是语言模型,以及在 BERT 诞生之前人们是如何进行文本向量化的。
语言模型和词向量
语言模型 是用于计算文本序列概率的模型。在自然语言处理的发展中,应用较为广泛的语言模型有两种:统计式语言模型和神经网络语言模型。接下来就将分别介绍一下它们。
统计式语言模型
统计语言模型(Statistical Language Model)是根据概率分布,计算字词所组成的字符串出现概率的模型,即公式 (1):
![]() 简单来说,统计式的语言模型就是计算一句话符不符合语言规律。比如,使用语言模型计算出「我今天吃了一个苹果」的概率,一定比「苹果个我今天吃了一」的概率大,所以前者比后者存在的可能性更大。
简单来说,统计式的语言模型就是计算一句话符不符合语言规律。比如,使用语言模型计算出「我今天吃了一个苹果」的概率,一定比「苹果个我今天吃了一」的概率大,所以前者比后者存在的可能性更大。
在具体构建统计式语言模型时,需要使用统计的方法计算公式 (1),为了便于计算,公式 (1)可转化为公式 (2):
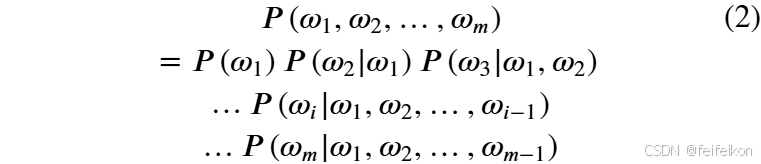
但是在实践中,通常文本的长度较长,所以公式 (2) 的估算会非常困难,因此,研究者们根据 马尔可夫链式法则 提出了 N 元模型(N-Gram Model)。于是得到公式 (3):
![]() 在 N 元模型中,一般采用字词的出现频率来估计 N 元条件概率。可以想象,当 N 值非常大时,计算频率时会存在数据稀疏问题,所以 N 的取值一般为 3,即假设当前词的出现仅与前两个词的组合有关,而与其他词无关 。统计式语言模型可以使用在许多自然语言处理方面的应用上,如语音识别、机器翻译、词性标注、句法分析和资讯检索。不过统计式语言模型也有其局限性,IBM 曾进行过一次信息检索评测,发现二元语言模型需要数以亿计的词汇才能达到最优表现,而三元语言模型则需要数十亿级别的词汇。
在 N 元模型中,一般采用字词的出现频率来估计 N 元条件概率。可以想象,当 N 值非常大时,计算频率时会存在数据稀疏问题,所以 N 的取值一般为 3,即假设当前词的出现仅与前两个词的组合有关,而与其他词无关 。统计式语言模型可以使用在许多自然语言处理方面的应用上,如语音识别、机器翻译、词性标注、句法分析和资讯检索。不过统计式语言模型也有其局限性,IBM 曾进行过一次信息检索评测,发现二元语言模型需要数以亿计的词汇才能达到最优表现,而三元语言模型则需要数十亿级别的词汇。
神经网络语言模型
近年来随着深度学习的发展,研究者们设计出了基于神经网络的语言模型,神经网络语言模型(Nerual Network Language Model)的结构如下图所示:
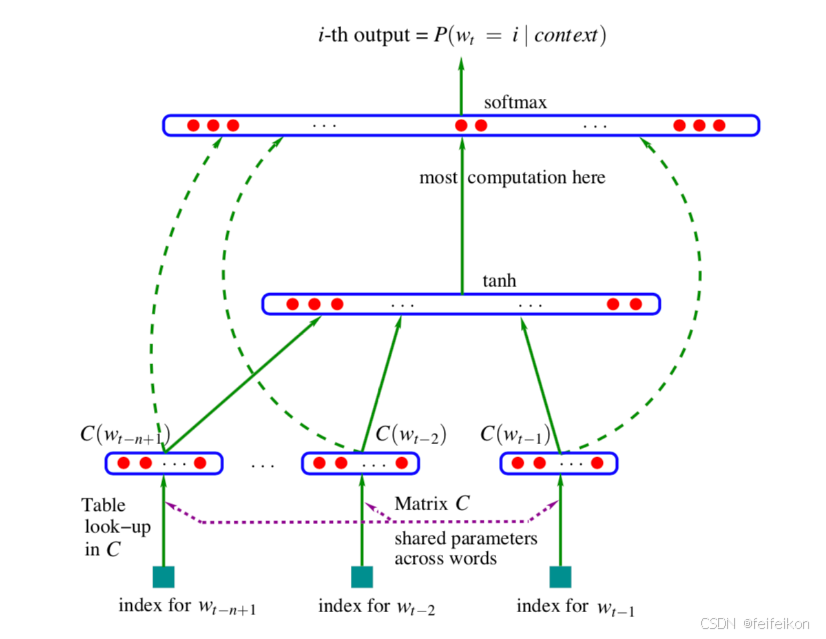
现在来根据上图分析一下模型的结构。
首先,最下层的是输入语句的词对应词表中的编号,然后通过编号在查找表(Look-Up Table)找到对应的词向量。这里的查找表用于将输入的词编号映射为对应的词向量。它是一个可训练的参数矩阵,其中每一行对应于词表中的一个词,而每一列是词向量的一个维度,每个维度对应于词的某种语义特征。具体而言,将输入的词编号作为索引,从查找表中获取对应的行(词向量)。每个词向量是一个实数向量。
接下来是激活函数为 tanh 的全连接层,在这里,将原始的词向量与经过全连接层和激活函数处理后的输出进行结合,输入到最后的全连接层中。这样做的目的是将原始的词向量与模型提取的特征进行融合,模型能够更好地理解和表示输入语句中的词语。
最后使用 Softmax 函数对最后一层的输出进行处理,以计算在给定前文语境下下一个词的预测结果。Softmax 函数将模型的输出转化为一个概率分布,使得每个可能的下一个词都对应一个概率值。这样,模型可以根据概率选择最有可能的下一个词作为预测结果。
可以看到,神经网络语言模型主要使用了全连接层与激活函数代替了统计语言模型的概率计算。在神经网络中有一个副产品:它就是我们接下来要讲到的词向量。
词向量
受到神经网络语言模型的启发,研究者们发现了进行分布式表示词向量的方法,即通过一个词的上下文语境来表示这个词的含义。并且,对比生成基于稀疏表示(Sparse Representation)的词向量的统计方法,例如词袋模型,神经网络生成的分布式表示(Distributed Representation)词向量获得了更好的效果。
但这个方法也存在弊端,即无法表示多义词,并且这个多义词的含义会受到训练语料的影响。例如,「苹果」这个词,在「我爱吃苹果」和「我喜欢苹果公司」中表示的含义是不同的。但如果在训练语料中,大量的语料表示的是苹果的水果的语义,那训练出的词向量中的「苹果」则会包含水果的语义,结果就会导致模型出现理解偏差。
为了解决这个问题,出现了基于上下文的表示(Contextualized Representation)生成词向量的语言模型,这类模型在对句子进行编码时会结合每个词所在语句的前后文语境,这种基于上下文的词向量就成功解决了区分多义词的问题。BERT 就是这样一种生成基于上下文表示词向量的语言模型,接下来了解一下 BERT 的具体结构。
BERT 结构详解
BERT 的整体结构如下图所示,其是以 Transformer 为基础构建的,使用 WordPiece 的方法进行数据预处理,最后通过 MLM 任务和下个句子预测任务进行预训练的语言模型。下面我们从 BERT 的结构:Transformer 出发,来一步步详细解析一下 BERT。(世界名画)
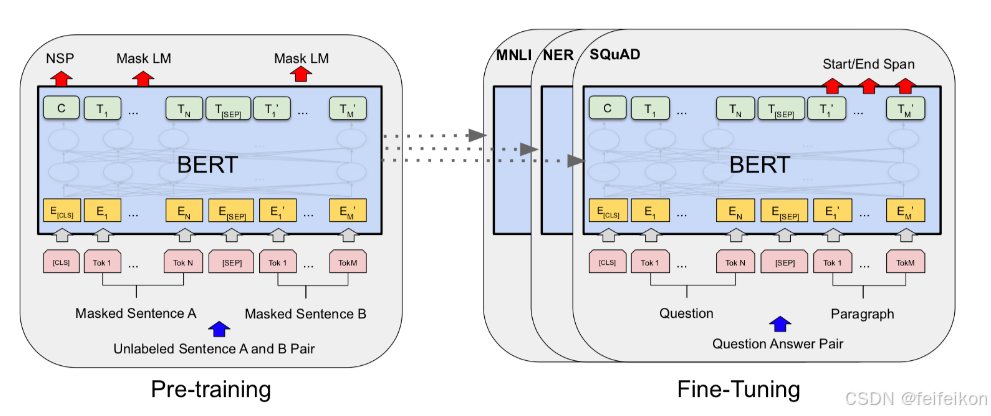
Transformer
首先介绍 BERT 模型结构的基础:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









