







1.源码结构
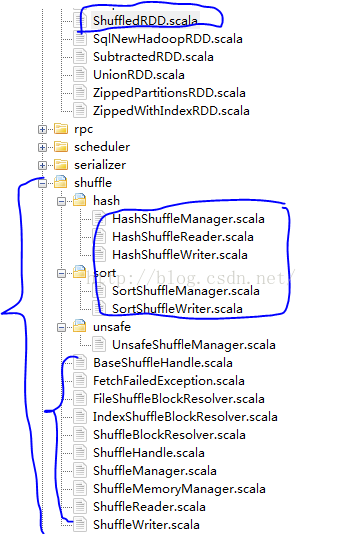
上图是Shuffle的源码组成,我们知道spark快的一个非常大的原因是定义了partition的依赖关系,这样就减少了没有必要的Shuffle stage,减少了对hdfs文件的读写。这也是这篇博客想去分析Shuffle的原因。源码参考的是Spark1.4.1版本,最新版本。
2.ShuffleRDD的类
其继承了RDD类,其中compute方法如下:

可见其从ShuffleManager获取getReader
注:ShuffleManager是Shuffle系统中可插拔的trait,A ShuffleManager is created in SparkEnv on the driver and on each executor, based on the spark.shuffle.manager setting. 在Driver上注册shuffles, executors 或者在本地driver上运行的任务可以读写数据
3.ShuffleManager trait
private[spark] trait ShuffleManager {
/**
* Register a shuffle with the manager and obtain a handle for it to pass to tasks.
* 由Driver注册元数据信息,Driver中的------负责注册Shuffle的元数据
*/
def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle
/** Get a writer for a given partition. Called on executors by map tasks. */
// 获得Shuffle Writer, 根据Shuffle Map Task的ID为其创建Shuffle Writer。
def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V]
/**
* Get a reader for a range of reduce partitions (startPartition to endPartition-1, inclusive).
* Called on executors by reduce tasks.
* 根据Shuffle ID和partition的ID为其创建ShuffleReader。
*/
def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C]
/**
* Remove a shuffle's metadata from the ShuffleManager.
* 删除本地的Shuffle的元数据。
* @return true if the metadata removed successfully, otherwise false.
*/
def unregisterShuffle(shuffleId: Int): Boolean
/**
* how to retrieve block data for a logical shuffle block identifier
* Create and maintain the shuffle blocks' mapping between logic block and physical file location.
*/
def shuffleBlockResolver: ShuffleBlockResolver
/** Shut down this ShuffleManager. 停止Shuffle Manager*/
def stop(): Unit
}ShuffleManager有两个实现类,分别为HashShuffleManager和SortShuffleManager;下面看HashShuffleManager的registerShuffle方法,根据ShuffleId,numMaps、和依赖生成BaseShuffleHandle的实例,得到一个ShuffleHandle的句柄,标识Shuffle。
private[spark] class HashShuffleManager(conf: SparkConf) extends ShuffleManager {
private val fileShuffleBlockResolver = new FileShuffleBlockResolver(conf)
/* Register a shuffle with the manager and obtain a handle for it to pass to tasks. */
override def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle = {
new BaseShuffleHandle(shuffleId, numMaps, dependency)
}BaseShuffleHandle继承abstract class ShuffleHandle,
private[spark] class BaseShuffleHandle[K, V, C](
shuffleId: Int,
val numMaps: Int,
val dependency: ShuffleDependency[K, V, C])
extends ShuffleHandle(shuffleId)其中有个标识依赖的ShuffleDependency类型的参数,其继承了 Dependency抽象类,代码中 红色部分表示对父RDD进行Shuffle注册
@DeveloperApi
class ShuffleDependency[K, V, C](
@transient _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Option[Serializer] = None,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
<span style="color:#ff0000;">val shuffleId: Int = _rdd.context.newShuffleId()</span>
<span style="color:#ff0000;">val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.size, this)</span>
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}
4.ShuffleWriter
/**
* Obtained inside a map task to write out records to the shuffle system.
*/
private[spark] abstract class ShuffleWriter[K, V] {
/** Write a sequence of records to this task's output */
// 写入所有的数据。需要注意的是如果需要在Map端做聚合。(aggregate),那么写入前需要将records做聚合。
@throws[IOException]
def write(records: Iterator[Product2[K, V]]): Unit
/** Close this writer, passing along whether the map completed */
// 写入完成后提交本次写入。
def stop(success: Boolean): Option[MapStatus]
}5.ShuffleBlockResolver
ShuffleBlockResolver trait , 其由实现类FileShuffleBlockResolver和IndexShuffleBlockResolver;这两个实现类分别在HashShuffleManager和SortShuffleManager里面作为val实例。
private[spark]
/**
* <span style="color:#ff6600;">如何从本地指定的block id的数据块中恢复Shuffle数据(i.e. map, reduce, and shuffle).</span>
* Shuffle数据的封装格式为文件或者file segments
*/
trait ShuffleBlockResolver {
type ShuffleId = Int
def getBlockData(blockId: ShuffleBlockId): ManagedBuffer
def stop(): Unit
}// Format of the shuffle block ids (including data and index) should be kept in sync with
// org.apache.spark.network.shuffle.ExternalShuffleBlockResolver#getBlockData().
@DeveloperApi
case class ShuffleBlockId(shuffleId: Int, mapId: Int, reduceId: Int) extends BlockId {
override def name: String = "shuffle_" + shuffleId + "_" + mapId + "_" + reduceId
}ShuffleBlockResolver 的核心读取逻辑是getBlockData。比如在Hash Based Shuffle的从本地读取文件都是通过这个接口实现的以及Sort Based Shuffle需要通过先读取Index索引文件获得每个partition的起始位置后,才能读取真正的数据文件。
stop作用是停止ShuffleBlockResolver
注:ShuffleBlockResolver 在Spark1.3版本并没有,而是ShuffleBlockManager以及其两个实现类FileShuffleBlockManager和IndexShuffleBlockManager,在spark1.4版本修改成为ShuffleBlockResolver 及其两个实现类。
5.Unsafe Shuffle or Tungsten Sort















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









