







1. 基础
1.1. 字符编码
字符编码(Character encoding),计算机的CPU计算、硬盘存储、显示器都是以数字信号存在的。那么所有显示的字符(无论是英文字符、还是中文字符)都是以数字来表示的。字符编码即统一套标准来在不同计算机之间存储传递信息。这一套以数字表示字符的过程,就是字符编码过程。
1.2. 字符集
字符集(Character Set),世界上有很多种文字,每种文字都有一套自己的字库。很多国家为了让计算机正常显示自己的文字,发明了套字符编码方式。这样每个字都有一个数字编码相对应。这种以数字编码应对所有字的集合,就是字符集。
一般情况下,不同文字体系都有一套字符集。如英文是ASCII字符集,简体中文是GBK字符集,繁体字是Big5字符集。字符集太多,不利于信息在全球传递。所以需要一种可以包含所有文字体系的字符集,这种字符集就是Unicode字符集。
1.3. ASCII字符集
ASCII字符集,我们知道计算机最早是美国发明的,所以字符编码这一块儿最早也是美国弄的。ASCII(American Standard Code for Information Interchange,美国信息交换标准代码):使用 7 个 Bit 表示,共 128 个字符,刚好占用了一个字节中的后 7 位,共包括33个控制字符和95个可显示字符。这128个数字编码对应的字符集即是ASCII字符集。
1.4. 简体汉字字符集
- GB2312(Guo Biao 2312)
用双字节表示汉字,但是为了完全兼容 ASCII。汉字区“高字节”范围为 0xB0-0xF7,汉字区“低字节”范围 0xA1-0xFE,占用码位 72*94=6768 个。 - GBK(Guo Biao Kuozhan)
后来发现 GB2312 的字符依然不够用,尤其是像“镕”(朱镕基)字打不出来。然后决定汉字区的低字节完全不兼容 ASCII,只要当前字符属于汉字码,那么其后的字符也属于汉字码。这样在兼容 GB2312 的基础上,再添加了近两万字和字符(兼容繁体、日本汉字、韩国汉字等)。 - GB18030
是 GBK 的扩展版,并且完全兼容 GBK。GB18030和 utf-8 类似,是动态的,既有单字节字体,也有双字节字节(BGK),也有三字节,四字节字符,这样可以节省信息占用量。Windows 默认支持的是 GBK,若要支持 GB18030,需要下载安装单独的支持包。
1.5. Big5
1984 年台湾五家公司联合创立,称大五码,英文 Big5。Big5 也是双字节编码方式,收录了一万多字符,但是没有包含中文简体。Big5 目前也被香港、澳门等地区国家使用。Big5 保存的文本,在简体操作系统下显示乱码。为什么呢?这是因为Big5字符集中的繁体字对应的编码与GBK字符集中的繁体字对应的编码不一样。所以Big5编码的繁体内容文本是无法直接用GKB编码方式解码并显示的。
但是有些编辑器会自动识别出是Big5编码,然后将其按 GBK 繁体字解码,即可以在简体中文操作系统下正常显示。如 Notepad++、Visual Studio Code均可以在简体操作系统下显示Big5编码的文本内容。
1.6. Unicode
Unicode字符集,随着不同国家间越来越紧密的联系,尤其是Web的发展。任何一个网页都可以在全球有正常网络的地方打开浏览。如果新浪网的内容是以GBK编码的,那么在国际的华人可能就无法正常浏览网页内存了。基于信息的全球互通,一个Unicode的国际组织成立,创建了一种Unicode字符集,这种字符集可以容纳所有国家的所有字符编码。
早期的Unicode字符集采用的编码方式是以4个BYTE表示一个字符。那么一个汉字只需要1个Unicode编码表示就可以,但是英文单词却需要很多个Unicode字符表示,这种方式大大增加了英文内存的存储、传输开销。所以Unicode早期一直无法很好地在全球推行。英文内存提供商依然使用传统的ASCII字符编码。采用4BYTE表示一个字符的编码方式被称为UTF-32。
1.7. UTF-16
比较ASCII以及UTF-32各自的优点,一个新的Unicode编码方式采取了一个折中的方案,即UTF-16。世界主流字符用2BYTE即可以表示,但是也必须照顾到那些不常用的字符。那么怎么办呢?
UTF-16将常用的字符安排在0-0xFFFF这个范围,而不常用的安排在0xFFFF之后。那么如何处分0x0001和0x10000这两个字符呢?Unicode委会员商议,将0xD800-0xDFFF这个范围空出来,用来表示是2BYTE的字符,还是4BYTE的字符。Windows下,UTF-16也被称为宽字符。
1.8. UTF-8
UTF-16相比UTF-32,大幅降低了信息传递、存储的消耗。但是英文字符的国家依然觉得增加近一倍的消耗是不可以接受的。Unicode字符集依然难以在世界范围内推行。Unicode急需要一种能够让各方都满意地编码方式才行。在这种情况,UTF-8出现了。UTF-8编码方式的设计是完全兼容ASCII编码的,这样就不会增加英文字符的开销,并且可以完整表达所有的Unicode字符集。
我们知道标准的ASCII字符集只表示128个字符,最高位是没有使用的。在UTF-8编码中,如果1BYTE中最高Bit为0,则当前BYTE和ASCII编码相同。如果最高Bit为1,则表示当前BYTE是Unicode编码,接下来有几个1,就表示这个字符的Unicode编码占有几个BYTE。如0x1111 0XXX XXXX XXXX,就表示这个字符占用4个BYTE。
UTF-8是变字节长度的,用 1-6 个字节表示字符。用一个字符表示常见字符,用二个字节表示拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚等,用三字符表示常见汉字等,四至六个字节的字符比较少见。
UTF-8这么好,是不是大家都开始用UTF-8呢?不一定。UTF-8兼容性好,但正因为要兼容各种情况,所以解析内容的时候随时需要判断,效率低。所有有一些操作系统,如Windows的Unicode编码方式采用了UTF-16,像Java的字符串编码也是采用UTF-16,C++新标准支持UTF-16、UTF-32。新语言Rust更是直接采用了UTF-32编码方式,相当于空间换效率。
1.9. 代码页
代码页(CodePag):,代码页是字符集的数字值,不同的语言使用不同的代码页。例如,ANSI代码页为 1252,日文代码页为 932,简体中文(GBK)代码页为 936,繁体中文(Big5)代码页为 950。
更多代码页信息见:https://docs.microsoft.com/en-us/previous-versions/aa913244(v=msdn.10)
1.10. 本地化
本地化(Locale)在这里是指操作系统中的一个概念,即操作系统的相关信息要本地化,主要是指语言编码及显示的本地化,也即执行代码和UI显示的本地化。
- 执行代码的本地化
操作系统如何读写解析一个文本。有一个文本,其内容是以GBK编码、Big5编码,抑或还是以UTF-8编码。如简体中文操作系统默认的本地化是指当前进程运行代码使用字符集为GBK字符集。如果有一个文本存储的是以Big5编码的文本内容,想在简体操作系统中正常识别这些内容,我们就需要调用API setlocale来设置代码页,来让当前线程代码的本地化为big5字符集。 - UI显示的本地化
UI显示的本地化主要是针对应用程序的资源显示本地化,即UI要显示操作系统对应的本地化语言。例如台湾和香港使用的都是繁体字,都是使用Big5编码集,但是台湾的本地化和香港的本地化可能有一些小的差别,个别地方的翻译可能不一样。例如新加坡和中国大陆使用简体汉字,都是使用GBK编码,但是操作系统中的很多词在两地表示是不一样的。
1.11. 大小端
- 大小端
我们知道根据CPU处理数据流的不同,有大端和小端之分。 - UTF-16
UTF-16一般是2BYTE表示,高BYTE中的一些BIT用做保留位。那么在CPU处理数据流的时候,就需要区分大端还是小端,以提处理效率。Windows文本保存类型分UTF-16 LE(Little-endian)和UTF-16 BE(Big-endian),即在文本前面2BYTE字节头,FF FE表示小端,FEFF表示大端。 - 带BOM的UTF-8
UTF-8本身设计的时候,每个BYTE的高位就是标记位,是可以区分大小端的。所以UTF-8理论上是不需要区分大小端的。Windows设计时,加了BOM头,用以更快地识别当前文本的编码方式。如EFBBBF表示UTF-8大端。Windows文件驱动可以自动根据文本内容识别出普通的不带BOM的UTF-8编码文本。
1.12. 半角与全角
- 半角:
用ASCII编码表示的字符即是半解字节,等价于英文字符,每个字符占1BYTE。
如:ABCD,.?012345 - 全角
简体操作系统下的GBK编码默认将所有的英文字符用GBK编码重新实现了一套,每个字符占2BYTE。
如:ABCD,。?012345
1.13. 语言包
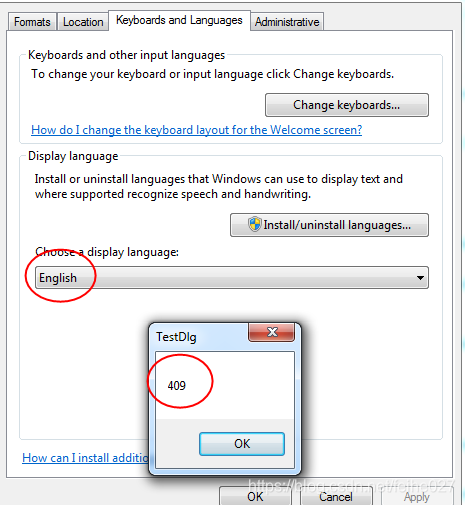
Windows操作系统的UI文字显示默认是与当前操作系统环境语言一致。Windows支持修改当前UI文字的显示语言。即通过Control Panel\All Control Panel Items\Region and Language\Keyboards and Language\Display language\Choose a display language来安装并选择相应的语言包,即可以显示相应的语言。
操作系统语言包主要有2个作用:
- 翻译作用,将操作系统中所有涉及到语言翻译成对应的语言包内容。
- 描述作用,如英文操作系统默认已经有了所有语言的代码页(也即字符集),操作系统知识每个汉字对应的GBK编码是多少,但是操作系统的显示驱动配合显示,如字体等。
- 注意:语言包只是修改UI显示的本地化,并不会修改代码执行的本地化。
GetUserDefaultUILanguage()获取的是UI的LCID(LocalelID),即语言包设置的LCID。例如台湾和香港使用的都是繁体字,都是使用Big5编码集,但是台湾的本地化和香港的本地化可能有一些小的差别,个别地方的翻译可能不一样。例如新加坡和中国大陆使用简体汉字,都是使用GBK编码,但是操作系统中的很多词在两地表示是不一样的,即两国的本地化不同,即LCID不同。
更多LCID见:https://docs.microsoft.com/en-us/openspecs/windows_protocols/ms-lcid/a9eac961-e77d-41a6-90a5-ce1a8b0cdb9c
2. 字符编码的应用
2.1. UTF-16和MBCS之C标准函数
// UTF-16在Windows中即代表Unicode,也即宽字符集WCS
// MBCS,多字节字符集,泛指GBK、BIG5等字符集
wchar_t szUnicode[32] = {0};
char szTran[32] = {0xc3, 0x61};
if (-1 == mbstowcs(szUnicode, szTran, sizeof(szTran)))
{
return TRUE;
}
char szSimp[32] = {0};
if (-1 == wcstombs(szSimp, szUnicode, sizeof(szSimp)))
{
return TRUE;
}
2.2. GBK转UTF-8
int GBK2UTF8(char *szGbk,char *szUtf8,int Len)
{
// 先将多字节 GBK(CP_ACP 或 ANSI)转换成宽字符 UTF-16
// 得到转换后,所需要的内存字符数
int n = MultiByteToWideChar(CP_ACP,0,szGbk,-1,NULL,0);
// 字符数乘以 sizeof(WCHAR) 得到字节数
WCHAR *str1 = new WCHAR[sizeof(WCHAR) * n];
// 转换
MultiByteToWideChar(CP_ACP, // MultiByte 的代码页 Code Page
0, //附加标志,与音标有关
szGbk, // 输入的 GBK 字符串
-1, // 输入字符串长度,-1 表示由函数内部计算
str1, // 输出
n // 输出所需分配的内存
);
// 再将宽字符(UTF-16)转换多字节(UTF-8)
n = WideCharToMultiByte(CP_UTF8, 0, str1, -1, NULL, 0, NULL, NULL);
if (n > Len)
{
delete[]str1;
return -1;
}
WideCharToMultiByte(CP_UTF8, 0, str1, -1, szUtf8, n, NULL, NULL);
delete[]str1;
str1 = NULL;
return 0;
}
2.3. UTF-8转GBK
int UTF82GBK(char *szUtf8,char *szGbk,int Len)
{
int n = MultiByteToWideChar(CP_UTF8, 0, szUtf8, -1, NULL, 0);
WCHAR * wszGBK = new WCHAR[sizeof(WCHAR) * n];
memset(wszGBK, 0, sizeof(WCHAR) * n);
MultiByteToWideChar(CP_UTF8, 0,szUtf8,-1, wszGBK, n);
n = WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, NULL, 0, NULL, NULL);
if (n > Len)
{
delete[]wszGBK;
return -1;
}
WideCharToMultiByte(CP_ACP,0, wszGBK, -1, szGbk, n, NULL, NULL);
delete[]wszGBK;
wszGBK = NULL;
return 0;
}
2.4. Big5转GBK
// 950即繁体的CodePage,936即简体的CodePage
wchar_t szUnicode[32] = {0};
char szTran[32] = {0xc3, 0x61};
setlocale(LC_ALL, ".950");
if (-1 == mbstowcs(szUnicode, szTran, sizeof(szTran)))
{
return TRUE;
}
setlocale(LC_ALL, ".936");
char szSimp[32] = {0};
if (-1 == wcstombs(szSimp, szUnicode, sizeof(szSimp)))
{
return TRUE;
}
2.5. 其他转换方法
// Cstring转换Unicode
CString str(_T("Soccer is best!"));
BSTR pstrUni = str.AllocSysString();
SysFreeString(pstrUni);
// ATL Unicode和MBCS转换
USES_CONVERSION;
CString tmpStr;
char*LineChar="fdsfdsa";
const WCHAR * cLineChar = A2W(LineChar);
USES_CONVERSION;
CString tmpStr;
WCH LineChar="fdsfdsa";
const char* cLineChar = A2W(LineChar);
2.6. Windows语言包及相关
我们知道Windows操作系统是可以设置不同的语言的。不同语言相当一个语言包,一种语言包可能几十MB,语言多了,这个语言包也比较大。所以windows默认是不包括其他语言的语言包的。如,简体中文操作系统需要显示为英文,需要安装英文语言包。英文操作系统要显示中文,要安装东亚语言包(包括中文、日文、韩文)。安装好语言包,选择对应语言,重启,即可以显示相应的语言。GetUserDefaultUILanguage可以获取安装语言包后选择的语言人LCID(如下图)。GetSystemDefaultUILanguage和GetSystemDefaultLangID的作用不同,详细MSDN。
















 3239
3239











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









