







作者:CHEONG
公众号:AI机器学习与知识图谱
研究方向:自然语言处理与知识图谱
这篇汇报从F1-Score、Wordunit、Word Emb、Charunit、Crf、Note、Efficiency、Gazetters和LM多个视角对比了14篇NER论文,14篇原论文获取请关注公众号后回复:NER综述。详细内容请见PPT内容。
一、总结
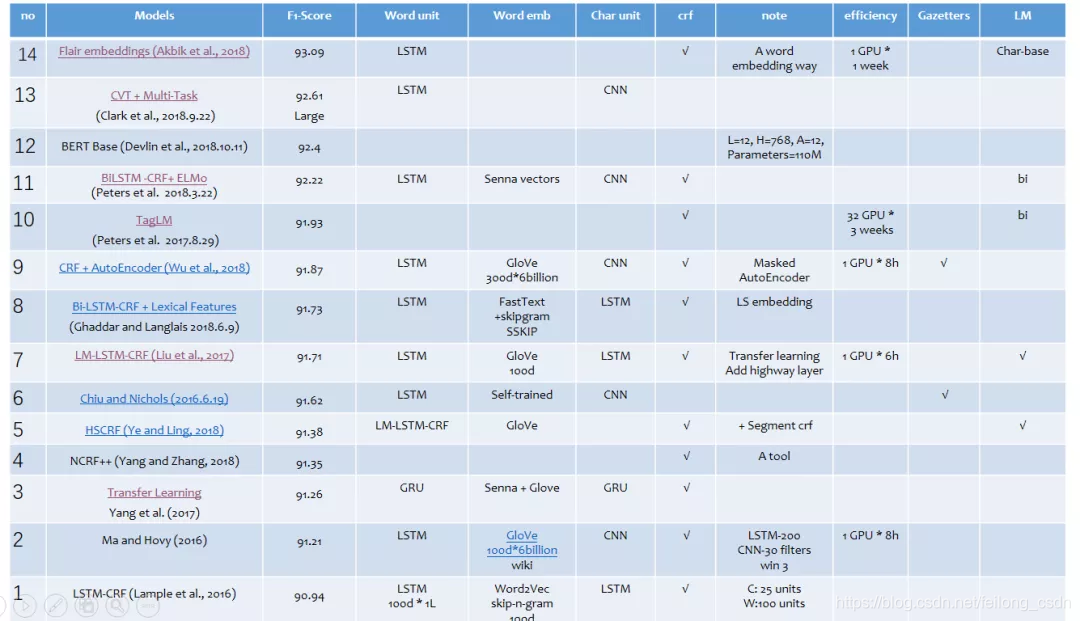

二、Paper PPT
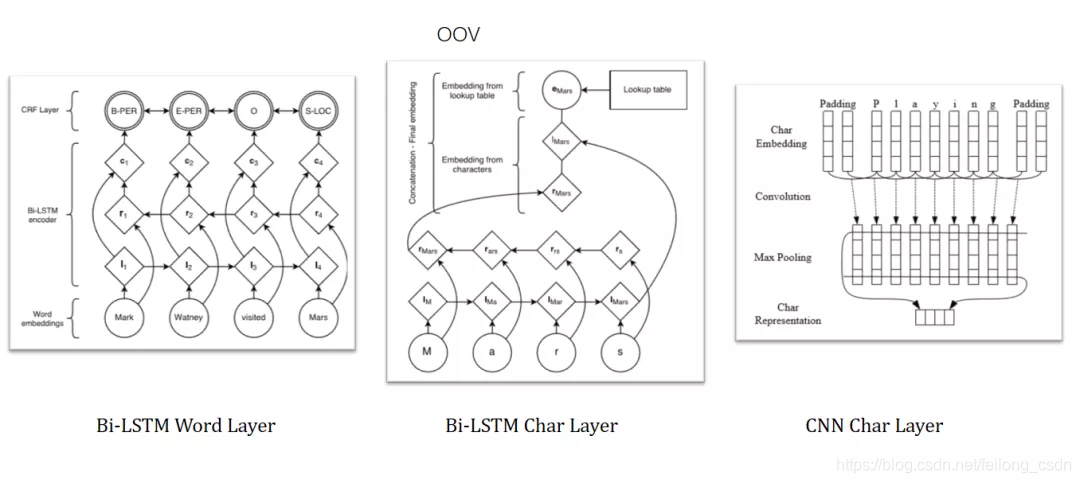
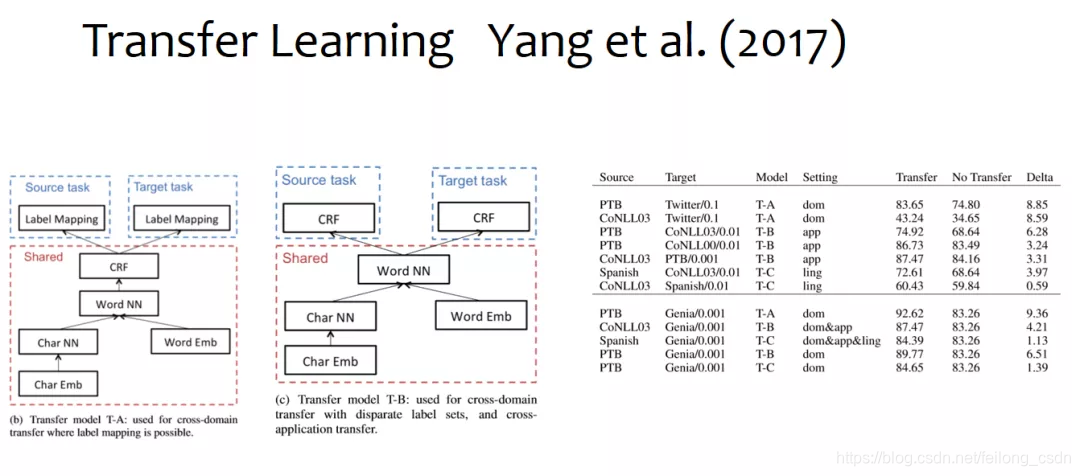
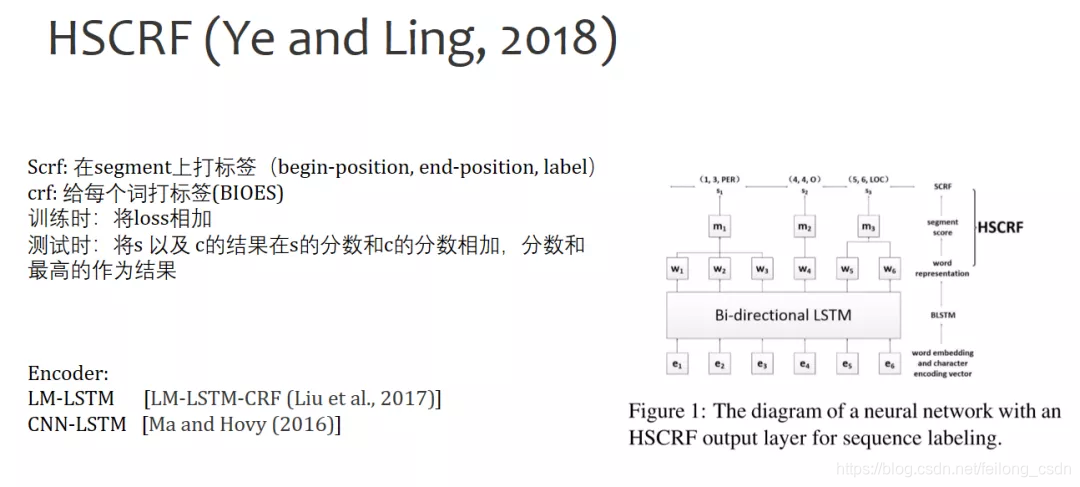
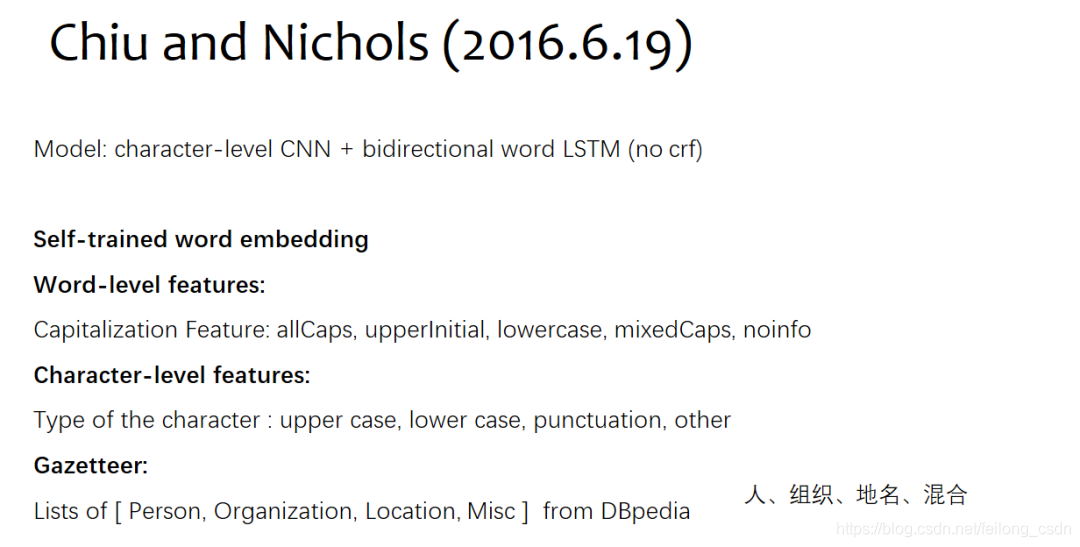
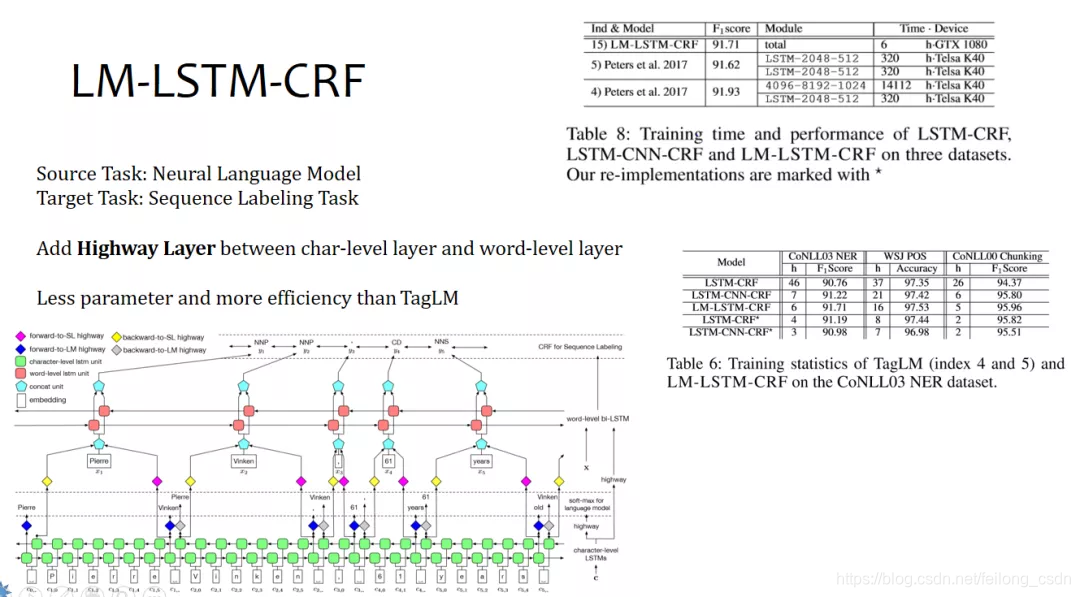

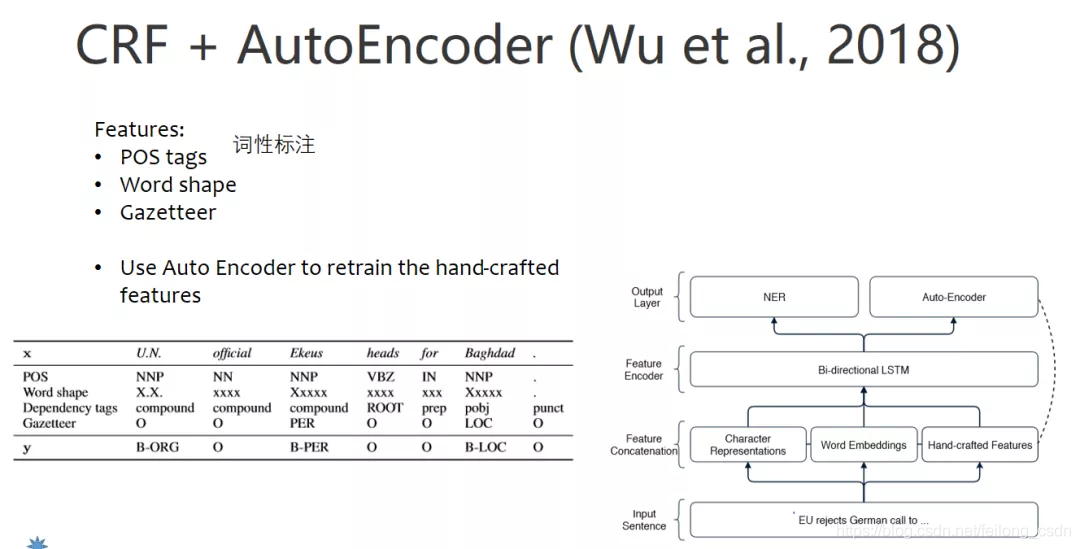

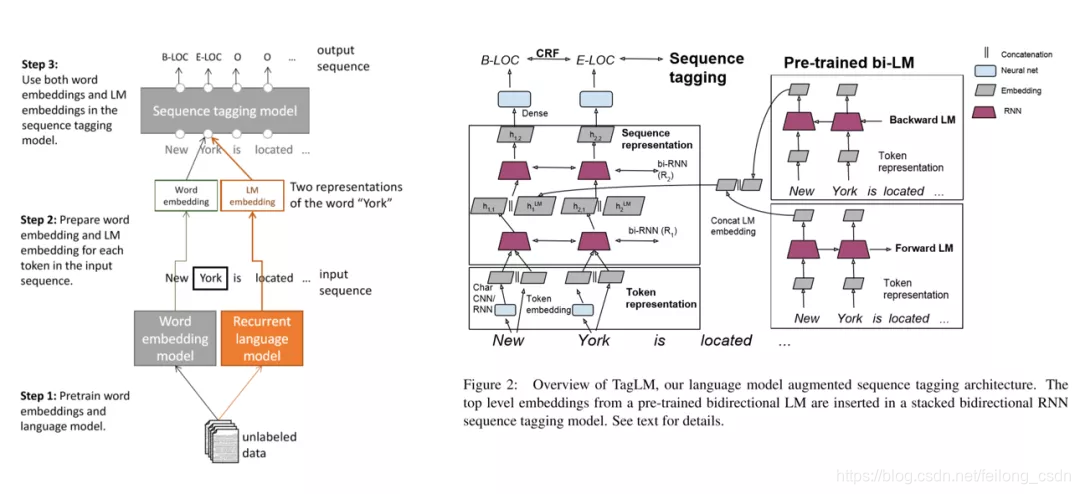

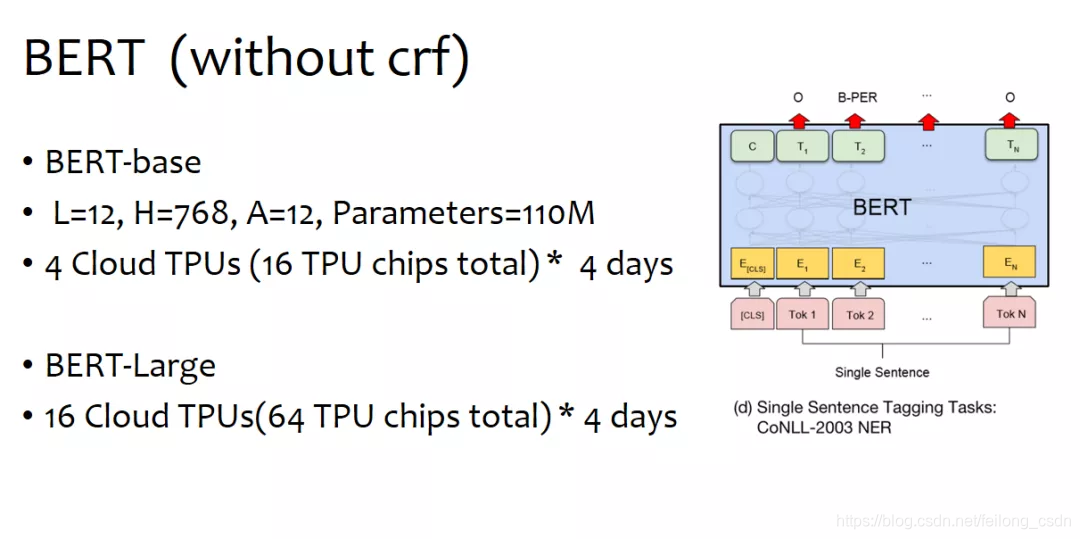

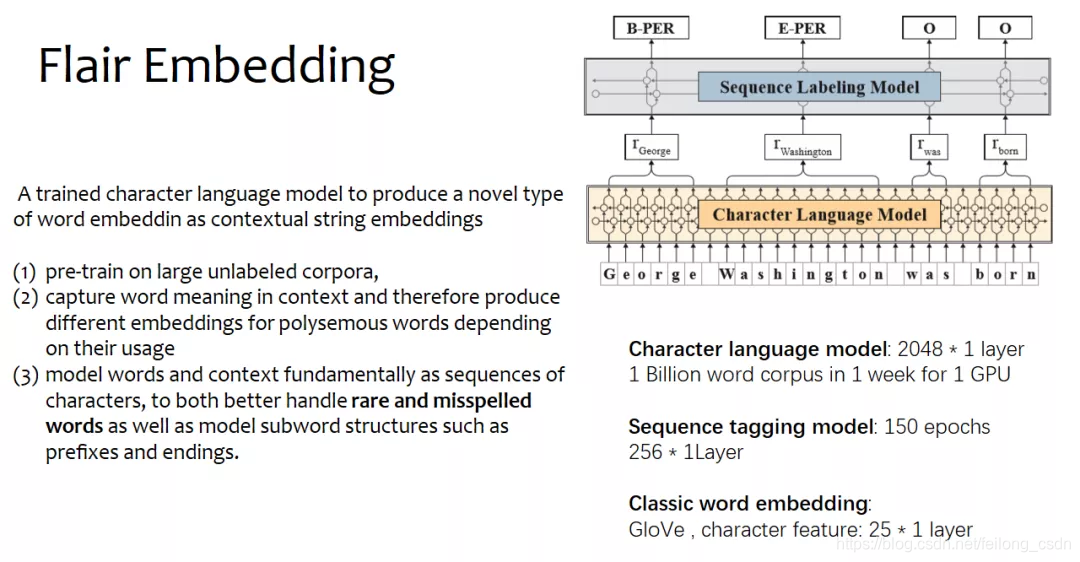
三、往期精彩
【知识图谱系列】探索DeepGNN中Over-Smoothing问题
【知识图谱系列】知识图谱表示学习综述 | 近30篇优秀论文串讲
【知识图谱系列】动态知识图谱表示学习综述 | 十篇优秀论文导读
Transformer模型细节理解及Tensorflow实现
GPT,GPT2,Bert,Transformer-XL,XLNet论文阅读速递
Word2vec, Fasttext, Glove, Elmo, Bert, Flair训练词向量教程+数据+源码
14篇原论文获取请关注公众号后回复:NER综述。原创不易,有用就点个赞呀


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









