







什么是相似度
两个事物的相似程度
常见方法
数据是连续、有序的
向量
用向量表示事物,通常有三种方式计算其相似度:
- 距离
- 夹角
- 相关系数
基于距离的相似度计算
- 闵可夫斯基距离(Minkowski Distance)
d
i
s
t
(
X
,
Y
)
=
(
∑
i
=
1
n
∣
x
i
−
y
i
∣
p
)
1
/
p
dist(X,Y) = (\sum_{i=1}^n\left|{x_i-y_i}\right|^p)^{1/p}
dist(X,Y)=(∑i=1n∣xi−yi∣p)1/p
-
p = 1 p=1 p=1 曼哈顿距离(Manhattan Distance) d i s t ( X , Y ) = ∑ i = 1 n ∣ x i − y i ∣ dist(X,Y) = \sum_{i=1}^n{\left|x_i-y_i\right|} dist(X,Y)=∑i=1n∣xi−yi∣

-
p = 2 p=2 p=2 欧氏距离(Euclidean Distance) d i s t ( X , Y ) = ∑ i = 1 n ( x i − y i ) 2 dist(X,Y) = \sqrt{\sum_{i=1}^n{(x_i-y_i)^2}} dist(X,Y)=∑i=1n(xi−yi)2

-
p = ∞ p=\infty p=∞ 切比雪夫距离(Chebyshev Distance) d i s t ( X , Y ) = m a x ( ∣ x i − y i ∣ ) dist(X,Y) = max(\left|x_i-y_i\right|) dist(X,Y)=max(∣xi−yi∣)
-
缺点:
- 将各个分量的量纲 (scale),也就是“单位”
- 没有考虑各分量的分布(期望、方差等)
- 马氏距离(Mahalanobis Distance)
有M个样本向量 X 1 X_1 X1~ X m X_m Xm,协方差矩阵记为S,均值记为向量μ。
d i s t ( X i , Y j ) = ( X i − X j ) T S − 1 ( X i − X j ) dist(X_i,Y_j) = \sqrt{(X_i-X_j)^TS^{-1}(X_i-X_j)} dist(Xi,Yj)=(Xi−Xj)TS−1(Xi−Xj)- S = I S=I S=I 欧氏距离(Euclidean Distance),协方差矩阵是单位矩阵(各个样本向量之间独立同分布)
- S = Λ S=\Lambda S=Λ 标准化欧氏距离(Standardized Euclidean distance),协方差矩阵是对角矩阵
- 兰氏距离(Lance Williams Distance)
d i s t ( X , Y ) = ∑ i = 1 n ∣ x i − y i ∣ x i + y i dist(X,Y) = \sum_{i=1}^n{\frac{\left|{x_i-y_i}\right|}{x_i+y_i}} dist(X,Y)=∑i=1nxi+yi∣xi−yi∣
基于夹角的相似度计算
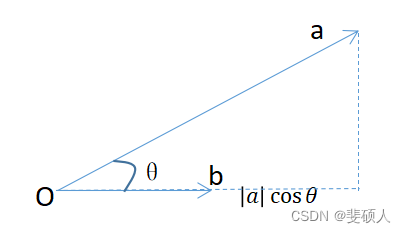
- 点积(投影)
可以反映一个向量在另一个向量上投影的长度(标量)
S i m i l a r i t y = A ⋅ B = ∣ A ∣ ∣ B ∣ c o s θ = ∣ B ∣ ( ∣ A ∣ c o s θ ) Similarity = A\cdot B = \left|A\right|\left|B\right|cos\theta = \left|B\right|(\left|A\right|cos\theta) Similarity=A⋅B=∣A∣∣B∣cosθ=∣B∣(∣A∣cosθ)
- 余弦相似度(Cosine Similarity)
两个向量之间的夹角大小
S i m i l a r i t y = c o s ( θ ) = A ⋅ B ∣ A ∣ ∣ B ∣ Similarity = cos(\theta)=\frac{A \cdot B}{\left|A\right| \left|B\right|} Similarity=cos(θ)=∣A∣∣B∣A⋅B - Tanimoto系数 (Tanimoto Coefficient)(广义Jaccard相似系数)
S i m i l a r i t y = A ⋅ B ∣ ∣ A ∣ ∣ 2 + ∣ ∣ B ∣ ∣ 2 − A ⋅ B Similarity = \frac{A \cdot B}{{\left||A\right||^2} + {\left||B\right||^2} -A \cdot B} Similarity=∣∣A∣∣2+∣∣B∣∣2−A⋅BA⋅B
基于相关系数的相似度计算
- 皮尔逊相关系数 (Pearson Correlation Coefficient)
消除量纲的影响
S i m i l a r i t y = p ( x , y ) = ∑ x i y i − n x y ˉ ( n − 1 ) S x S y = n ∑ x i y i − ∑ x i ∑ y i n ∑ x i 2 − ( ∑ x i ) 2 n ∑ y i 2 − ( ∑ y i ) 2 Similarity = p(x,y)=\frac{\sum{x_iy_i}-n\bar{xy}}{(n-1)S_xS_y} = \frac{n\sum{x_iy_i}-\sum{x_i}\sum{y_i}}{\sqrt{n\sum{x_i^2}-(\sum{x_i})^2}\sqrt{n\sum{y_i^2}-(\sum{y_i})^2}} Similarity=p(x,y)=(n−1)SxSy∑xiyi−nxyˉ=n∑xi2−(∑xi)2n∑yi2−(∑yi)2n∑xiyi−∑xi∑yi
当两个向量均值都为0时,皮尔逊相对系数等于余弦相似性。
数据是离散、无序的
集合
事物使用集合表示时,用
交并补计算其相似度
-
汉明距离(Hamming Distance)(信号距离)
将其中一个字符串变为另外一个字符串所需要的最小替换次数。 -
杰卡德相似系数 (Jaccard similarity coefficient)
两个集合的交集元素在并集中所占的比例
J ( A , B ) = ∣ A ∩ B ∣ ∣ A ∪ B ∣ J(A,B) = \frac{ \left|A \cap B \right| } { \left|A \cup B \right|} J(A,B)=∣A∪B∣∣A∩B∣ -
杰卡德距离(Jaccard distance)
用两个集合中不同元素占所有元素的比例,杰卡德相似系数的补。
J δ ( A , B ) = 1 − J ( A , B ) = ∣ A ∪ B ∣ − ∣ A ∩ B ∣ ∣ A ∪ B ∣ J_{\delta}(A,B) = 1- J(A,B) = \frac{ \left|A \cup B \right| - \left|A \cap B \right| } {\left|A \cup B \right|} Jδ(A,B)=1−J(A,B)=∣A∪B∣∣A∪B∣−∣A∩B∣
分布
- KL散度(Kullback-Leibler Divergence)
相对熵,表示两个随机分布之间的相似性。
D K L ( p ∣ ∣ q ) = ∑ i = 1 N p ( x i ) ( l o g p ( x i ) q ( x i ) ) D_{KL}(p||q) = \sum_{i=1}^N{p(x_i)(log\frac{p(x_i)}{q(x_i)})} DKL(p∣∣q)=∑i=1Np(xi)(logq(xi)p(xi))
KL散度大于等于0,当p=q时等于0;KL散度不满足对称性。
适用场景
- 数据是离散无序的、还是连续有序的
- 数据量纲影响大小,大的话使用皮尔逊相关系数
- 数据密集程度,数据密集、类似聚类问题使用距离类方法,数据稀疏使用角度类方法
相关文章:














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









