







第一节 参考
【万字长文】Kafka最全知识点整理(建议收藏)-腾讯云开发者社区-腾讯云
实操 | 10分钟带你轻松掌握 Kafka 源码编译环境搭建,调试无忧!-腾讯云开发者社区-腾讯云
第二节 常用命令
1. kafka-server-start.sh,kafka-server-stop.sh
2../kafka-console-producer.sh --bootstrap-server ip:port --topic xxxTopic
3./kafka-topics.sh --zookeeper localhost:port --list
4../kafka-topics.sh --zookeeper localhost:port --topic xxxTopic --describe
5../kafka-run-class.sh kafka.tools.DumpLogSegments --files /logPath/kafkaData-0/00000000000000000000.log --print-data-log | grep 'xxxKeyWord' --color
6../kafka-consumer-groups.sh --bootstrap-server ip:port --describe --group xxGroupName --command-config /xxx/jaas.conf
7./kafka-consumer-groups.sh --bootstrap-server ip:port --describe --group xxGroupName --command-config /path/jaas.conf --members / --state
8./kafka-dump-log.sh --files /patitionName/00000000000000020658.log --print-data-log
第三节 原理
1.broker:集群的每台服务器。消费的offset由consumer控制,broker是无状态的,不需要加锁.
2.topic:订阅的主题.每个主题有一个队列.
3.partition:分区,可以线性拓展,负载均衡,提高吞吐率.每个Partition一个目录,用来存储消息和索引文件。消息的删除,可以最近一周等时间,或者文件大小策略.某个 Partition 的数据只会被某一个特定的 Consumer 实例所消费。也就是说 Kafka 对消息的分配是以 Partition 为单位分配的,而非以每一条消息作为分配单元。
4.producer:生产者发布消息到broker,设置topic,key,data.在ProducerRecord中设置topic,key,value.key用来计算发送到哪个partition.
5.consumer:消费者消费broker的消息,设置group,topic.在ConsumerRecord中可以获取offset,key,value.commit操作会在Zookeeper中保存该 Consumer 在该 Partition 中读取的消息的 offset。先读消息,再commit.
6.Consumer Rebalance.有 consumer 的leader分配,分为JoinGroup 请求和 SyncGroup 请求。
7.consumer group:消费者分组。不同的组可以重复消费同一个topic消息。不指定group则属于默认的group.
8.replication-factor:副本数量.
9.日志文件:每个日志文件都是一个log entrie序列,每个log entrie包含一个4字节整型数值(值为N+5,代表消息长度),1个字节的 "magic value",4个字节的 CRC 校验码,其后跟N个字节的消息体payload。每条消息都有一个当前 Partition 下唯一的 64 字节的 offset,它指明了这条消息的起始位置。
10.segment:最新版本,每个segment类似mysql的分表,hbase的hfile,以当前segment的第一条消息为名称存储到xxx.kafka文件.以前版本存在.index,.log,.snapshot,.timeindex文件中。文件名也是偏移.索引文件存储每个segment的offset范围.
11.delivery guarantee 语义:
(1).At most once 消息可能会丢,但绝不会重复传输,对应先commit,再处理消息,处理完可能crash没有commit,不能再次读.
(2).先处理再commit.处理完crash,没有commit,会重复消费.At least once消息绝不会丢,但可能会重复传输.业务自己处理重复幂等性.kafka默认保证这个,允许通过设置Producer异步提交来实现 At most once
(3).Exactly once 每条消息肯定会被传输一次且仅传输一次,很多时候这是用户所想要的幂等性。
12.同异步模式.ask有0,1,-1三个值.Producer发送message.send.max.retries(默认值为 3)此后失败,同步就抛异常,异步继续发送后面数据.同步直接发送消息,异步入队,等累计到指定数量再发送消息.
13.Replica备份.实现HA高可用,单机宕机数据丢失.producer和consumer和一个leader中交互,其他follower从leader中复制数据.
一个topic的partition数量大于broker数量,均匀分布.Kafka 分配 Replica 的算法如下:(1).将所有 Broker(假设共 n 个 Broker)和待分配的Partition 排序.(2).将第 i 个 Partition 分配到第(i mod n)个 Broker上. (3)将第 i 个 Partition 的第 j 个Replica 分配到第((i + j) mode n)个 Broker 上.
Leader收到了ISR中的所有 Replica 的 ACK,该消息就被认为已经 commit 了,replica只是写入内存日志即可ACK,无需同步数据.Leader 将增加 HW 并且向 Producer 发送 ACK。Consumer 读消息也是从 Leader 读取,只有被 commit 过的消息(offset 低于 HW 的消息)才会暴露给 Consumer。
14.leader选举.Leader Election算法有ZooKeeper 的 Zab , Raft 和 Viewstamped Replication 。而 Kafka 所使用的 Leader Election 算法更像微软的 PacificA 算法。宕机时,Controller向zk注册/brokers/ids节点的Watch,选择幸存的replica作为leader,不用等所有的replica都恢复,太久。
15.page cache
16.kafka事务.通过producer id,transaction id和control message实现Exactly once事务操作.
第四节 源码
一.服务端启动
入口core\src\main\scala目录下.kafka.Kafka#main方法.
1.调用kafka.Kafka#getPropsFromArgs解析进程参数的配置信息.
2.创建KafkaServer对象.
3.启动核心逻辑都在KafkaServer#startup方法实现。
3.1 调用KafkaServer#initZkClient初始化zk连接.初始化/consumers、/ids等zk路径.
3.2调用MetaPropertiesEnsemble.Loader#load读取log目录下的patition的元数据进行加载.没有topic的场景下在meta.properties文件中,只有broker.id和cluster.id信息
3.3调用kafka.server.DynamicBrokerConfig#initialize从zk中读取kafka的一些动态配置.
3.4调用org.apache.kafka.server.util.KafkaScheduler#startup启动kafka调度器.
3.5初始化kafka.server.QuotaFactory.QuotaManagers
3.6调用kafka.log.LogManager#startup初始化log数据管理器.在此方法中,启动一些定时器,比如kafka.log.LogManager#cleanupLogs清理log,kafka.log.LogManager#flushDirtyLogs刷新脏log,kafka.log.LogManager#deleteLogs删除logs。
3.7调用kafka.server.NodeToControllerChannelManagerImpl#start开始和controller通信.
3.8调用kafka.server.ZkAlterPartitionManager#start启动分区变化管理器,监听zk的分区变化.
3.9调用kafka.server.ReplicaManager#startup启动partition分区管理器.
3.10.调用kafka.zk.KafkaZkClient#registerBroker向zk的ids目录注册当前broker信息.
3.10调用kafka.controller.KafkaController#startup启动kafkaController.
3.11调用org.apache.kafka.coordinator.group.GroupCoordinator#startup处理存储偏移信息的topic,__consumer_offsets。
3.12调用kafka.coordinator.transaction.TransactionCoordinator#startup启动事务协调器.
3.13创建kafka.server.FetchManager#FetchManager和远程通信.
3.14创建kafka.server.KafkaApis,在kafka.server.KafkaApis#handle方法中,关联了所有网络请求的业务处理入口.
二.生产者
(一).发送消息
生产者需要创建KafkaProducer对象,ProducerRecord消息对象,调用KafkaProducer#send()发送消息.
1.初始化KafkaProducer,进入构造方法,初始化KafkaProducer的ProducerConfig、Partitioner、keySerializer、interceptors、transactionManager、batchSize(默认16k)、RecordAccumulator、ProducerMetadata、Sender等成员.
2.进入KafkaProducer#send()方法发送消息,先进入ProducerInterceptors#onSend进入各个拦截器,默认是空的。进入KafkaProducer#doSend方法.
2.1进入KafkaProducer#waitOnMetadata拉取集群元数据,主要是找到topic的leader partition的ip和端口,哪个partition.
2.1.1.先从配置中获取集群地址,判断是否无效topic。
2.1.2.如果是第一次请求向该topic发送消息,把该topic放到ProducerMetadata#newTopics的set中.
2.1.3调用org.apache.kafka.clients.NetworkClient#wakeup方法唤醒网络客户端.此时其他线程向集群发送网络请求获取元数据信息.
2.1.4.最多等待60秒钟后,查询MetadataSnapshot#clusterInstance中的元数据信息.
2.2.调用StringSerializer#serialize序列化消息的key和value内容.
2.3.调用KafkaProducer#partition方法计算发往哪个partition。默认的Partitioner为空,分区的计算方式为
return Utils.toPositive(Utils.murmur2(serializedKey)) % numPartitions;
对序列化的key使用hash后对partition数量取余.
2.4调用RecordAccumulator#append,先判断partition是否发生变化.把封装好的ProducerBatch对象加入到RecordAccumulator#incomplete和topic的RecordAccumulator.TopicInfo#batches中.有其他线程把这个消息发送到集群中.这个batches类型为ConcurrentMap<Integer /*partition*/, Deque<ProducerBatch>> batches,每次到16k大小,发送一个批次消息,每个批次存在这个batches中,map的key是不同的partition.
2.5判断是否处理事务消息.
2.6.如果batch已经满了,唤醒KafkaClient线程发送队列中的消息.进入Sender#run->Sender#runOnce->Sender#sendProducerData方法.
2.6.2调用RecordAccumulator#ready判断消息是否准备好发送,判断逻辑如图
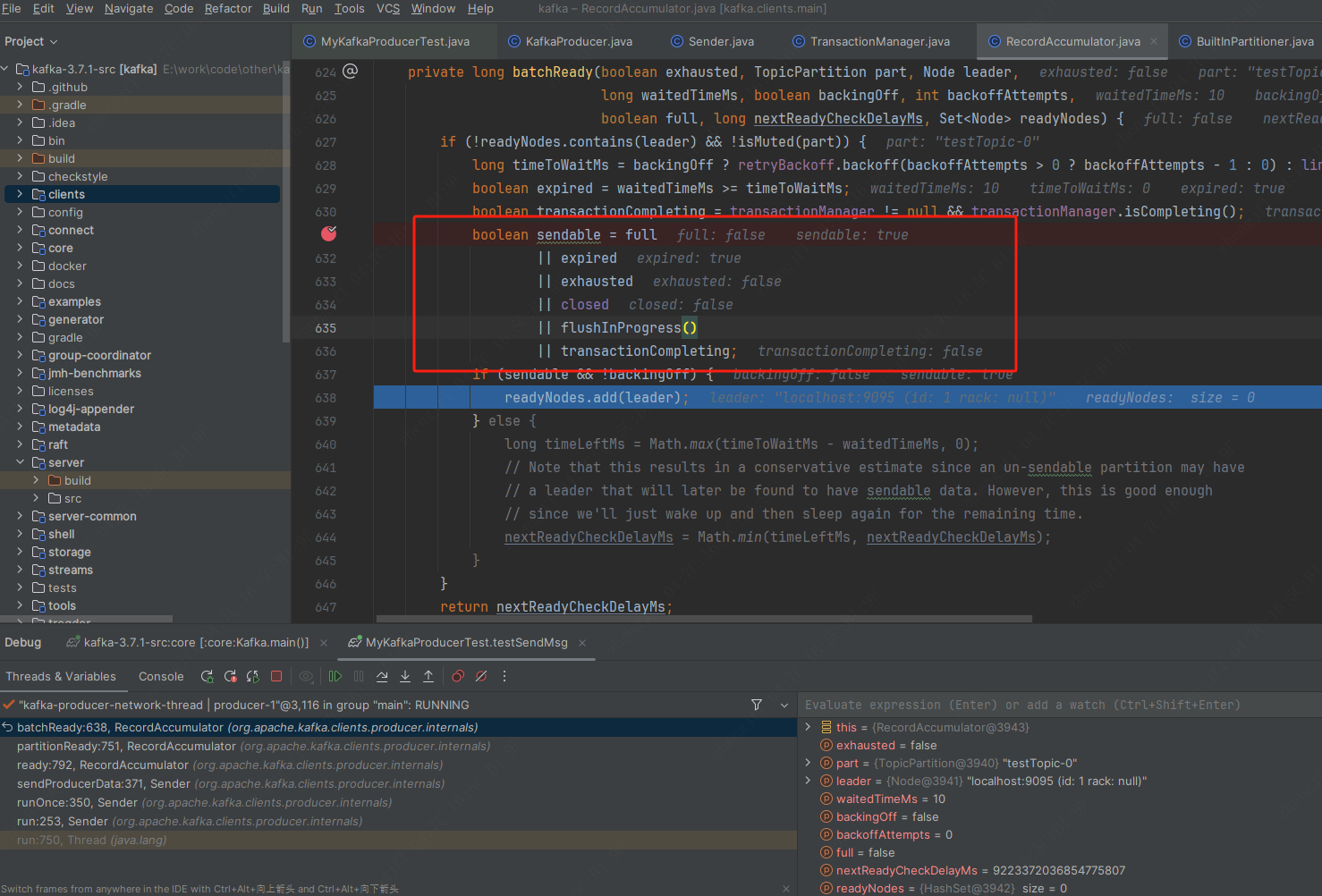
主要消息是否过期,16k是否已满.
2.6.3调用Sender#inFlightBatches添加到在途队列中.
2.6.4调用Sender#sendProduceRequest->NetworkClient#send,进入网络层发送消息.
三.消费者
(一).接收消息
进入KafkaConsumer#poll()->LegacyKafkaConsumer#poll().
1.判断是否订阅了topic。如果metadata超时,调用LegacyKafkaConsumer#updateFetchPositions拉取最新的元数据.
2.调用LegacyKafkaConsumer#pollForFetches->Fetcher#sendFetches拉取数据.
2.1调用AbstractFetch#prepareFetchRequests选择要拉取的broker和replica信息.
2.2调用ConsumerNetworkClient#send()把请求放入ConsumerNetworkClient#unsent队列中,唤醒Selector去发送拉取请求.
2.3拉取成功后调用AbstractFetch#handleFetchSuccess.
四.服务端网络层
五.服务端集群处理消息
(一).客户端创建topic
shell脚本格式
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 3 --partitions 2 --topic testTopic.
java入口org.apache.kafka.tools.TopicCommand#main.
1.初始化topic配置信息的包装类CommandTopicPartition,包含name、分区数,副本数等信息.
2.调用KafkaAdminClient#createTopics创建topic.
2.1封装TopicMetadataAndConfig元数据对象.封装CreateTopicsRequest创建topic请求,向服务端的controller发送请求.
2.2调用AdminClientRunnable#enqueue把创建topic请求入发送队列.
(二).服务端创建topic
转发到broker的controller处理,进入kafka.server.KafkaApis#handleCreateTopicsRequest方法.
依次处理初始化CreatableTopicResult创建topic的结果对象,调用AuthHelper#filterByAuthorized过滤有授权的topic,调用ZkAdminManager#createTopics创建topic.这个方法是创建topic的核心方法.
1.判断MetadataCache元数据缓存中是否已有同名topic.如有,抛topic已存在异常.解析partition和factor数量.检查topic是不是标记为删除,已存在,有_.等转移字符.
2.调用AdminZkClient#createTopicWithAssignment创建topic在zk中的path路径,写入partition的分区信息.如图
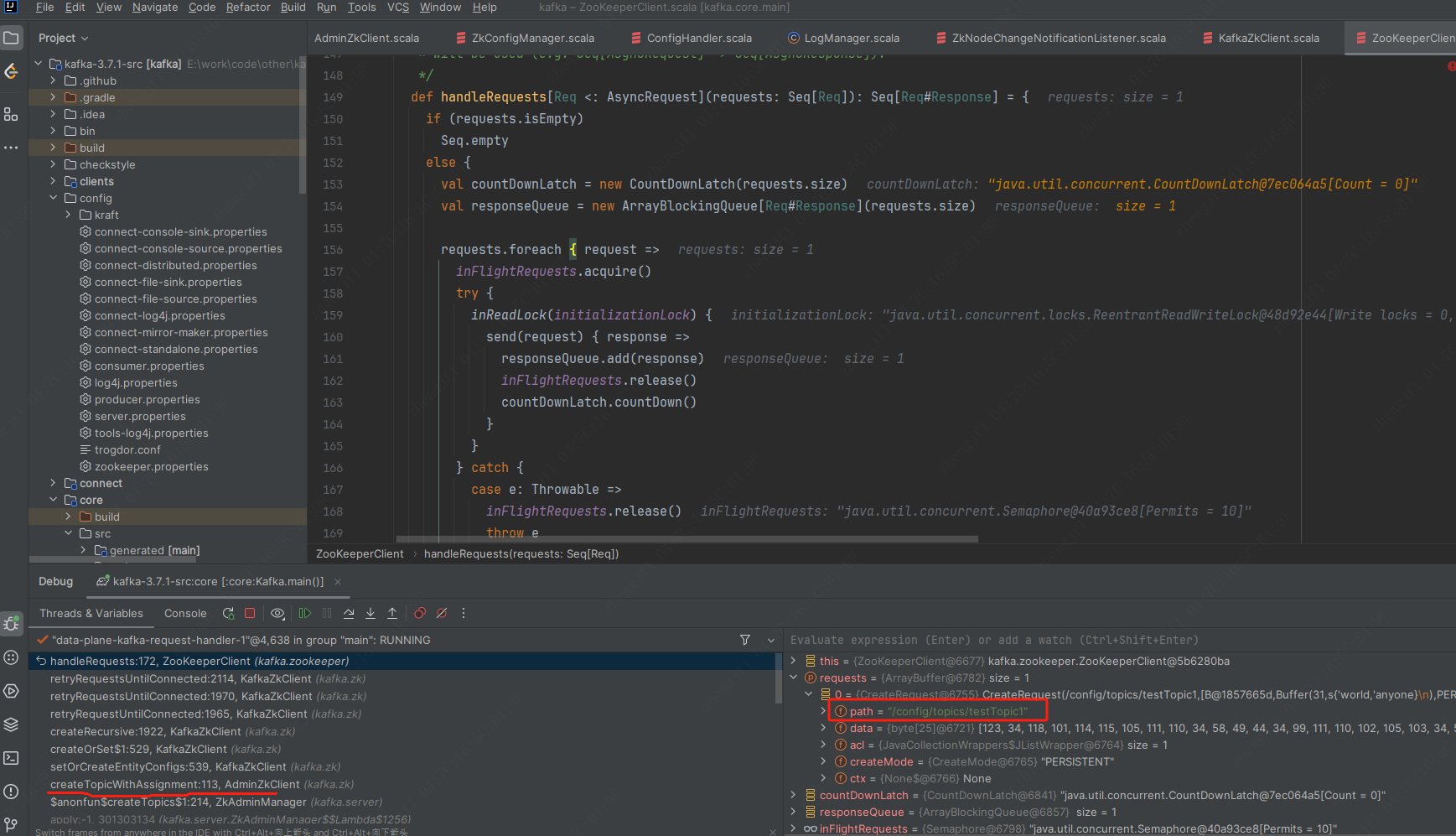
3.写入zk节点后,监听zk的path路径变化的入口都在kafka.controller.KafkaController#process。如果是topic路径变化,进入KafkaController#processTopicChange.比较差集,过滤出删除和新增的topic列表.如果是新增topic,调用kafka.zk.KafkaZkClient#registerZNodeChangeHandler监听新的topic的zk路径变化.进入KafkaController#onNewPartitionCreation。修改partition状态从NewPartition->OnlinePartition,修改replica状态,向controller发送状态变化请求,向副本所属 Broker 发送 leaderAndIsrRequest 请求,向所有 Broker 发送 UPDATE_METADATA 请求。
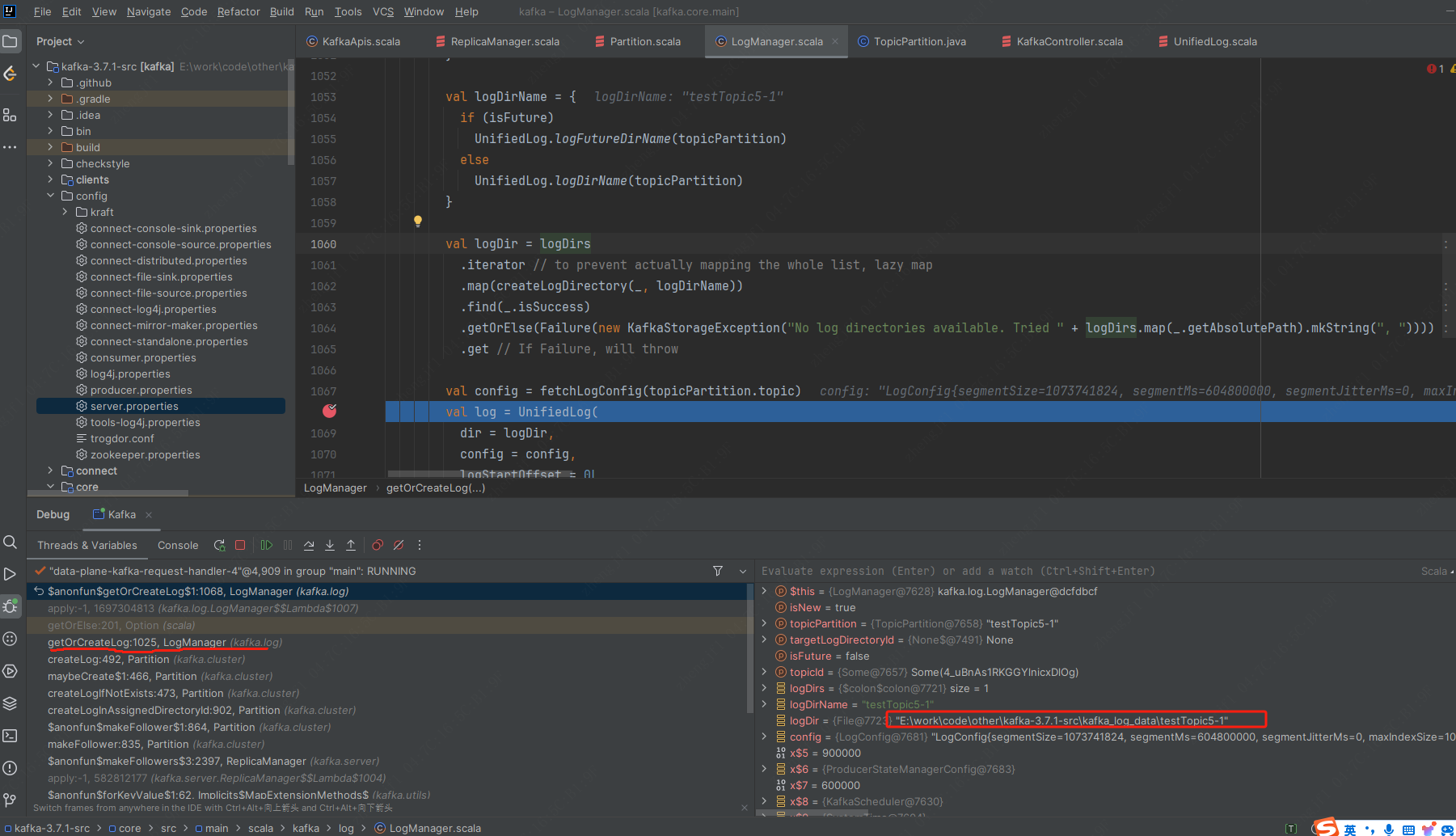
4.处理leaderAndIsrRequest请求,创建topic的log下的目录.进入ReplicaManager#becomeLeaderOrFollower。根据是leader还是follower的partition,分别进入makeLeaders,makeFollowers.如果是leader分区,进入Partition#makeLeader,依次调用Partition#createLogInAssignedDirectoryId->kafka.cluster.Partition#createLog->kafka.log.LogManager#getOrCreateLog创建log目录.如下图:
(二).处理发送端消息.
进入kafka.server.KafkaApis#handleProduceRequest处理发送端消息.先判断topic是否授权,是否存在。方法最后进入ReplicaManager#appendRecords向磁盘中添加记录.写完磁盘后调用sendResponseCallback向生产者返回响应。进入ReplicaManager#appendRecords,先调用ReplicaManager#partitionEntriesForVerification校验partition,然后进入ReplicaManager#appendEntries写磁盘.
1.调用ReplicaManager#appendToLocalLog->Partition#appendRecordsToLeader写入本controller的副本.
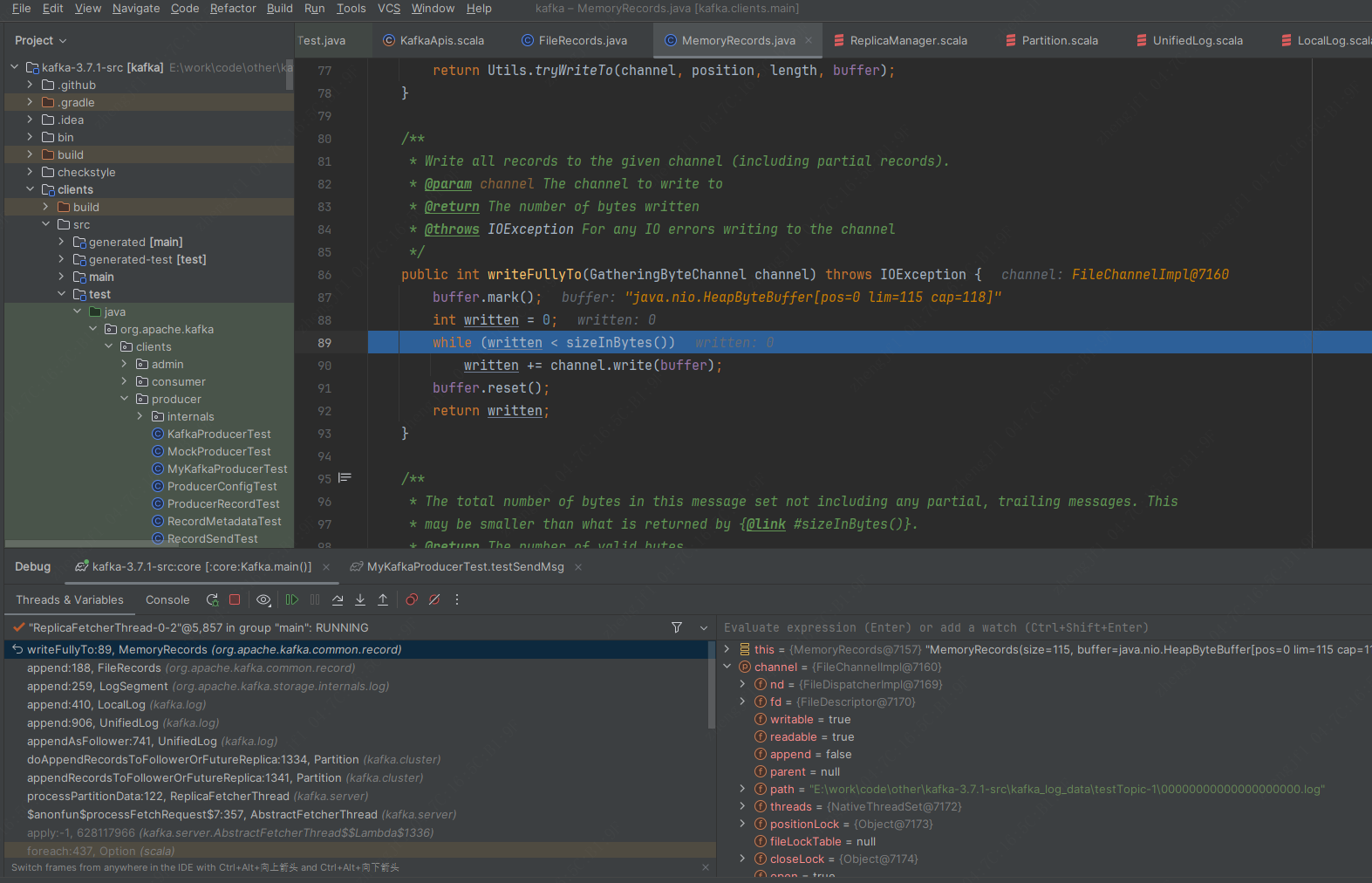
判断ISR的broker数量是否有效.进入UnifiedLog#append,如果log segment已经满了,调用kafka.log.UnifiedLog#maybeRoll刷新到磁盘.如果未满,调用LocalLog#append。在此方法中,调用LogSegment#append->FileRecords#append->java.nio.channels.FileChannel#write()向log中添加数据,使用java.nio.MappedByteBuffer内存映射文件写入index文件.然后调用LocalLog#updateLogEndOffset更新offet.如下图:
2.调用ReplicaManager#addCompletePurgatoryAction.把写入信息写入ReplicaManager#defaultActionQueue队列,其他线程消费队列发给其他副本所在broker.
3.调用ReplicaManager#maybeAddDelayedProduce。取出ReplicaManager#defaultActionQueue队列内容,做一次发送.















 581
581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









