







1、集成学习
1.1、基本概念
所谓集成学习(ensemble learning),即多个机器学习器来完成学习任务。也就是我们常说的"博采众长",它可用于分类问题集成,回归问题集成,特征选取集成,异常点检测集成等,可以说所有机器学习领域都可以看见集成学习的身影。
从下图,我们可以对集成学习思想做一个概括,拿分类来说,对于训练集数据,通过训练若干个个体弱分类器,通过一定的结合策略,就可以最终形成一个强分类器,以达到博采众长的目的。

1.2、常见策略
(1)Bagging(bootstrap aggregation)
booststrap意思是采用重复抽样(有放回)的方法每次从n个原始样本中抽取m个样本;
Bagging是一种根据均匀概率分布从数据集中重复抽样(有放回的)的技术。子训练样本集的大小和原始数据集相同。在构造每一个子分类器的训练样本时,由于是对原始数据集的有放回抽样,因此同一个训练样本集中可能出现多次同一个样本数据。
代表算法:随机森林(RF:Random Forest)
RF流程如下:

(2)Boosting
多个弱学习器根据相应的权重构成一个强学习器。
代表算法:AdaBoost,GBDT和XGBoost。
AdaBoost(adaptive boosting:自适应增强):一种迭代算法,针对同一个训练集训练不同的分类器(弱分类器),然后进行分类,对于分类正确的样本权值低,分类错误的样本权值高(通常是边界附近的样本),最后的分类器是很多弱分类器的线性叠加(加权组合),分类器相当简单。实际上就是一个简单的弱分类算法提升(boost)的过程。
GBDT(Gradient Boosting Decision Tree,梯度提升决策树):
理解:https://github.com/NLP-LOVE/ML-NLP/blob/master/Machine%20Learning/3.2%20GBDT/3.2%20GBDT.md
XGBooste(Xtreme Gradient Boosting,极端梯度提升):在GBDT基础上的改进
1.不断地添加树,不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数f(x),去拟合上次预测的残差。
2.当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数。
3.最后只需要将每棵树对应的分数加起来就是该样本的预测值。
(详见:https://www.cnblogs.com/mantch/p/11164221.html)
2、Boosting算法原理

从图中可以看出,Boosting算法的工作机制是首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目T,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。Boosting系列算法里最著名算法主要有AdaBoost算法和提升树(boosting tree)系列算法。提升树系列算法里面应用最广泛的是梯度提升树(Gradient Boosting Tree)。
Boosting算法是一个串行迭代的过程,关于误差率高的点提高权重的理解,如下表
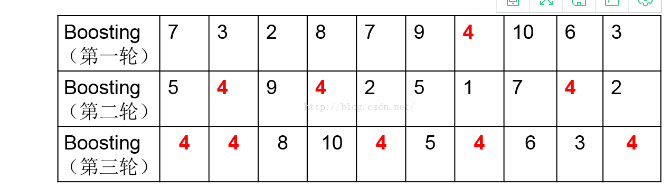
举个例子,有10个样本,开始时简单随机抽样,每个样本被抽到的概率是一样的,都是1/10,然后第一轮结束后用得到的模型对该轮数据集中的样本分类,发现样本4被分错了,就增加它的权值,这样,第二轮抽取的时候4被抽到的概率增加了,第三轮也是一样。这样做,就可以让基分类器聚焦于难被分类的样本4,增加4被正确分类的几率。
3、Boosting和Bagging区别
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成(串行,计算更慢),因为后一个模型参数需要前一轮模型的结果。















 413
413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









