







1 If you rely on your gut feeling and just randomly choose different ways to improve, your problem will easily scale into 6 months or more.
推荐做法是,先用一个模型快速进行工程的实现,然后分析误差的表现(如,绘制学习曲线Learning curves),判断到底是出现了bias问题还是variance问题,最后进行改进。
2 sometimes, getting more training data does not help, why?later will explain.
What can we do to improve the current learning?
1.1 get more training data
1.2 try smaller sets of features/
1.3 get additional feature
1.4 adding polynomial features
1.5 increase λ
1.6 decrease λ
Machine Learning Diagnostic
evaluate your hypothesis
1.1 training(70% dataset)+test(30% dataset)
1.2 misclassification error rate

Model Selection Process如何挑选合适的模型假设
1可能存在的问题

2 如何划分数据集以方便选择合适模型
step1

step2

Consider the model selection procedure where we choose the degree of polynomial using a cross validation set. For the final model (with parameters θ), we might generally expect Jcv(θ) To be lower than Jtest(θ) because: An extra parameter (d, the degree of the polynomial) has been fit to the cross validation set.
上面的过程理论可行,但是有一定局限性。
假设现在已经计算了上述的1~10的Jcv(θ),假设d=4时生成了最小的Jcv(θ)。这只能说明在1~10的范围中,d=4是最优的。这不能说明d>10一定比d=4表现差。
所以应该描绘一个Jcv(θ)和d的函数才能看到Jcv(θ)随d变化的趋势。才知道应该选择怎样的d。选择其它参数时思路也类似。
如何选出合适的d(x的几次)
先理解问题
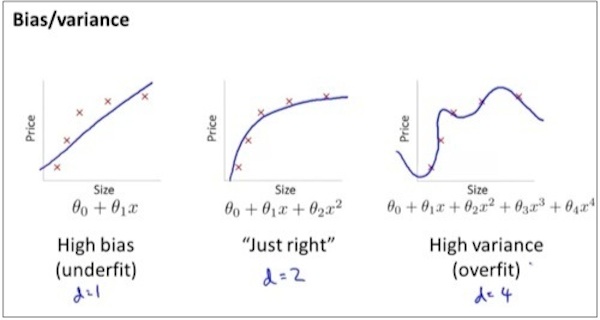
再观察规律
粉色曲线:随着x的degree幂的增大,逐渐从under fitting变化为了just right再到overfitting,所以对于training set而言,error逐渐降低。
红色曲线: 对于Cross Validation set而言,error先降低后增加。
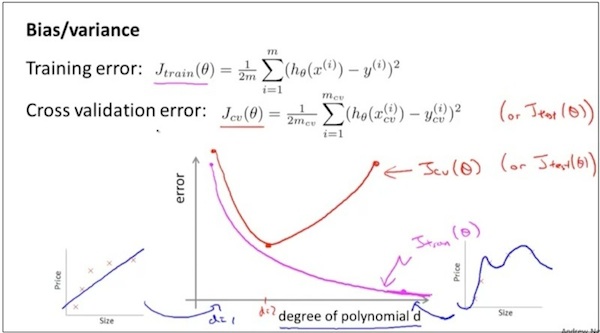
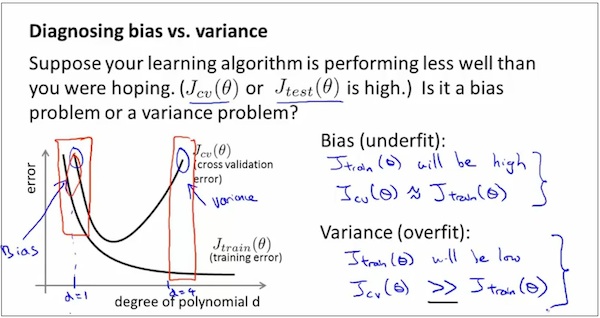
观察下图。可以得出bias和variance的区分办法
如果J_training(θ)高, J_cross_validation(θ)高,则是bias
如果J_training(θ)低, J_cross_validation(θ)高,则是variance
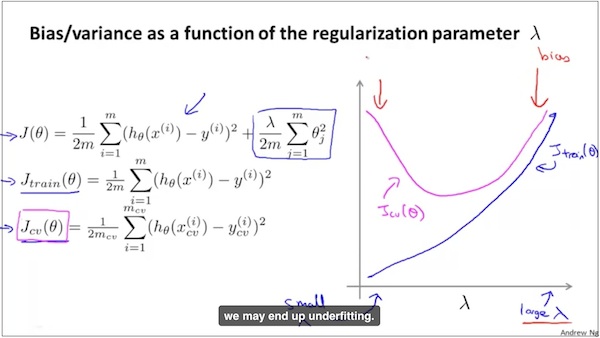
如何选出合适的regulation参数λ
思路和上面相同,如下图

如何使用学习曲线Learning Curves来判断是否出现bias问题或者variance问题
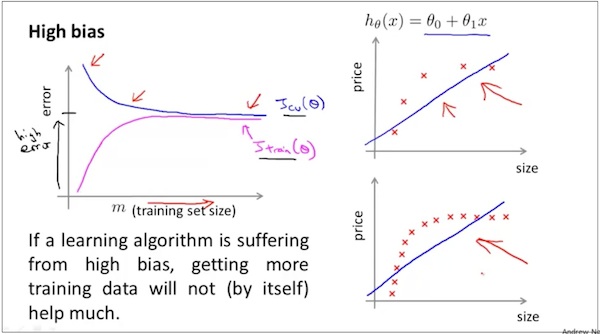
假设有high bias,学习曲线如下,
You can see both the training and test sets have poor performance, which suggests a high bias problem.
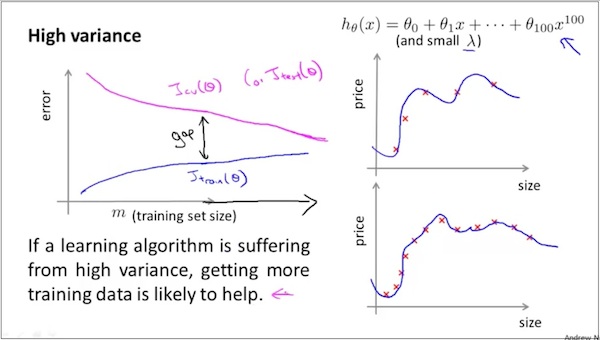
假设有high variance学习曲线如下,
You can see a large gap, indicating that cross validation error is much larger than training error and Algorithm is suffering from high variance.
一些常见的调参场景

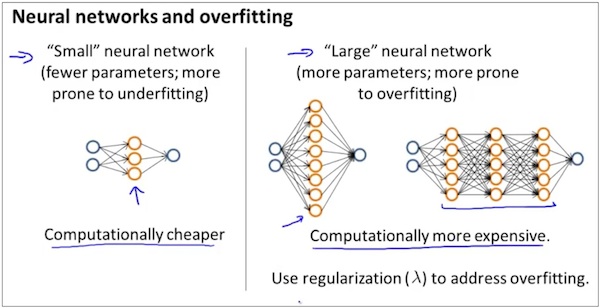
NN中的常见问题场景和解决办法















 756
756

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









