







作者|ARAVIND PAI 编译|VK 来源|Analytics Vidhya
概述
标识化是处理文本数据的一个关键
我们将讨论标识化的各种细微差别,包括如何处理词汇表外单词(OOV)
介绍
从零开始掌握一门新的语言令人望而生畏。如果你曾经学过一种不是你母语的语言,你就会理解!有太多的层次需要考虑,例如语法需要考虑。这是一个相当大的挑战。
为了让我们的计算机理解任何文本,我们需要用机器能够理解的方式把这个词分解。这就是自然语言处理(NLP)中标识化的概念。
简单地说,标识化(Tokenization)对于处理文本数据十分重要。

下面是关于标识化的有趣的事情,它不仅仅是分解文本。标识化在处理文本数据中起着重要的作用。因此,在本文中,我们将探讨自然语言处理中的标识化,以及如何在Python中实现它。
目录
标识化
标识化背后的真正原因
我们应该使用哪种(单词、字符或子单词)?
在Python中实现Byte Pair编码
标识化
标识化(Tokenization)是自然语言处理(NLP)中的一项常见任务。这是传统NLP方法(如Count Vectorizer)和高级的基于深度学习的体系结构(如Transformers)的基本步骤。
单词是自然语言的组成部分。
标识化是一种将文本分割成称为标识的较小单元的方法。在这里,标识可以是单词、字符或子单词。因此,标识化可以大致分为三种类型:单词、字符和子单词(n-gram字符)标识化。
例如,想想这句话:“Never give up”。
最常见的词的形成方式是基于空间。假设空格作为分隔符,句子的标识化会产生3个词,Never-give-up。由于每个标识都是一个单词,因此它成为单词标识化的一个示例。
类似地,标识(token)可以是字符或子单词。例如,让我们考虑smarter”:
字符标识:s-m-a-r-t-e-r
子单词(subword)标识:smart-er
但这有必要吗?我们真的需要标识化来完成这一切吗?
标识化背后的真正原因
由于词语是自然语言的构建块,所以处理原始文本的最常见方式发生在单词级别。
例如,基于Transformer的模型(NLP中的最新(SOTA)深度学习架构)在单词级别处理原始文本。类似地,对于NLP最流行的深度学习架构,如RNN、GRU和LSTM,也在单词级别处理原始文本。
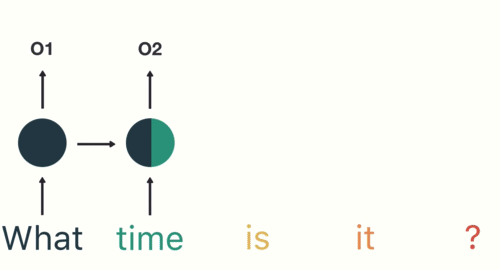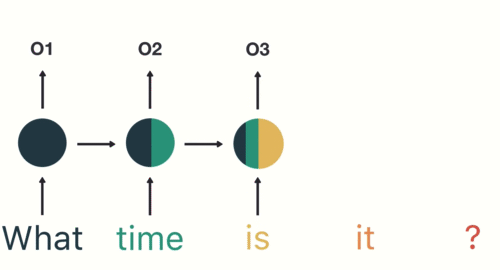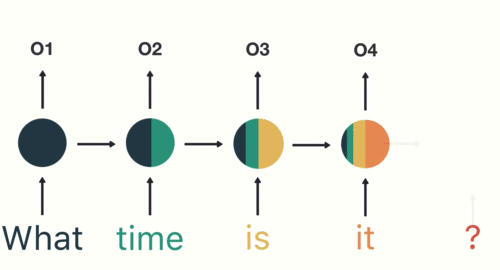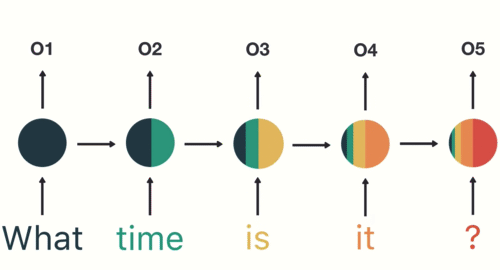
如图所示,RNN在特定的时间步接收和处理每个单词。
因此,标识化是文本数据建模的首要步骤。对语料库执行标识化以获取单词。然后使用以下单词准备词汇表。词汇是指语料库中出现过的单词。请记住,词汇表可以通过考虑语料库中每个唯一的单词或考虑前K个频繁出现的单词来构建。
创建词汇表是标识化的最终目标。
提高NLP模型性能的一个最简单的技巧是使用top K的单词创建一个词汇表。
现在,让我们了解一下词汇在传统的和高级的基于深度学习的NLP方法中的用法。
传统的NLP方法如单词频率计数和TF-IDF使用词汇作为特征。词汇表中的每个单词都被视为一个独特的特征:
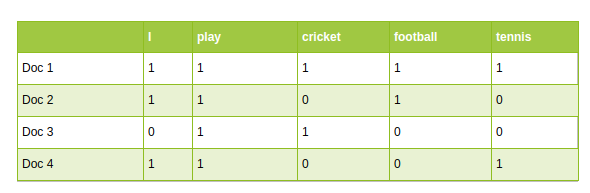
在基于深度学习的高级NLP体系结构中,词汇表用于创建输入语
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









