




 本文详细介绍了Pandas库中20个常用且实用的函数,包括query、insert、cumsum、sample等,通过示例展示了如何使用这些函数进行数据过滤、添加新列、计算累计和、随机采样、条件替换等操作,旨在提升数据分析效率。
本文详细介绍了Pandas库中20个常用且实用的函数,包括query、insert、cumsum、sample等,通过示例展示了如何使用这些函数进行数据过滤、添加新列、计算累计和、随机采样、条件替换等操作,旨在提升数据分析效率。
作者|Soner Yıldırım 编译|VK 来源|Towards Data Science
Pandas是一个python数据分析库。它提供了许多函数和方法来加快数据分析过程。pandas之所以如此普遍,是因为它具有强大的功能,以及他简单的语法和灵活性。
在这篇文章中,我将举例来解释20个常用的pandas函数。有些是很常见的,我敢肯定你以前用过。有些对你来说可能是新的。所有函数都将为你的数据分析过程增加价值。
import numpy as np
import pandas as pd1.query
我们有时需要根据条件过滤一个数据帧。过滤数据帧的一个简单方法是query函数。让我们首先创建一个示例数据帧。
values_1 = np.random.randint(10, size=10)
values_2 = np.random.randint(10, size=10)
years = np.arange(2010,2020)
groups = ['A','A','B','A','B','B','C','A','C','C']
df = pd.DataFrame({'group':groups, 'year':years, 'value_1':values_1, 'value_2':values_2})
df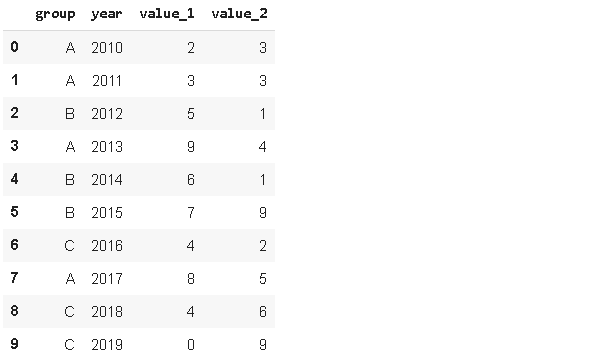
使用查询函数非常简单,只需要编写过滤条件。
df.query('value_1 < value_2')
2.insert
当我们想向dataframe添加一个新列时,默认情况下会在末尾添加它。但是,pandas提供了使用insert函数使得我们可以在任何位置添加新列。
我们需要通过传递索引作为第一个参数来指定位置。此值必须是整数。列索引从零开始,就像行索引一样。第二个参数是列名,第三个参数是对象,这些对象可以是Series 或数组。
#新建列
new_col = np.random.randn(10)
#在位置2插入新列
df.insert(2, 'new_col', new_col)
df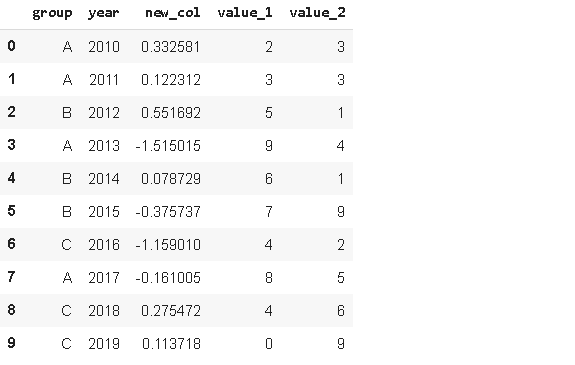
3.Cumsum
数据帧包含3个不同组的年份值。我们可能只对某些情况下的累积值感兴趣。Pandas提供了一个易于使用的函数来计算累计和,即cumsum。
如果我们只应用cumsum函数,group里的(A,B,C)将被忽略,因为我们无法区分不同的组。我们可以应用groupby和cumsum函数,这样就可以区分出不同的组。
df['cumsum_2'] = df[['value_2','group']].groupby('group').cumsum()
df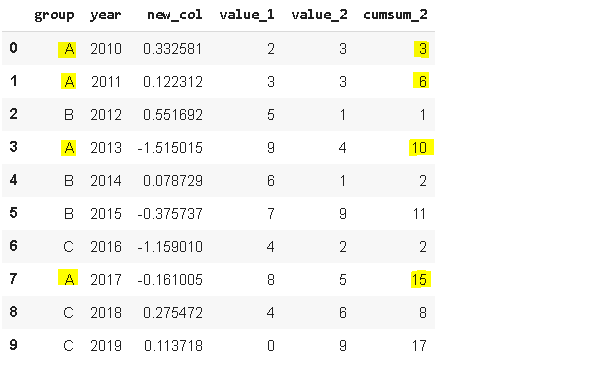
4.Sample
Sample方法允许你从序列或数据帧中随机选择值。当我们想从一个分布中选择一个随机样本时,它很有用。
sample1 = df.sample(n=3)
sample1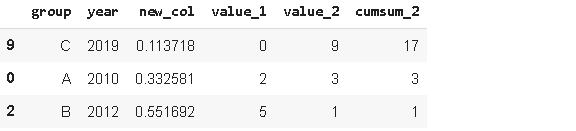
我们用n参数指定值的数目,但我们也可以将比率传递给frac
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









