







作者|LAKSHAY ARORA 编译|VK 来源|Analytics Vidhya
概述
流数据是机器学习领域的一个新兴概念
学习如何使用机器学习模型(如logistic回归)使用PySpark对流数据进行预测
我们将介绍流数据和Spark流的基础知识,然后深入到实现部分
介绍
想象一下,每秒有超过8500条微博被发送,900多张照片被上传到Instagram上,超过4200个Skype电话被打,超过78000个谷歌搜索发生,超过200万封电子邮件被发送(根据互联网实时统计)。
我们正在以前所未有的速度和规模生成数据。在数据科学领域工作真是太好了!但是,随着大量数据的出现,同样面临着复杂的挑战。
主要是,我们如何收集这种规模的数据?我们如何确保我们的机器学习管道在数据生成和收集后继续产生结果?这些都是业界面临的重大挑战,也是为什么流式数据的概念在各组织中越来越受到重视的原因。

增加处理流式数据的能力将大大提高你当前的数据科学能力。这是业界急需的技能,如果你能掌握它,它将帮助你获得下一个数据科学的角色。
因此,在本文中,我们将了解什么是流数据,了解Spark流的基本原理,然后研究一个与行业相关的数据集,以使用Spark实现流数据。
目录
什么是流数据?
Spark流基础
离散流
缓存
检查点
流数据中的共享变量
累加器变量
广播变量
利用PySpark对流数据进行情感分析
什么是流数据?
我们看到了上面的社交媒体数据——我们正在处理的数据令人难以置信。你能想象存储所有这些数据需要什么吗?这是一个复杂的过程!因此,在我们深入讨论本文的Spark方面之前,让我们花点时间了解流式数据到底是什么。
流数据没有离散的开始或结束。这些数据是每秒从数千个数据源生成的,需要尽快进行处理和分析。相当多的流数据需要实时处理,比如Google搜索结果。
我们知道,一些结论在事件发生后更具价值,它们往往会随着时间而失去价值。举个体育赛事的例子——我们希望看到即时分析、即时统计得出的结论,以便在那一刻真正享受比赛,对吧?
Spark流基础
Spark流是Spark API的扩展,它支持对实时数据流进行可伸缩和容错的流处理。
在跳到实现部分之前,让我们先了解Spark流的不同组件。
离散流
离散流或数据流代表一个连续的数据流。这里,数据流要么直接从任何源接收,要么在我们对原始数据做了一些处理之后接收。
构建流应用程序的第一步是定义我们从数据源收集数据的批处理时间。如果批处理时间为2秒,则数据将每2秒收集一次并存储在RDD中。而这些RDD的连续序列链是一个不可变的离散流,Spark可以将其作为一个分布式数据集使用。
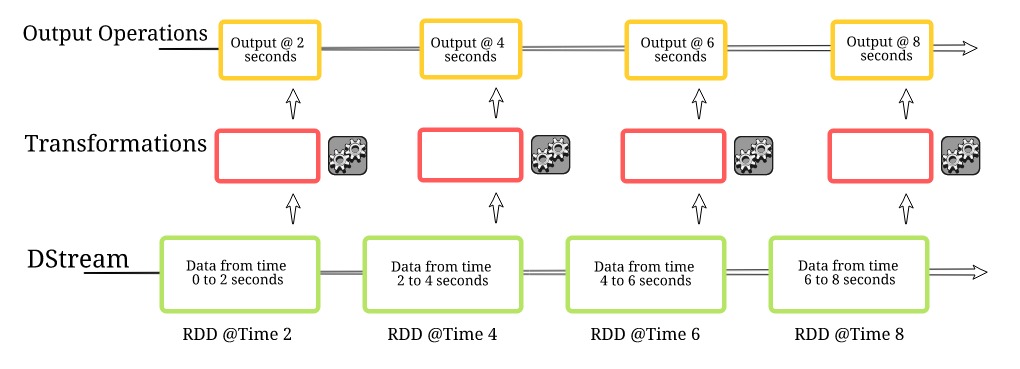
想想一个典型的数据科学项目。在数据预处理阶段,我们需要对变量进行转换,包括将分类变量转换为数值变量、删除异常值等。Spark维护我们在任何数据上定义的所有转换的历史。因此,无论何时发生任何错误,它都可以追溯转换的路径并重新生成计算结果。
我们希望Spark应用程序运行24小时 x 7,并且无
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3189
3189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









