







 作者受网易云课堂课程启发,尝试用Python爬取新疆伊犁景点数据进行综合评价以定制行程。先确定爬取区域,再爬取景点内容,接着用pandas工具清洗整理数据,进行综合评分,还爬取景点其他情况,最后通过Excel实现空间可视化,得出大致行程。
作者受网易云课堂课程启发,尝试用Python爬取新疆伊犁景点数据进行综合评价以定制行程。先确定爬取区域,再爬取景点内容,接着用pandas工具清洗整理数据,进行综合评分,还爬取景点其他情况,最后通过Excel实现空间可视化,得出大致行程。
写在开头
六月的新疆美如天境,一直想去自驾游,在网易云课堂看到城市数据团大鹏老师讲的《用数据做攻略:找到一个城市最有趣的地方》传送门,于是尝试用python爬取景点数据,进行综合评价,然后看哪些地方值得去玩。
下面看新疆伊犁篇
评价思路
STEP1. 确定要去的区域,获得去哪儿网景点评价的网页地址
STEP2. 通过爬虫爬取网页数据,把感兴趣的数据爬取下来
STEP3. 通过pandas工具对数据进行清洗整理,转换格式
STEP4. 进行综合评价,得出排名
STEP5. 进行空间落位,筛选出想去的地方,定制行程
网页爬取需要requests,BeautifulSoup,数据整理需要pandas,numpy,表格需要matplotlib
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
1、首先确定爬取区域
预计行程从乌鲁木齐出入,行程没出来前就知道特克斯八卦城必去,伊犁六月的薰衣草必去,那大致区域就锁定在伊犁哈萨克自治州,6-10月是伊犁最佳旅游季节。此时伊犁气候温润,日照充足,百花织锦,瓜果飘香,特别适合摄影及观光游览。
点击景点,能看到伊犁包含的所有景点有24页之多,点击后几页看网页地址链接就能看到基本规律了,所以形成获取网页地址的 函数如下:
#创建函数,获取页面连接
def get_urls(ui,n): #ui:地址,n:页码数
urllst = []
for i in range(1,n+1):
urllst.append(ui+str(i))
return urllst
#采集景点前5页
urls = get_urls('https://travel.qunar.com/p-cs299845-yili-jingdian-1-',5)
urls #看看结果
预计采集5页景点,每页10个,50个景点已经差不多够用了,也不可能去太多地方,太小的景点也不太感兴趣,如有需要可以自行修改n数值。结果是一个列表如下:
[‘https://travel.qunar.com/p-cs299845-yili-jingdian-1-1’,
‘https://travel.qunar.com/p-cs299845-yili-jingdian-1-2’,
‘https://travel.qunar.com/p-cs299845-yili-jingdian-1-3’,
‘https://travel.qunar.com/p-cs299845-yili-jingdian-1-4’,
‘https://travel.qunar.com/p-cs299845-yili-jingdian-1-5’]
2、爬取景点内容
通过网页代码查看(360浏览器按F12,需要有一点HTML的基础),能发现所有的景点都在 <ul class=“list_item clrfix”> 结构之下,所以是先将所有景点的<li>结构爬取出来,再通过for循环查找需要的信息。
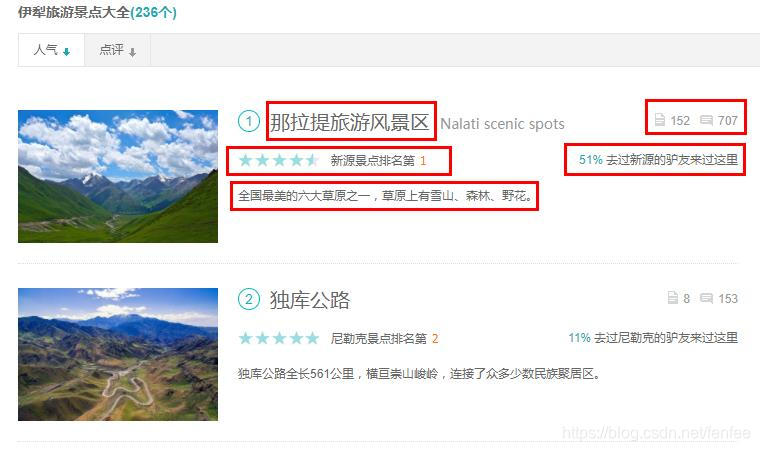
景点里我们需要位置坐标、景点名称、攻略提到数量、点评数量、景点排名、驴友去过的比例、景点星级、景点描述,我这里收集的内容比视频教程里更多,另外我还收集了每个景点的具体链接,因为我还需要知道每个景点的具体信息,比如门票价格、联系电话等
一个地址对应一页数据,每页有10个景点,先实现一页数据的采集
#每一页数据采集函数
def get_data(u): #u:网址
r = requests.get(u)
soup = BeautifulSoup(r.text, 'lxml')
infor = soup.find('ul',class_ = "list_item clrfix").find_all('li') #所有景点的数据块
data_jd = [] #基本信息列表
data_link = [] #景点链接列表
for i in infor: #查找需要的景点信息
dic = {} #基本信息存放
dic_link = {} #链接地址存放
dic['lat'] = i['data-lat'] #坐标,可以进行空间可视化分析
dic['lng'] = i['data-lng']
dic['景点名称'] = i.find('span', class_="cn_tit").text #一个.find().text就能提取里面的文字
dic['攻略提到数量'] = i.find('div', class_="strategy_sum").text
dic['点评数量'] = i.find('div', class_="comment_sum").text
dic['景点排名'] = i.find('span', class_="ranking_sum").text
dic['驴友去过'] = i.find('span', class_="sum").text
‘‘‘
<span style="width:90%" class="cur_star">这里的星级信息是在style的值里的,
再通过.split(':')[1]取得其中的90%,再用.split('%')[0]取得90这个字符
’’’
dic['星级'] = i.find('span', class_="cur_star")['style'].split(':')[1].split('%')[0]
dic['描述'] = i.find('div', class_="desbox").text
dic_link['景点名称'] = dic['景点名称'] #链接需要景点名称和地址
dic_link['链接'] = i.find('a')['href'] #地址是在href的值里
data_jd.append(dic) #形每页内容添加至列表
data_link.append(dic_link) #形每页内容添加至列表
return data_jd,data_link #返回了两个列表
#看看结果
print(get_data(urls[0])[0][:2]) #只用第一个链接,返回列表里的第一个列表就是基本内容的列表,看前两个结果
print(get_data(urls[0])[1][:2]) #只用第一个链接,返回列表里的第二个列表就是链接内容的列表,看前两个结果
结果如下,第一个列表里面每个景点成一个字典,包含景点的基本信息,第二个列表里每个景点一个字典,包含名称和链接:
[{‘lat’: ‘43.298696’, ‘lng’: ‘84.235376’, ‘景点名称’: ‘那拉提旅游风景区Nalati scenic spots’, ‘攻略提到数量’: ‘152’, ‘点评数量’: ‘707’, ‘景点排名’: ‘新源景点排名第1’, ‘驴友去过’: ‘51%’, ‘星级’: ‘90’, ‘描述’: ‘全国最美的六大草原之一,草原上有雪山、森林、野花。’}, {‘lat’: ‘43.657906’, ‘lng’: ‘84.365572’, ‘景点名称’: ‘独库公路’, ‘攻略提到数量’: ‘8’, ‘点评数量’: ‘153’, ‘景点排名’: ‘尼勒克景点排名第2’, ‘驴友去过’: ‘11%’, ‘星级’: ‘98’, ‘描述’: ‘独库公路全长561公里,横亘崇山峻岭,连接了众多少数民族聚居区。’}]
[{‘景点名称’: ‘那拉提旅游风景区Nalati scenic spots’, ‘链接’: ‘https://travel.qunar.com/p-oi711647-neilatilu:youfengjing’}, {‘景点名称’: ‘独库公路’, ‘链接’: ‘https://travel.qunar.com/p-oi9535135-dukugonglu’}]
接下通过每页数据采集来把所有数据爬取下来
#采集数据并载入DataFrame
data_jd = []
data_link = []
for i in urls:
data_jd.extend(get_data(i)[0])
data_link.extend(get_data(i)[1])
print('成功采集%i个景点数据' % len(data_jd))
df = pd.DataFrame(data_jd) #导入pandas的DataFrame,类似excel表格
df.index = df['景点名称'] #将表头换成景点名称
del df['景点名称'] #删除景点名称一列
df #看下结果,可用df.head()看前5行,看几行括号里写几
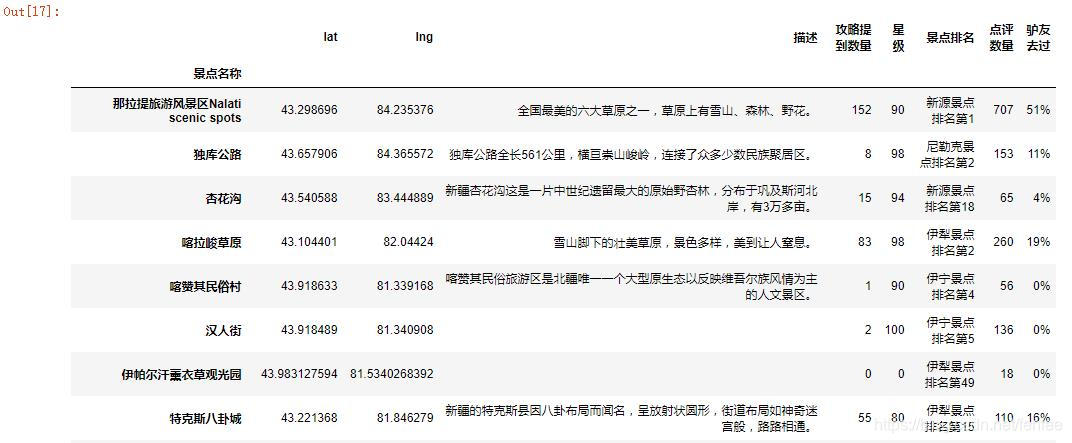
3、数据清洗和整理
可以看到有些小景点没有描述,没有人去过,甚至会没有数据,这里由于数据量不大,我们只对数据进行整理补齐,不影响计算就行,最后通过综合打分排名就能得到我们需要的景点信息
另外注意表格里的数据看着是数字,其实都是字符串,这里要进行转换才能进行计算。
#数据字符转数字,以计算处理
df['lng'] = df['lng'].astype(np.float) #转浮点数
df['lat'] = df['lat'].astype(np.float)
df['点评数量'] = df['点评数量'].astype(np.int) #转整数
df['攻略提到数量'] = df['攻略提到数量'].astype(np.int)
df['驴友去过'] = df['驴友去过'].str.split('%').str[0].astype(np.int) #在pd里字符串有个.str的表达式需要写
df['星级'] = df['星级'].astype(np.int)
df.fillna(value = 0,inplace = True) #填充空值,如果列是lnt类型就0;如果是str就用nan
4、景点热门程度综合评分
这里每种数据跟景点的热门程度都是正相关的,所以将(数值 - 最小值)/ (最大值 - 最小值)*100得到一个1-100的标准评分,这样把’攻略提到数量’,‘星级’,'点评数量’都调整为了1-100的评分,驴友去过的比例,去掉%也是一个1-100的数值,所以景点热门程度就以各部分分值之和作为综合得分,如有需要也可以根据喜好给各项添加影响系数来进行评价。
这里也存在一个情况,某个景点差评特别多,也会导致得分相对较高,但也说明了景点热门,需要再从其他角度去了解一下。
# 构建函数实现字段标准化,标准分
def nordata(dfi,*cols):
for col in cols:
dfi[col + '_b'] = round((dfi[col] - dfi[col].min())/(dfi[col].max() - dfi[col].min())*100,2)
nordata(df,'攻略提到数量','星级','点评数量')
#由驴友去过比例得分+攻略提到数量得分+星级得分+点评数得分,每项均为0-100分
df['综合得分'] = df['驴友去过']+df['攻略提到数量_b']+df['星级_b']+df['点评数量_b']
#以综合得分排名,只需要前30名的名单
top30_data = df.sort_values(by = '综合得分', ascending=False).iloc[:30]
top30 = top30_data.copy() #为了列表好看,原始数据拷贝了一份来整理,pandas的数据修改了,原始数据就修改了
del top30['攻略提到数量_b']
del top30['点评数量_b']
del top30['星级_b']
# top30.to_excel('F://top30.xlsx') 可以到出至EXCEL
top30
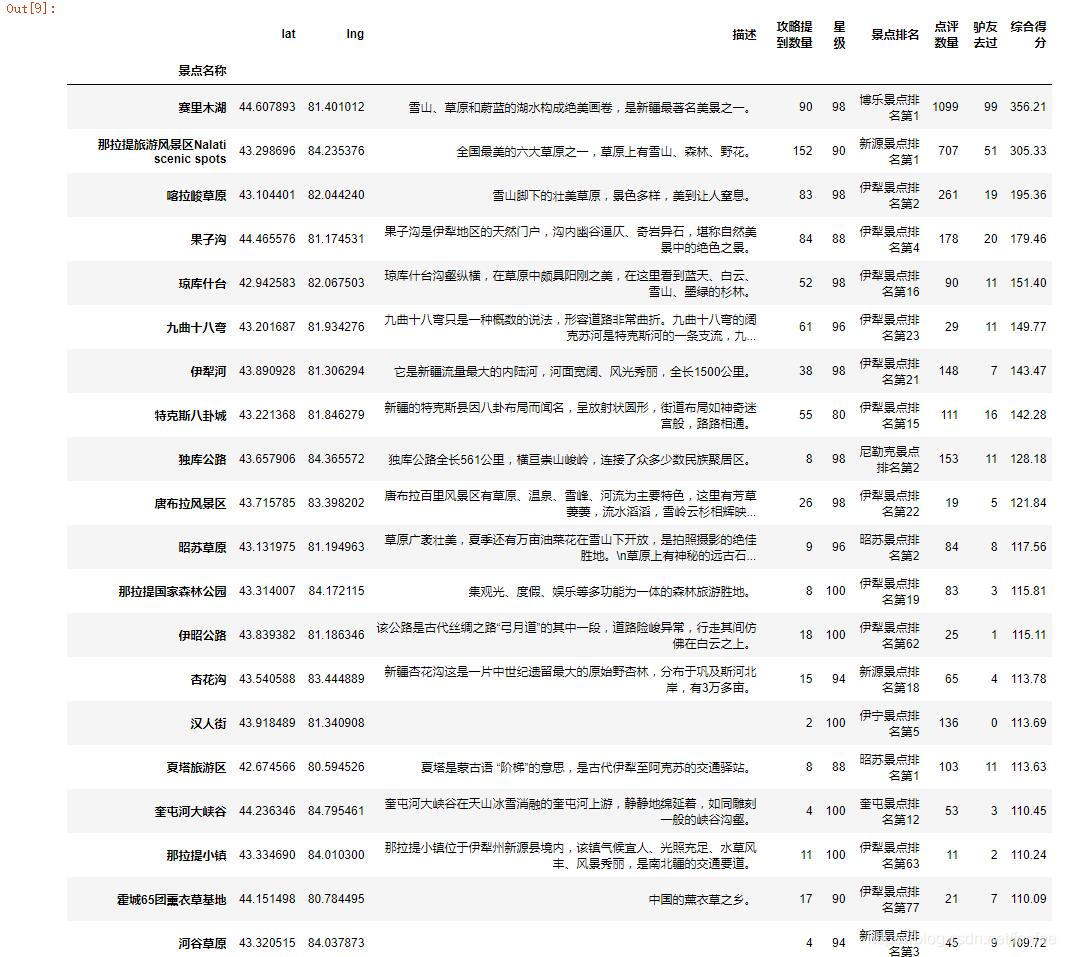
这是前20的截图,综合考虑门票、交通、住宿等其他景点情况,基本上要去的也都在这前20个景点里面。
5、景点其他情况爬取
由于每个景点的情况各不相同,每个景点的数据也有很大差异,很多景点不存在开发时间,门票价格之类的,所以增加了不少判断语句防止报错。
#建立景点详情页面爬取函数
def jd_data(name,u): #u:网址
r = requests.get(u)
soup = BeautifulSoup(r.text, 'lxml')
dic_jd = {}
dic_jd['景点名称'] = name
dic_jd['开放时间'] = soup.find('td',class_ = "td_r")
if dic_jd['开放时间'] is None: #判断空值,防止出错
dic_jd['开放时间'] = '无'
else:
dic_jd['开放时间'] = dic_jd['开放时间'].find('p').text
dic_jd['门票价格'] = soup.find('div',class_ = "b_detail_section b_detail_ticket")
if dic_jd['门票价格'] is None: #判断空值,防止出错
dic_jd['门票价格'] = '无'
else:
dic_jd['门票价格'] = dic_jd['门票价格'].find('div',class_ = "e_db_content_box e_db_content_dont_indent").text
dic_jd['旅游时节'] = soup.find('div',class_ = "b_detail_section b_detail_travelseason")
if dic_jd['旅游时节'] is None: #判断空值,防止出错
dic_jd['旅游时节'] = '全年'
else:
dic_jd['旅游时节'] = dic_jd['旅游时节'].find('div',class_ ='e_db_content_box e_db_content_dont_indent').text
dic_jd['其他'] = soup.find('td',class_ = "td_l")
if dic_jd['其他'] is None: #判断空值,防止出错
dic_jd['其他'] = '无'
else:
dic_jd['其他'] = dic_jd['其他'].text
return dic_jd
#将景点名称与链接关联形成字典
df_link = {}
for i in data_link:
df_link[i['景点名称']] = i['链接']
detailed_data = []
for key in top30_data.index: #我们只需要前30的详细信息,从前30里读取景点名称
#key = '杏花沟'
#print (key,' ok') #检查景点
detailed_data.append(jd_data(key,df_link[key])) #导入景点名称和网页链接
detailed_df = pd.DataFrame(detailed_data) #转换成DataFrame
detailed_df.index = detailed_df['景点名称']
del detailed_df['景点名称']
detailed_df
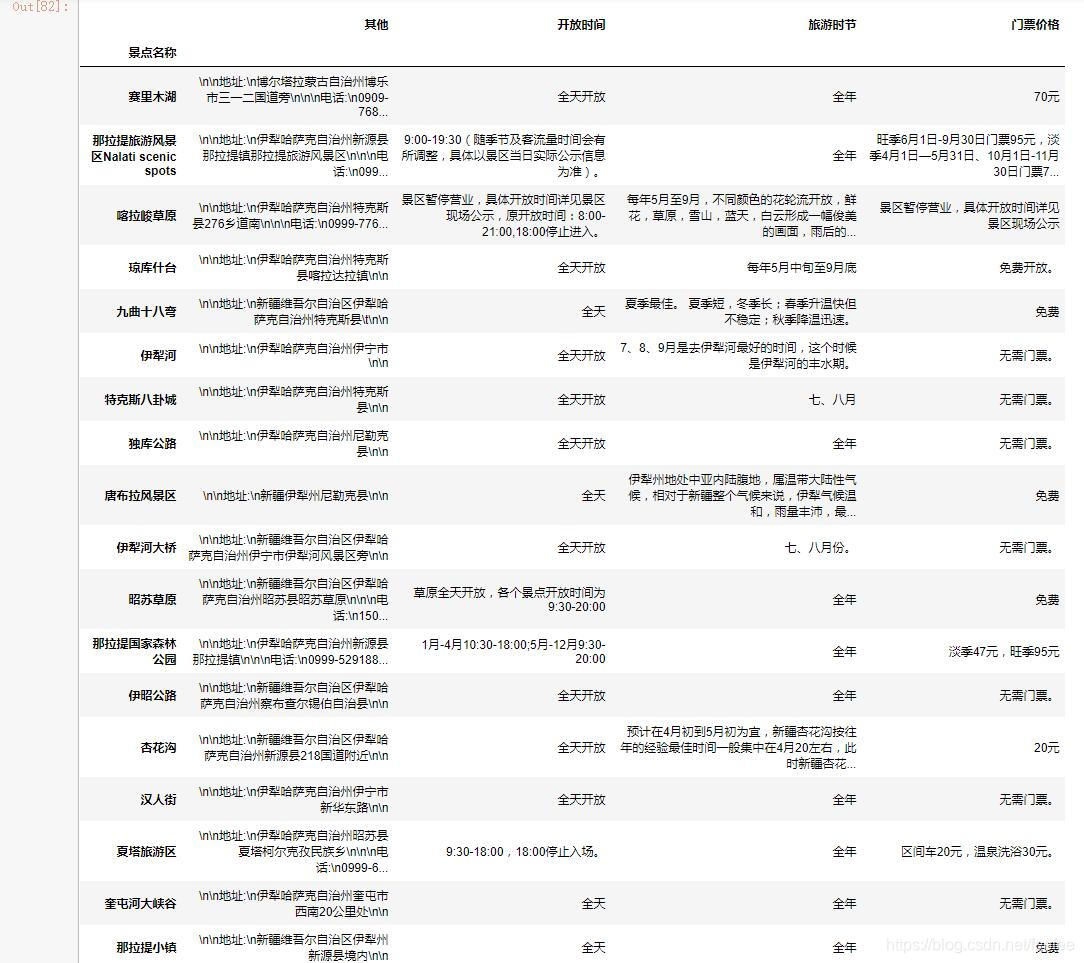
这样就基本上获取了主要景点的信息,在这里挑选要去的景点,当然可以通过空间可视化来更方便的观察分布,制定合理的行程。
6、景点情况空间可视
将之前导出的数据在2016版Excel里可以空间可视化,具体实现办法可以自行百度。
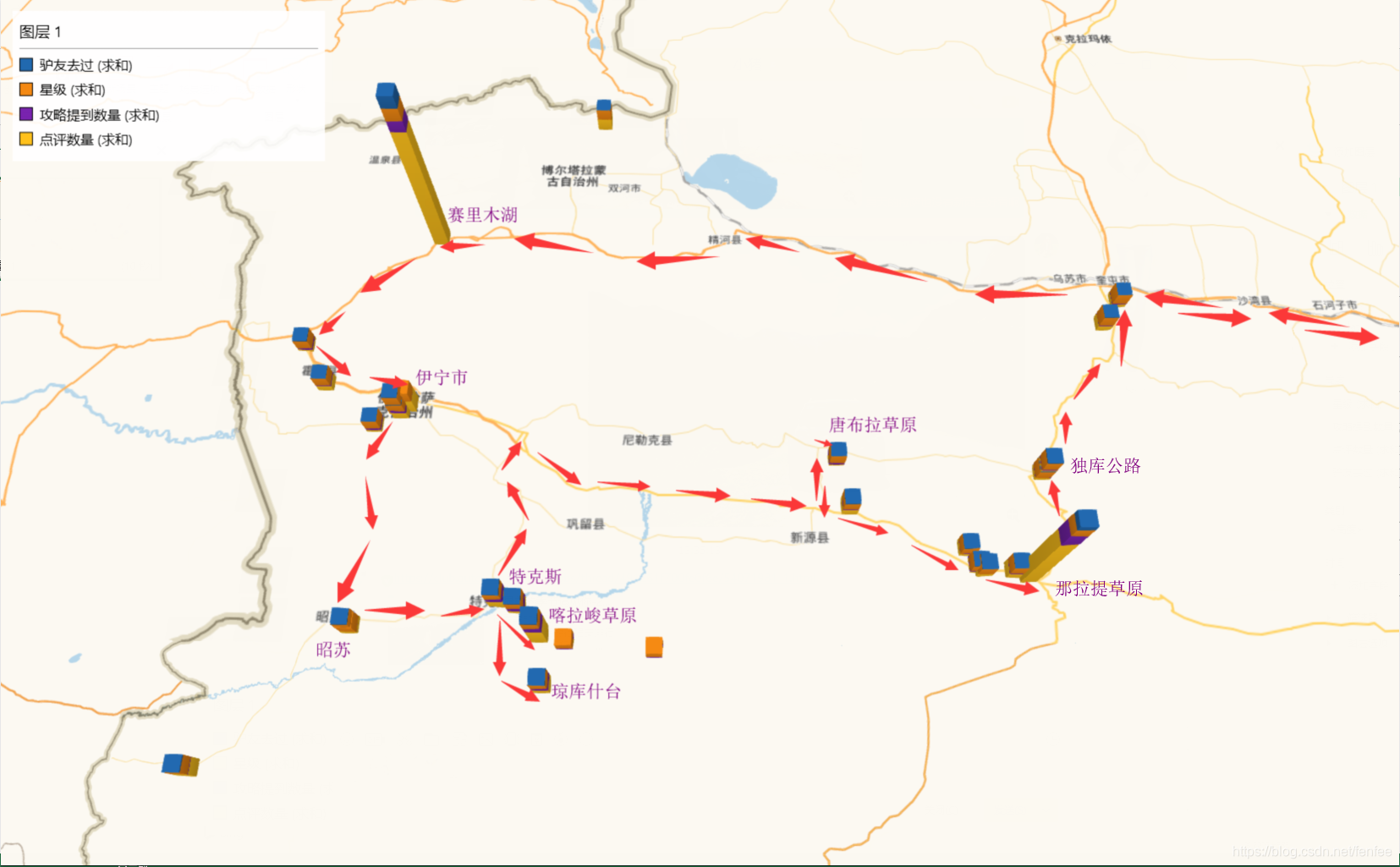
大致线路就已经出来了,乌鲁木齐 >>奎屯>>赛里木湖>>薰衣草>>霍城县>>伊宁市>>伊昭公路>>昭苏>>特克斯<>喀拉峻草原<>琼库什台>>新源县>>唐布拉草原>>那拉提草原>>独库公路>>奎屯>>乌鲁木齐,基本包含主要景点。
完整代码
后来发现赛里木湖在必经之路上,但是不属于伊犁地区,属于伊犁北侧的博乐市,于是额外加了一页博乐的景点链接,包含有赛里木湖。
完整代码以供参考:
import requests
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#创建函数,获取页面连接
def get_urls(ui,n): #ui:地址,n:页码数
urllst = []
for i in range(1,n+1):
urllst.append(ui+str(i))
return urllst
#采集景点前5页
urls = get_urls('https://travel.qunar.com/p-cs299845-yili-jingdian-1-',5)
u_bl = 'https://travel.qunar.com/p-cs297544-bole-jingdian'
urls.append(u_bl) #添加了赛里木湖
#网页数据采集函数
def get_data(u): #u:网址
r = requests.get(u)
soup = BeautifulSoup(r.text, 'lxml')
infor = soup.find('ul',class_ = "list_item clrfix").find_all('li')
data_jd = []
data_link = []
for i in infor: #数据结构化
dic = {}
dic_link = {}
dic['lat'] = i['data-lat']
dic['lng'] = i['data-lng']
dic['景点名称'] = i.find('span', class_="cn_tit").text
dic['攻略提到数量'] = i.find('div', class_="strategy_sum").text
dic['点评数量'] = i.find('div', class_="comment_sum").text
dic['景点排名'] = i.find('span', class_="ranking_sum").text#split('第')[1]
dic['驴友去过'] = i.find('span', class_="sum").text
dic['星级'] = i.find('span', class_="cur_star")['style'].split(':')[1].split('%')[0]
dic['描述'] = i.find('div', class_="desbox").text
dic_link['景点名称'] = dic['景点名称']
dic_link['链接'] = i.find('a')['href']
data_jd.append(dic)
data_link.append(dic_link)
return data_jd,data_link
#采集数据并导入pandas
data_jd = []
data_link = []
for i in urls:
data_jd.extend(get_data(i)[0])
data_link.extend(get_data(i)[1])
#print('成功采集%i个景点数据' % len(data_jd))
df = pd.DataFrame(data_jd) #导入pandas的DataFrame,类似excel表格
df_link = {}
for i in data_link:
df_link[i['景点名称']] = i['链接']
df.index = df['景点名称']
del df['景点名称']
#数据字符转数字,以计算处理
df['lng'] = df['lng'].astype(np.float)
df['lat'] = df['lat'].astype(np.float)
df['点评数量'] = df['点评数量'].astype(np.int)
df['攻略提到数量'] = df['攻略提到数量'].astype(np.int)
df['驴友去过'] = df['驴友去过'].str.split('%').str[0].astype(np.int)
df['星级'] = df['星级'].astype(np.int)
df.fillna(value = 0,inplace = True) #填充空值,如果列是lnt类型就0;如果是str就用nan
# 构建函数实现字段标准化,标准分
def nordata(dfi,*cols):
for col in cols:
dfi[col + '_b'] = round((dfi[col] - dfi[col].min())/(dfi[col].max() - dfi[col].min())*100,2)
nordata(df,'攻略提到数量','星级','点评数量')
#由驴友去过比例得分+攻略提到数量得分+星级得分+点评数得分,每项均为0-100分
df['综合得分'] = df['驴友去过']+df['攻略提到数量_b']+df['星级_b']+df['点评数量_b']
top30 = df.sort_values(by = '综合得分', ascending=False).iloc[:30]
del top30['攻略提到数量_b']
del top30['点评数量_b']
del top30['星级_b']
def jd_data(name,u): #u:网址
r = requests.get(u)
soup = BeautifulSoup(r.text, 'lxml')
dic_jd = {}
dic_jd['景点名称'] = name
dic_jd['开放时间'] = soup.find('td',class_ = "td_r")
if dic_jd['开放时间'] is None: #判断空值,防止出错
dic_jd['开放时间'] = '无'
else:
dic_jd['开放时间'] = dic_jd['开放时间'].find('p').text
dic_jd['门票价格'] = soup.find('div',class_ = "b_detail_section b_detail_ticket")
if dic_jd['门票价格'] is None: #判断空值,防止出错
dic_jd['门票价格'] = '无'
else:
dic_jd['门票价格'] = dic_jd['门票价格'].find('div',class_ = "e_db_content_box e_db_content_dont_indent").text
dic_jd['旅游时节'] = soup.find('div',class_ = "b_detail_section b_detail_travelseason")
if dic_jd['旅游时节'] is None: #判断空值,防止出错
dic_jd['旅游时节'] = '全年'
else:
dic_jd['旅游时节'] = dic_jd['旅游时节'].find('div',class_ ='e_db_content_box e_db_content_dont_indent').text
dic_jd['其他'] = soup.find('td',class_ = "td_l")
if dic_jd['其他'] is None: #判断空值,防止出错
dic_jd['其他'] = '无'
else:
dic_jd['其他'] = dic_jd['其他'].text
return dic_jd
detailed_data = []
for key in top30_data.index:
#key = '杏花沟'
print (key,' ok')
detailed_data.append(jd_data(key,df_link[key]))
detailed_df = pd.DataFrame(detailed_data)
detailed_df.index = detailed_df['景点名称']
del detailed_df['景点名称']
top30.to_excel('F://top30.xlsx') #可以到出至文件
detailed_df.to_excel('F://detailed_df.xlsx')



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











