








📋前言📋
💝博客主页:红目香薰_CSDN博客-大数据,计算机理论,MySQL,PHP领域博主💝
✍本文由在下【红目香薰】原创,首发于CSDN✍
🤗2022年最大愿望:【服务百万技术人次】🤗
环境需求
环境:win10
环境管理器:Anaconda(推荐下载地址)
开发工具:PyCharm Community Edition 2021.3.1(或Jupyter Lab)
【pip install jupyter lab】
python版本:3.7


第一节 python爬虫
使用【request与response】进行爬取
pip install requests

如果安装成功【requests】可以直接【ALT+回车】引入啊,引入的过程自动下载
import requests
#获取请求的响应结果【response】
response=requests.get("http://www.baidu.com")
#类型
print(type(response))
#响应状态【200为成功】
print(response.status_code)
#响应文本类型-一般都是str字符串
print(type(response.text))
#响应文本内容
print(response.text)
#<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
print(response.cookies)
#响应内容
print(response.content)
#修改响应的编码格式
print(response.content.decode("utf-8"))
正则表达式
第二节 Scrapy框架
pip install scrapy


基础的scrapy使用
创建项目
scrapy startproject dangdang启动
scrapy crawl dangdangSpideritems.py编码


settings.py编码


pipelines.py编码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class DangdangPipeline:
def process_item(self, item, spider):
bookfile=open("./dangdangInfo.txt","a+",encoding="utf-8")
print(bookfile)
bookfile.write(item["a1"]+","+item["a2"]+","+item["a3"]+","+item["a4"]+","+item["a5"]+"\n")
bookfile.flush()
bookfile.close()
return item
dangdangSpider.py编码

import scrapy
from scrapy.selector import Selector
from dangdang.items import DangdangItem
class ExampleSpider(scrapy.Spider):
name = 'dangdangSpider'
allowed_domains = ['www.bang.dangdang.com']
start_urls = []
for i in range(1, 26):
start_urls.append('http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' + str(i))
def parse(self, response):
#print(response.text)
bookInfo=Selector(text=response.text)
bookList=bookInfo.css("li")
for book in bookList:
item=DangdangItem()
a1=book.css("div.name a::text").extract()
if(len(a1)>0):
item["a1"]=a1[0]
a2=book.css("div.star a::text").extract()
if(len(a1)>0):
item["a2"]=a2[0]
a3=book.css("div.publisher_info a::text").extract()
if(len(a1)>0):
item["a3"]=a3[0]
a4=book.css("div.price span.price_n::text").extract()
if(len(a1)>0):
item["a4"]=a4[0][1:].strip()
a5=book.css("div.price span.price_s::text").extract()
if(len(a1)>0):
item["a5"]=a5[0]
print(item)
yield item 执行
 效果
效果


TOP500信息爬取完毕。
第三节 分词处理
Numpy简介 虽然在Python中包含许多的标准库能够处理文本和数值类型的数据,但Python还有更为丰富的第三方组件更擅长与各类数据打交道,例如Xlrd、Numpy、Scipy、Pandas等。这些组件它们侧重于数据处理,提供了一些强大的功能,比如数据统计、科学计算、统计建模等。其中Numpy是最为基础和常见的一个科学计算库。Numpy是一个运行速度非常快的数学库,主要用于数组计算,包括:强大的N维数组对象ndarray、广播功能函数、线性代数、傅里叶变换、随机数生成等功能。
import numpy as np
ndarray_a = np.array([[1, 2, 3], [4, 5, 6]])
ndarray_b = np.arange(12)
print("数组a中的类型是:", type(ndarray_a))
print("数组a中的内容是:\n", ndarray_a)
print("数组b中的类型是:", type(ndarray_b))
print("数组b中的内容是:\n", ndarray_b)

ndarray属性 在ndarray中,有几个重要的属性:数据的类型、秩(轴)、形状、元素个数。 数据的类型。Numpy支持的数据类型比Python内置的基本类型要多得多,可以通过numpy.dtype来查看ndarray的数据类型。 秩(轴)。ndarray的维度被称为秩,秩就是ndarray轴的数量,即数组的维度,一维数组的秩是1,二维数组的秩是2,可以通过ndarray.ndim来查看。 形状。ndarray的形状通过一个元组来描述,元组中的第一个数代表ndarray的第一个维度,第二个数代表第二个维度,以此类推。通过ndarray.shape查看数组的形状。 元素个数。ndarray的元素总个数可以通过ndarray.size查看,其结果相当于形状中所有数值的乘积。
import numpy as np
ndarray_a = np.array([1, 2, 3])
ndarray_b = np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32)
print("数组a中的数据类型是:", ndarray_a.dtype)
print("数组b中的数据类型是:", ndarray_b.dtype)
print("数组a中的秩是:", ndarray_a.ndim)
print("数组b中的秩是:", ndarray_b.ndim)
print("数组a的形状是:", ndarray_a.shape)
print("数组b的形状是:", ndarray_b.shape)
print("数组a的元素总个数是:", ndarray_a.size)
print("数组b的元素总个数是:", ndarray_b.size)
快速创建特殊的ndarray 使用numpy.empty来创建一个空的数组。 使用numpy.zeros来创建一个全0的数组,数组中的各个元素均为0。 使用numpy.ones来创建一个全1的数组,数组中的各个元素均为1。 使用numpy.eye来创建一个对角线为1的数组,数组中其他元素均为0。
import numpy as np
ndarray_empty = np.empty((2, 3))
ndarray_ones = np.ones((3, 2))
ndarray_zeros = np.zeros((3, 3))
ndarray_eye = np.eye(3)
print("创建的空ndarray是:\n", ndarray_empty)
print("创建的全一ndarray是:\n", ndarray_ones)
print("创建的全零ndarray是:\n", ndarray_zeros)
print("创建的对角线ndarray是:\n", ndarray_eye)
改变ndarray形状 ndarray的形状是可以改变的,比如一个元素总个数为24的数组,通过ndarray.reshape可以将该数组改变成2x12、4x6、2x3x4等各种符合元素个数的形状。
import numpy as np
ndarray_c = np.arange(24)
print("ndarray_c未改变形状之前的形状是:", ndarray_c.shape)
ndarray_c = ndarray_c.reshape(2, 12)
print("ndarray_c改变形状之后的形状是:", ndarray_c.shape)
ndarray_c = ndarray_c.reshape(4, 6)
print("ndarray_c改变形状之后的形状是:", ndarray_c.shape)
ndarray_c = ndarray_c.reshape(2, 3, 4)
print("再次改变ndarray_c的形状后,结果是:", ndarray_c.shape)
ndarray的索引机制 ndarray对象的内容可以通过索引来访问和修改,其方式基本与Python中list的操作一样。
import numpy as np
ndarray_d = np.arange(12)
print("ndarray_d数组的内容是:\n", ndarray_d)
print("ndarray_d数组中第2个元素是:", ndarray_d[1])
ndarray_d[5] = 20
print("ndarray_d数组的内容是:\n", ndarray_d)
数组的索引与切片 对于一维数组 可以通过[index1]获取index1索引位置的某个元素 也可以通过[start: end]获取索引从start开始到end-1处的一段元素 还可以通过[start: end: step]获取步长为step的start开始到end-1处的一段元素 对于多维数组 可以通过[rank1_index, rank2_index,…],获取ndarray数组中处于指定位置处的某个元素。 也可以通过[rank1_start: rank1_end, rank2_start: rank2_end, …]获取索引从start开始到end-1处的一段元素 还可以通过使用省略号…来对剩余rank进行缺省
import numpy as np
ndarray_e = np.arange(24)
ndarray_f = np.arange(24).reshape(2, 3, 4)
print("ndarray_e:\n", ndarray_e)
print("ndarray_f:\n", ndarray_f)
print("对ndarray_e进行切片,获取索引为2-12处的所有元素:", ndarray_e[2: 13])
print("对ndarray_e进行切片,指定步长为2,获取索引为2-12处的所有元素:", ndarray_e[2: 13: 2])
print("对ndarray_f进行切片,秩1上索引为1&秩2上索引为1-2&秩3上索引为0-1的元素:\n", ndarray_f[1, 1:3, 0:2])
print("对ndarray_f进行切片,秩0上索引为1&秩2上索引为1到剩余的所有元素:\n", ndarray_f[0, 1: , ...])
Numpy广播机制 NumPy广播是NumPy对不同形状的数组进行数值计算的方式,NumPy广播要求对数组的算术运算通常在相应的元素上进行。如果当运算中的2个数组的形状不同时,numpy将自动触发广播机制: 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都在前面加1补齐。 输出数组的形状是输入数组形状的各个维度上的最大值。 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为1时,这个数组能够用来计算,否则出错。 当输入数组的某个维度的长度为1时,沿着此维度运算时都用此维度上的第一组值。 简单的说,当两个数组计算时,会比较它们的每个维度(若其中一个数组没有当前维度则忽略),如果满足以下三个条件则触发广播机制: 数组拥有相同形状。 当前维度的值相等。 当前维度的值有一个是1。 若条件不满足,则抛出"ValueError: frames are not aligned"异常。
ndarray_g = np.arange(12).reshape(4, 3)
ndarray_h = np.arange(3)
print("ndarray_g的形状是:", ndarray_g.shape)
print("ndarray_h的形状是:", ndarray_h.shape)
print("ndarray_g与ndarray_h相加后的结果是:\n", ndarray_g+ndarray_h)
ndarray_i = np.arange(24).reshape(2, 4, 3)
print("ndarray_g与ndarray_i相加后的结果是:\n", ndarray_g+ndarray_i)
numpy pands
【pip install pands】

Series
下载的时候比较慢,等一会就好了。
import numpy as np
import pandas as pd
series_a = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
print("series_a的类型是:", type(series_a))
print("series_a:")
print(series_a)
series_a["a"] = 5
print("series_a:")
print(series_a)
series_b = pd.Series([8, 6, -5, 2], index=["a", "b", "c", "d"])
print(series_b[series_b > 0]) #获取值大于0的数据。
print(series_b * 2) #输出Series对象中每个数据乘2之后的结果。
print("a" in series_b) #判断obj对象中是否存在索引值为"a"的数据。
print(series_b.isnull()) #检测缺失数据
series_b.index = ["f","g","k","m"]
print(series_b)
输出结果如下:
series_a的类型是: <class 'pandas.core.series.Series'>
series_a:
a 0
b 1
c 2
d 3
e 4
dtype: int32
series_a:
a 5
b 1
c 2
d 3
e 4
dtype: int32
a 8
b 6
d 2
dtype: int64
a 16
b 12
c -10
d 4
dtype: int64
True
a False
b False
c False
d False
dtype: bool
f 8
g 6
k -5
m 2
dtype: int64Process finished with exit code 0
DataFrame
DataFrame数据结构 DataFrame是由多种类型的列构成的二维标签数据结构,类似于Excel、SQL表,或Series 对象构成的字典。 与Series不同的是,DataFrame具有两个索引,通过传递索引可以定位到具体的数值。

import pandas as pd
import numpy as np
frame_a = pd.DataFrame(np.arange(6).reshape(2, 3),
index=["a", "b"],
columns=["x", "y", "z"],
dtype=np.float32)
print(frame_a)

import pandas as pd
import numpy as np
frame_c = pd.DataFrame(np.arange(12).reshape(3, 4),
index=["a", "b", "c"],
columns=["w", "x", "y", "z"])
print("frame_c的行索引是:", frame_c.index)
print("frame_c的列索引是:", frame_c.columns)
print("frame_c中第二行第3个元素是:", frame_c.iloc[1, 2])
print("frame_c中行索引为\"a\"、列索引为\"x\"的元素是:", frame_c.loc["a"]["x"])
frame_c.iloc[1, 2] = 99
print("修改frame_c中第二行第3个元素后,frame_c是:")
print(frame_c)
print("frame_c丢弃\"z\"列后的结果是:")
print(frame_c.drop("z", axis=1))
print("frame_c丢弃\"a\"行后的结果是:")
print(frame_c.drop("a"))

排序与统计
import pandas as pd
import numpy as np
frame_d = pd.Series(range(4),index=["d", "a", "b", "c"])
print(frame_d.sort_index()) #sort_index函数
frame_e = pd.DataFrame(np.arange(9).reshape(3, 3),
columns=["z", "x", "y"],
index=["c", "a", "d"])
print(frame_e.sort_index())#sort_index函数
print(frame_e.sort_index(axis=1))
print(frame_e.sort_index(axis=1,ascending=False))
frame_f = pd.DataFrame({"b":[4, -3, 7, 2], "a":[1, 6, 5, 3]})
print(frame_f.sort_values(by="b"))#对"b"这一列进行升序排列
print(frame_f.sort_values(by=["a", "b"]))#同时对两列进行升序排列
输出结果
a 1
b 2
c 3
d 0
dtype: int64
z x y
a 3 4 5
c 0 1 2
d 6 7 8
x y z
c 1 2 0
a 4 5 3
d 7 8 6
z y x
c 0 2 1
a 3 5 4
d 6 8 7
b a
1 -3 6
3 2 3
0 4 1
2 7 5
b a
0 4 1
3 2 3
2 7 5
1 -3 6Process finished with exit code 0
| 统计函数 | 功能说明 |
| count | 非NaN值的数量 |
| min,max | 最小值和最大值 |
| argmin,argmax | 最小值和最大值的索引位置(整数) |
| idxmin,idxmax | 最小值和最大值的索引值 |
| sum | 求和 |
| mean | 均值 |
| var | 方差 |
| std | 标准差 |
| diff | 计算一阶差分(对时间序列很有用) |
import pandas as pd
frame_g = pd.Series(["a", "c", "a", "c", "b", "a", "d", "d"])
uniques = frame_g.unique() #获取Series中的唯一值数组
print(uniques)
uniques.sort() #对Series数组进行排序
print(uniques)
#计算Series数组各值出现的频率
print(frame_g.value_counts())
#obj各值是否包含于["b","c"]中
mask = frame_g.isin(["b","c"])
print(mask)
print(frame_g[mask]) #选取Series中数据的子集

异常值处理
缺失数据在大部分数据分析应用中都很常见,Pandas的设计目标之一就是让缺失数据的处理任务尽量轻松 Pandas使用浮点值NaN(Not a umber)表示浮点和非浮点数组中的缺失数据 Pandas提供了专门的处理缺失数据的函数:
| 函数 | 说明 |
| dropna | 根据各标签的值中是否存在缺失数据对轴标签进行过滤 |
| fillna | 用指定值或插值函数填充缺失数据 |
| isnull | 返回一个含有布尔值的对象,这些布尔值表示哪些值是缺失值 |
| notnull | 返回一个含有布尔值的对象,这些布尔值表示哪些值不是缺失值 |
import pandas as pd
import numpy as np
data = pd.Series(["a", np.nan, "c", "d"])
print(data.isnull()) #判断是否为空对象
data = pd.Series([1, np.nan, 3, np.nan, 7])
print(data.dropna()) #滤掉缺失数据
#通过布尔值索引滤除数据
print(data[data.notnull()])
data = pd.DataFrame([[1, 6, 5], [2, np.nan, np.nan]])
#滤除DataFrame中的缺失数据
print(data.dropna())
print(data.dropna(axis=1))

时间处理
时间序列数据是一种重要的结构化数据形式。
在Python语言中,主要使用datatime模块来处理时间:
datetime对象间的减法运算会得到一个timedelta对象,timedelta对象代表两个时间之间的时间差。
datetime对象与它所保存的字符串格式时间戳之间可以互相转换。
在Pandas中,主要使用从Series派生出来的子类TimeStamp:
最基本的时间序列类型就是以时间戳(TimeStamp)为index元素的Series类型。
时间序列只是index比较特殊的Series,因此一般的索引操作对时间序列依然有效。
时间序列只是index比较特殊的Series,因此一般的索引操作对时间序列依然有效。
import datetime as datetime
import pandas as pd
import numpy as np
print(pd.to_datetime(datetime.datetime.now()))
print(pd.to_datetime(np.nan))
dates = [datetime.datetime(2022,1,1),
datetime.datetime(2022,1,2),
datetime.datetime(2022,1,3)]
ts = pd.Series(np.random.rand(3), index=dates)
print(ts)

时间处理
import pandas as pd
print(pd.date_range("20220101", "20220108"))
print(pd.date_range(start="20220101", periods=8))
print(pd.date_range(end="20220108", periods=8))
print(pd.date_range("20220101", "20220501", freq="M"))
print(pd.date_range('20221018', '2022-10-25'))
print(pd.date_range('2022/10/18', '2022-10-25'))
print(pd.date_range('2022/10/21', '2022-10-22', freq="4H"))

文件读写
常见的文件读写有3种,
分别是一般文本文件、 CSV文件Excel文件,
Pandas提供了便利的CSV和Excel文件读写方式:
使用to_csv()函数将DataFrame对象写入到CSV文件。
使用read_csv()函数读取CSV文件。
使用to_excel()函数将DataFrame对象写入到CSV文件。
使用read_excel()函数读取CSV文件。
import pandas as pd
import os
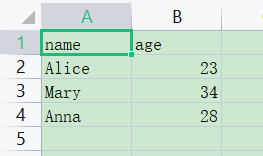
df_write = pd.DataFrame({"name": ["Alice", "Mary", "Anna"],
"age": ["23", "34", "28"]})
root_path = os.getcwd()
file_with_path = os.path.join(root_path, 'test.csv')
df_write.to_csv(file_with_path, index=False)
df_read = pd.read_csv(file_with_path)
print(df_read)
















 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











