







如果你对位图还不熟悉的话,你可以去看看这篇博客:
http://blog.csdn.net/fengasdfgh/article/details/53090475
布隆过滤器主要是为了过滤一些垃圾网站,或者防止网络爬虫死循环。事实上我们需要记住这些网站的链接地址,然后在一个位图里查找它是否出现过。
//
我在位图里提到过,位图主要保存的是数字的状态,要想保存字符串,必须使用哈希算法把字符串转换为数字,但是这里还牵涉到了哈希冲突,毕竟网站地址的数量是很庞大的并且有的长有的短,转换后的数值难免有的会相等。这会导致一个字符串的状态会影响到另一个字符串的状态,为了降低这些影响,我们多次使用不同的哈希算法,这样一个字符串会对应着多个位,这样两个字符串重合的概率就很低了。

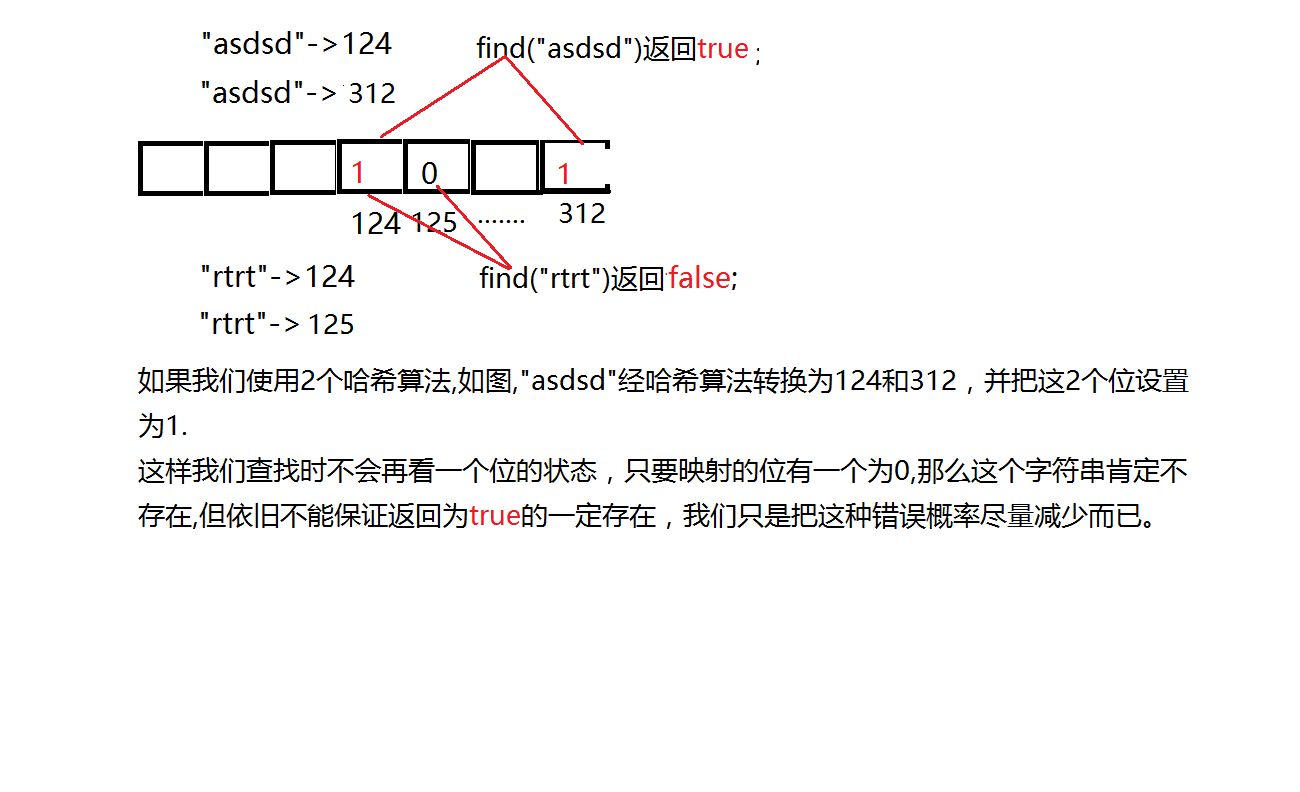
但是如果你要删除一个字符串的话,如果这个字符串与其他字符串有重合的位,那么势必会影响到其他的字符串。
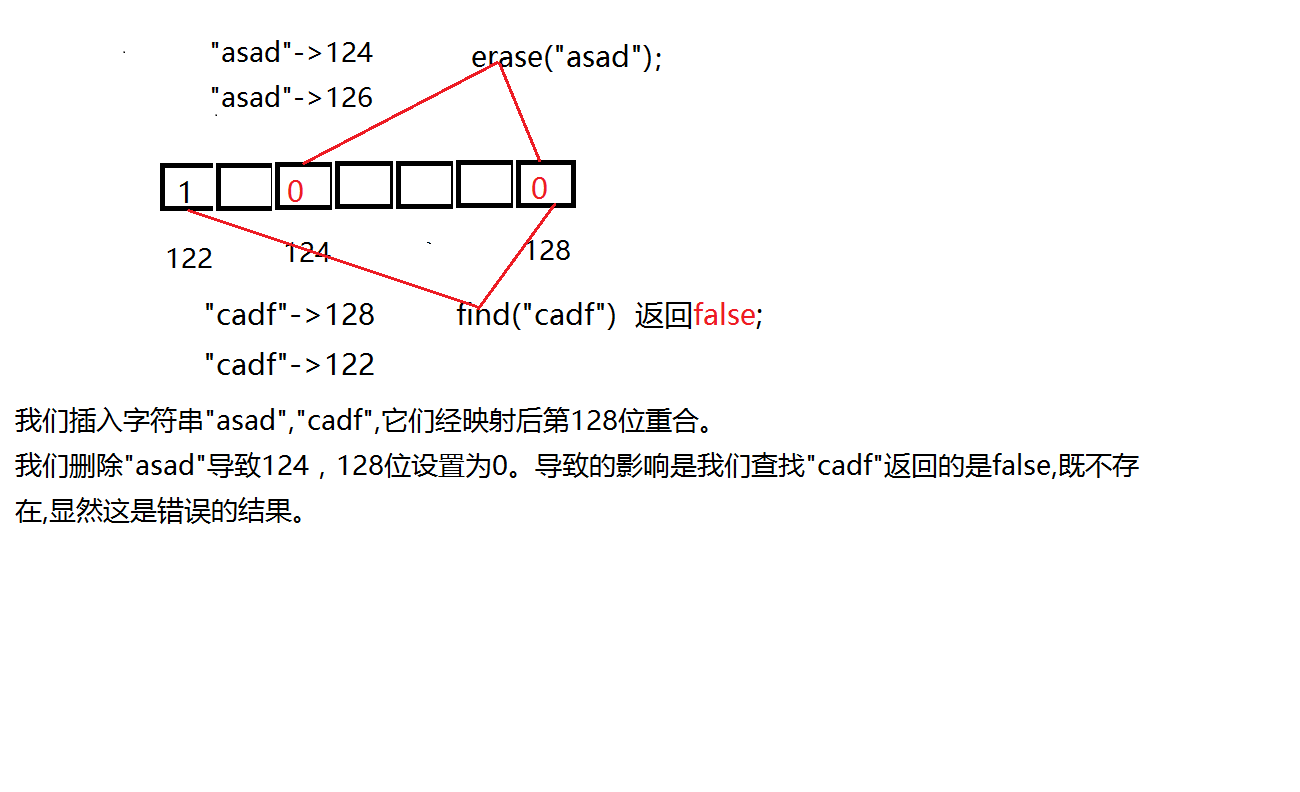
我们可以向智能指针一样,添加一个引用计数。如果一个位上的引用计数为0则我们可以把它改为0.
全部代码如下:
#pragma once
#include "bitmap.h"
//以下部分为哈希函数
template<class T = string>
class BkdRHash
{
public:
BkdRHash() {};
size_t operator()(const T *str)
{
register size_t hash = 0;
while (size_t ch = (size_t)*str++)
{
hash = hash * 131 + ch;
}
return hash;
}
};
template<class T = string>
class JsHash
{
public:
JsHash() {};
size_t operator()(const T *str)
{
register size_t hash = 1315423911;
while (size_t ch = (size_t)*str++)
{
hash^= ((hash << 5) + ch + (hash >> 2));
}
return hash;
}
};
template<class T = string>
class SDBMHash
{
public:
SDBMHash() {};
size_t operator()(const T *str)
{
register size_t hash = 0;
while (size_t ch = (size_t)*str++)
{
hash = 65599 * hash + ch;
//hash = (size_t)ch + (hash << 6) + (hash << 16) - hash;
}
return hash;
}
};
template<class T = string>
class RsHash
{
public:
RsHash() {};
size_t operator()(const T *str)
{
register size_t hash = 0;
size_t magic = 63689;
while (size_t ch = (size_t)*str++)
{
hash = hash * magic + ch;
magic *= 378551;
}
return hash; ;
}
};
template<class T = string>
class ApHash
{
public:
ApHash() {};
register size_t hash = 0;
size_t ch;
for (long i = 0; ch = (size_t)*str++; i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
}
return hash;
};
//////////////
template<class T = string, class Hash1 = BkdRHash, class Hash2 = Jshash, class Hash3 = SDBMHash,
class Hash4 = RsHash, class Hash5 = ApHash>
class BloomFilter
{
public:
BloomFilter(unsigned long size)
:_A(size)
,_size(size)
,_seq(size, 0)
{
}
void insert(const T &str)
{
hash1 = Hash1()(str) % _size;
hash2 = Hash2()(str) % _size;
hash3 = Hash3()(str) % _size;
hash4 = Hash4()(str) % _size;
hash5 = Hash5()(str) % _size;
_A.insert(hash1);
_seq[hash1]++;
_A.insert(hash2);
_seq[hash2]++;
_A.insert(hash3);
_seq[hash3]++;
_A.insert(hash4);
_seq[hash4]++;
_A.insert(hash5);
_seq[hash5]++;
}
bool find(const T& str)
{
hash1 = Hash1()(str) % _size;
if (!_A.find(hash1))
return false;
hash2 = Hash2()(str) % _size;
if (!_A.find(hash2))
return false;
hash3 = Hash3()(str) % _size;
if (!_A.find(hash3))
return false;
hash4 = Hash4()(str) % _size;
if (!_A.find(hash4))
return false;
hash5 = Hash5()(str) % _size;
if (!_A.find(hash5))
return false;
return true;
}
void erase(const T& str)
{
hash1 = Hash1()(str) % _size;
if (_seq[hash1] > 0)
_seq[hash1]--;
hash2 = Hash2()(str) % _size;
if (_seq[hash2] > 0)
_seq[hash2]--;
hash3 = Hash3()(str) % _size;
if (_seq[hash3] > 0)
_seq[hash3]--;
hash4 = Hash4()(str) % _size;
if (_seq[hash4] > 0)
_seq[hash4]--;
hash5 = Hash5()(str) % _size;
if (_seq[hash5] > 0)
_seq[hash5]--;
_seq[hash1] ? 1 : _A.resert(hash1);
_seq[hash2] ? 1 : _A.resert(hash2);
_seq[hash3] ? 1 : _A.resert(hash3);
_seq[hash4] ? 1 : _A.resert(hash4);
_seq[hash5] ? 1 : _A.resert(hash5);
}
private:
Bitmap _A;
unsigned long _size;
vector<size_t> _seq;
};哈希函数参考:http://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









