






今天给大家带来的复现内容是CHARLS数据库的一篇横断面研究文章,文章统计方法部分包括了①基线差异性分析、②诊断试验评价(ROC曲线、AUC值、约登指数cutoff值)、③回归控制混杂因素。
这些统计方法风暴统计统统一站式搞定,零代码操作,新手小白也可以轻松上手完成!
今日文章分为两部分
复现文章介绍
.风暴统计平台快速复现

1.复现文章介绍

案例文献是一篇基于CHARLS公共数据库的一项横断面研究,旨在全面比较肥胖和脂质相关指标对T2D的预测能力。
|

预测中国中老年人2型糖尿病的最佳肥胖和脂质相关指标
1.1 基线差异性分析
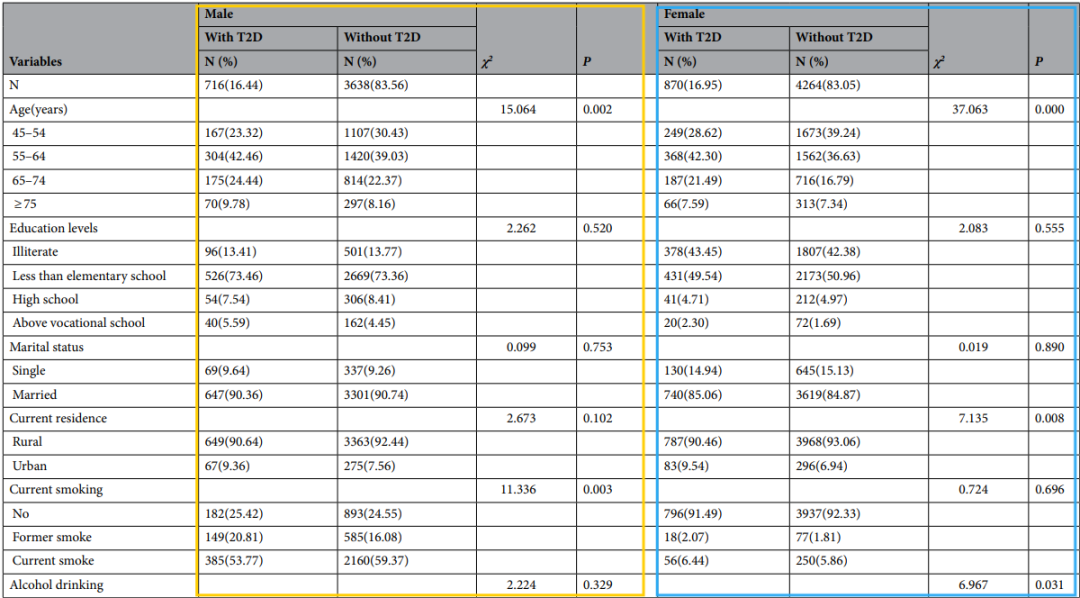
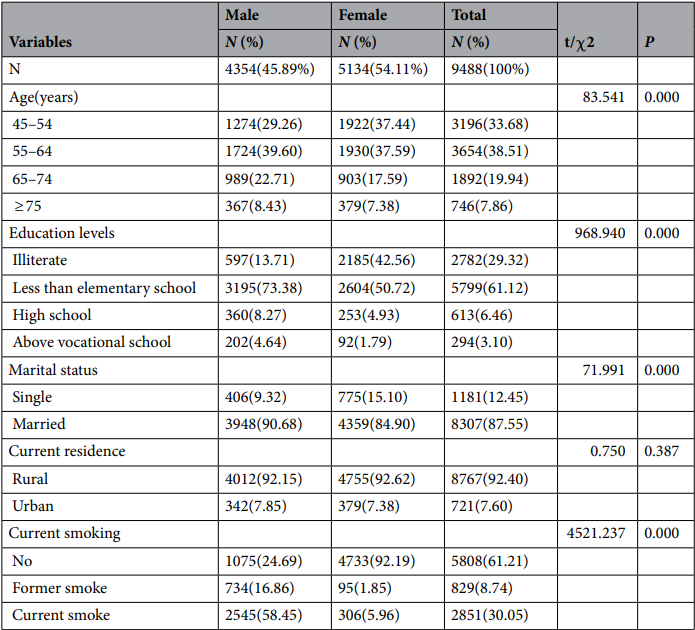
这篇文章比较特别,有2张基线描述表格。表1将性别作为分组变量,对人群基线特征进行描述。表2则是在性别分组的基础上增加了是否患有2型糖尿病的分组!通过双重分组变量,对不同性别人群中,是否患有2型糖尿病人群的基线特征进行更详细的描述。
|
 |
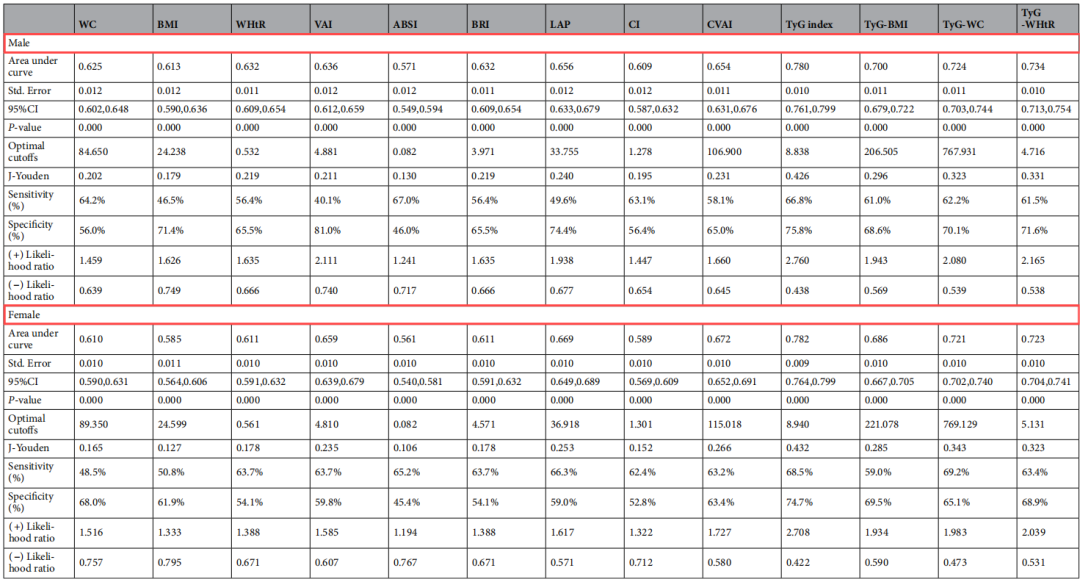
1.2 预测能力比较——AUC指数+约登指数计算最佳cutoff点
肥胖脂质相关的自变量有13个,分别在不同性别人群中与结局2型糖尿病构建预测模型,并计算AUC值、约登指数、最佳截断值、灵敏度、特异度。
|
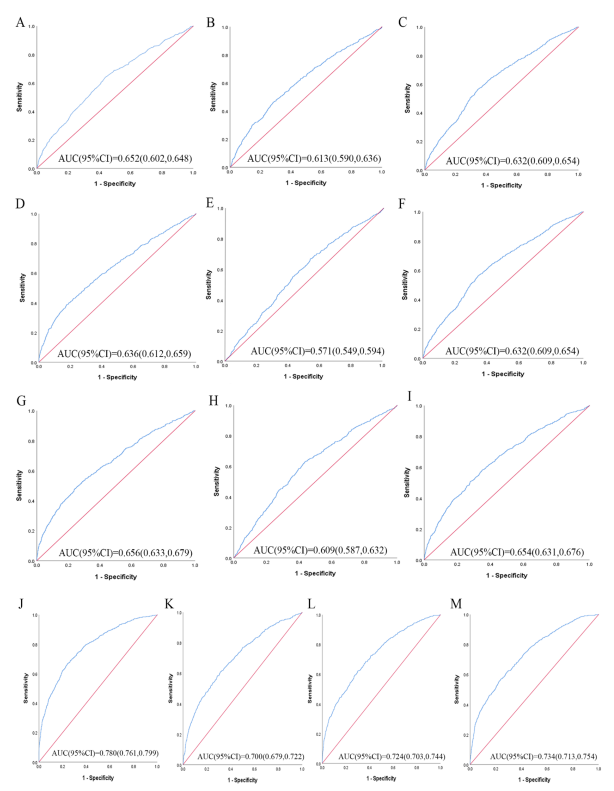
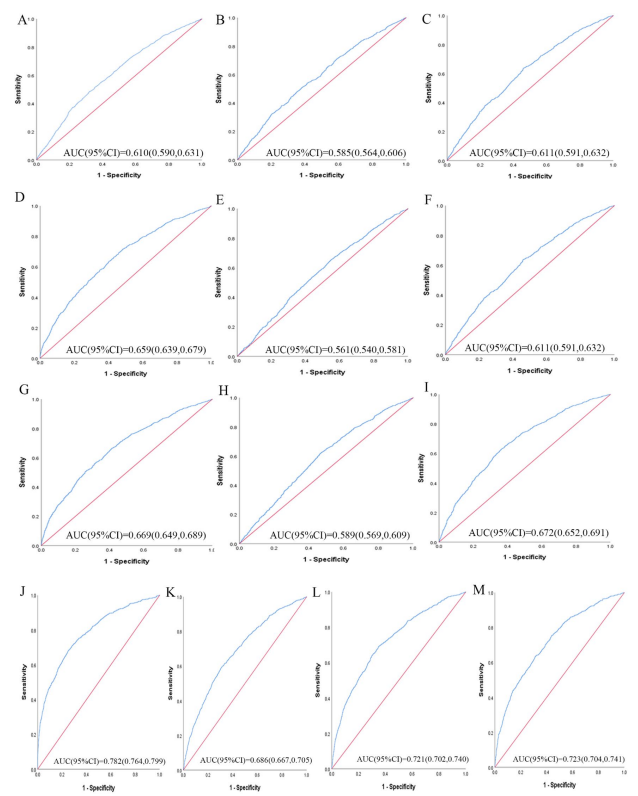
1.3 预测能力比较——ROC曲线
对13个肥胖脂质相关指标,在不同性别人群中,分别绘制ROC曲线,比较不同指标对2型糖尿病人群的区分度。
男性 |
女性 |
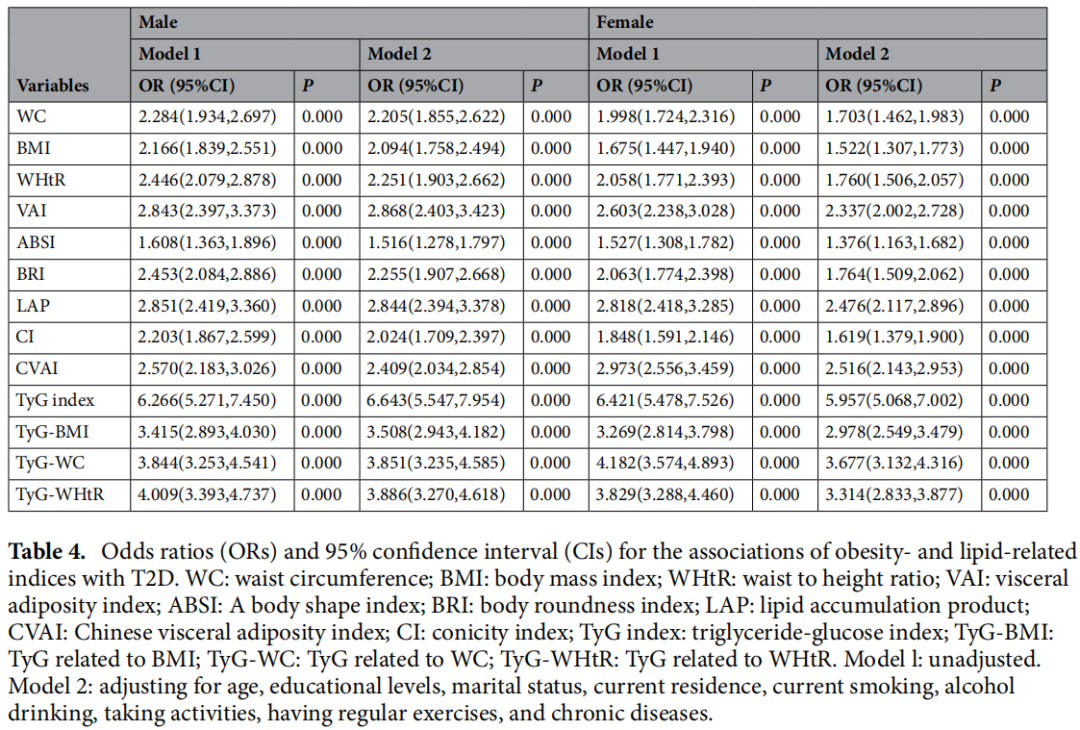
1.4 相关性探索——单因素+多因素回归结果
分别对13个肥胖脂质相关指标与2型糖尿病结局构建logistic回归模型,model1为粗模型,未校正任何变量,model2对年龄、教育水平、婚姻状况、当前居住地、当前吸烟、饮酒、参加活动、定期锻炼和慢性疾病几个协变量进行了调整。
 |
以上就是本篇CHARLS数据库文章的主要内容啦!下面我们将通过风暴统计平台进行结果复现!

2.风暴统计平台快速复现

风暴统计平台是由浙江中医药大学郑卫军教授基于R语言开发的统计分析平台,它具有以下优点:
结果输出简洁,直接生成三线表,支持word版下载!
平台是基于R语言进行开发,结果准确性有保障!
全部菜单式操作,统计小白也可以轻松上手!

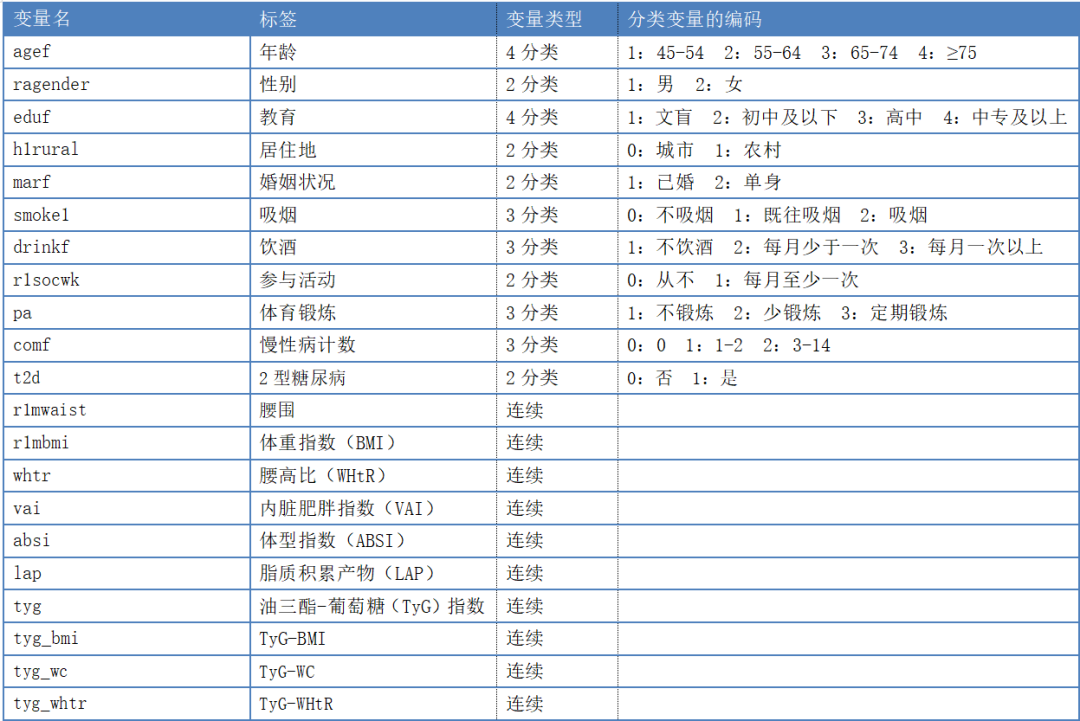
2.1 复现数据介绍
我们复现用到的数据集是根据原文献变量及纳排标准整理的,样本量n=9247(原文献9488),样本量有所出入,但是变量和原文保持一致,包含有:
便利起见,针对这篇文章的统计方法制作了专用链接,按顺序操作即可复现全部统计方法,不用在风暴统计平台换模块分析啦!
https://shiny.medsta.cn/zhufy/
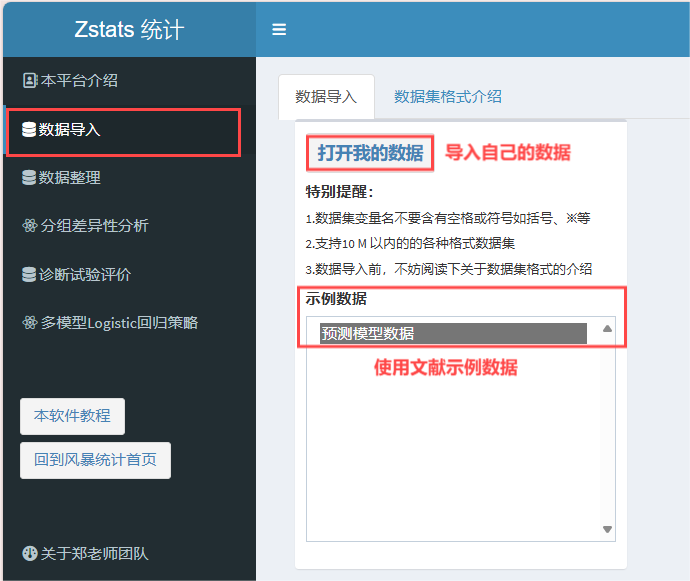
2.2 数据导入
进入网页后,可以选择导入自己的数据进行分析,也可以选择示例数据(也就是我们本篇文献的复现数据)进行实操。
2.3 基线差异性分析
因为本篇文章涉及了2个基线表格,因此我们分开介绍:
基线表1:以是否患2型糖尿病为分组变量进行基线描述
根据原文献,分别选入定量数据及分类数据。
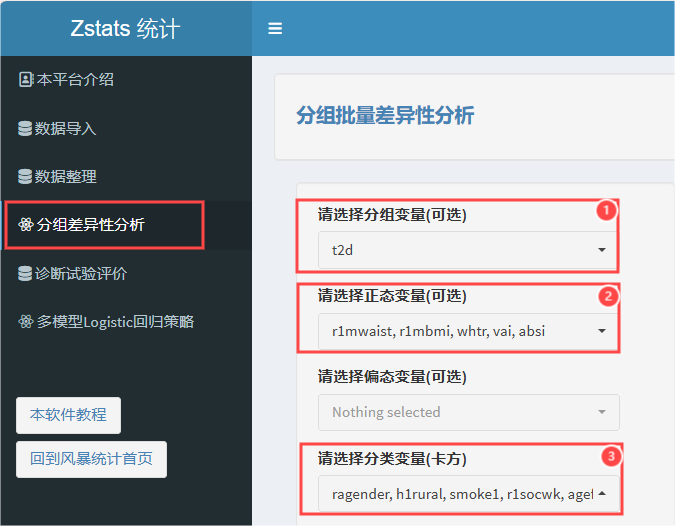
选择完毕后,平台就会直接给出基线差异性结果啦!和原文献对比发现,提供的信息很全面且一致,包括全人群的分布,分组下各基线特征的分布,统计量,P值!
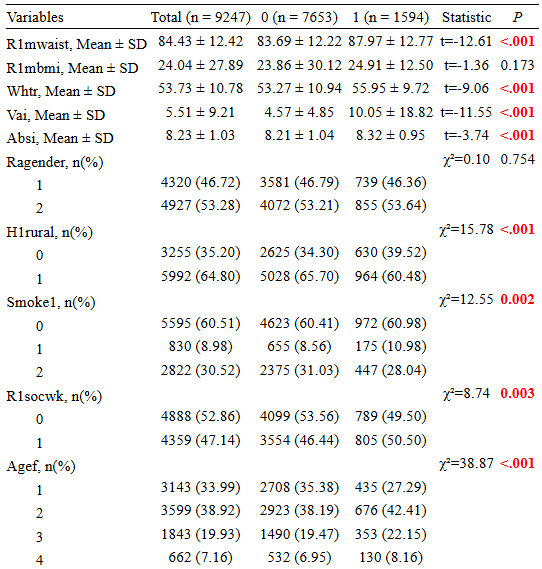 |
基线表2:以是否患2型糖尿病+性别双分组变量进行描述
相较于基线表1,这里只需要在"数据整理"模块,增加一个步骤,就可以分开绘制不同性别人群中,不同结局下人群的基线特征。
选择"分析集"——"分析子集",取消勾选性别男(分组1),那么我们的样本就只有性别女(分组2)的人群了,可以看到样本量变为了4927。
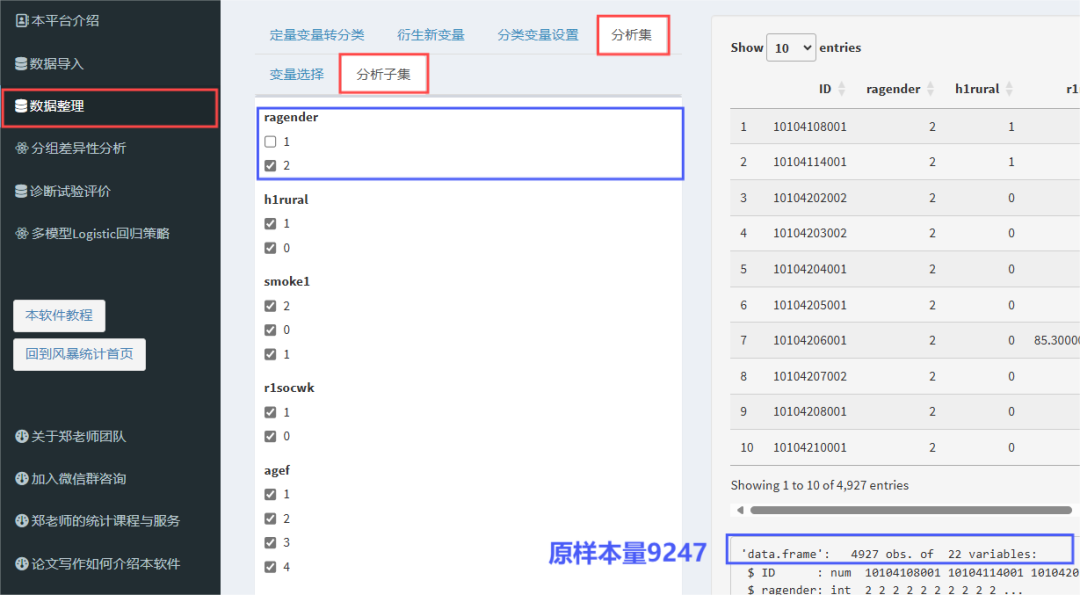
接着重复基线表1的操作(在"分组差异性分析"部分),就可以得到基线表2中女性人群中,是否患有2型糖尿病人群中的基线特征了。
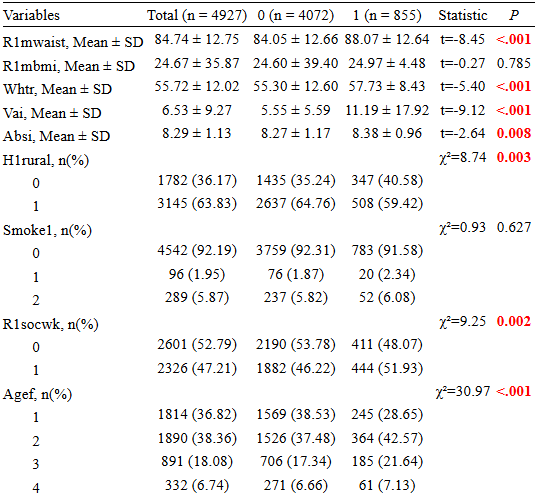 |
2.4 预测能力比较——AUC指数+约登指数计算最佳cutoff点+ROC曲线
接着来到"诊断试验评价"模块,依次选入"因变量"与"自变量"。
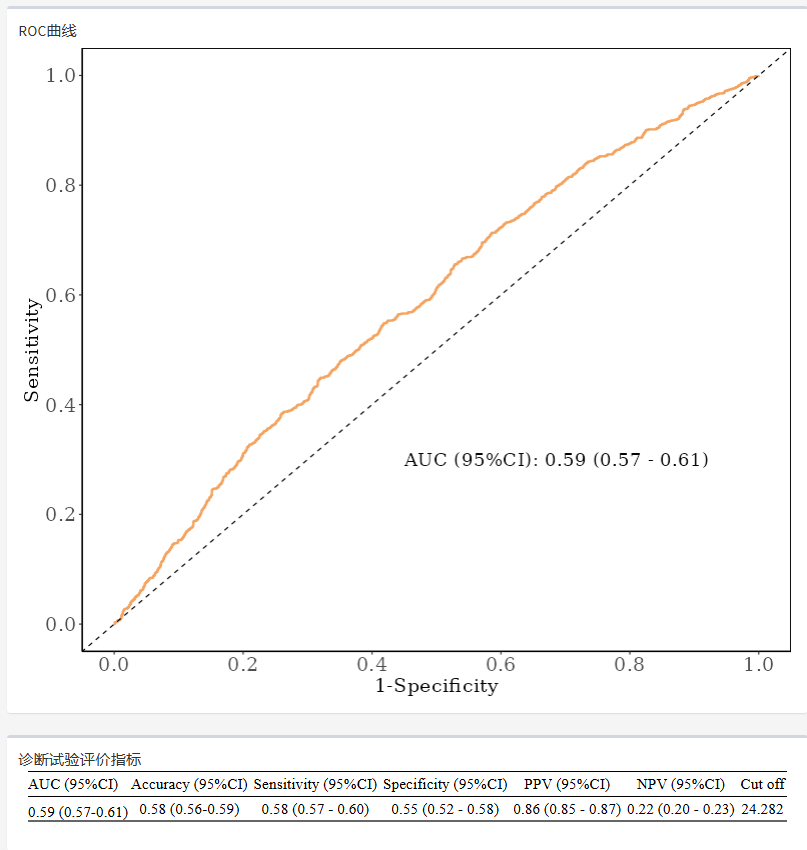
平台就会自动给出ROC曲线、AUC面积与95%置信区间、灵敏度、特异度、根据约登指数计算出的cutoff值。并且还有阳性预测值、阴性预测值!统统搞定~
2.5 相关性探索——单因素+多因素回归结果
来到"多模型logistic回归策略",依次选入因变量、自变量、以及协变量。
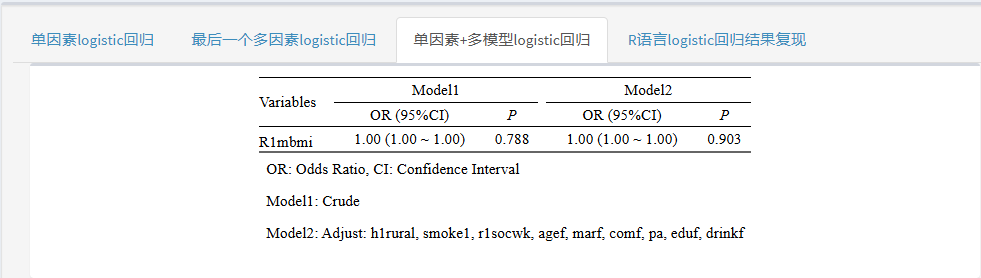
平台就完成了单因素回归、调整协变量后的回归分析啦!一步到位~
同理,在分析子集中,我们选择"1",那么就可以计算男性群体中的基线差异性分析结果、ROC曲线、回归分析了。
以上就是我们本次零代码复现SCI文章的全部内容啦!有双分组下的基线差异性分析 、诊断试验评价、回归控制混杂等常见统计分析方法!欢迎试用下方链接,进行复现与测试哦!
https://shiny.medsta.cn/zhufy/
如果您在使用过程中出现报错,可以参考下方推文,排查一下问题所在哦!
















 2770
2770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









