






一、模型解释性的意义
❝机器学习业务应用以输出决策判断为目标。可解释性是指人类能够理解决策原因的程度。机器学习模型的可解释性越高,人们就越容易理解为什么做出某些决定或预测。模型可解释性指对模型内部机制的理解以及对模型结果的理解。其重要性体现在:建模阶段,辅助开发人员理解模型,进行模型的对比选择,必要时优化调整模型;在投入运行阶段,向业务方解释模型的内部机制,对模型结果进行解释。比如基金推荐模型,需要解释:为何为这个用户推荐某支基金。
❞
在机器学习应用中,有些领域(如金融风控)的模型决策很看重业务的解释性,通过业务先验的知识加以调整并监控模型、以创造更值得信任的、安全可靠的模型。 追求业务解释性,可以减少一些歧视、违规、不合理的特征决策,对模型带来类似正则化效果,可以减少统计噪音的影响(减少过拟合),有更好的泛化效果。
追求业务解释性,可以减少一些歧视、违规、不合理的特征决策,对模型带来类似正则化效果,可以减少统计噪音的影响(减少过拟合),有更好的泛化效果。
但是,追求业务解释性是个繁琐的事情,首先你得有足够的业务应用知识的理解,其次还要手动不停地调整一版又一版的模型。业界上对合理的业务解释性可以提升模型的效果这是肯定的,特别是在小数据、数据不稳定的情况,
一个金融领域简单的例子,如现有的1000条样本显示,有条数据规律:申请贷款的次数低于10,用户的贷款逾期概率就越大。但是结合业务来看,一个人频繁申请贷款,其负债、还款能力肯定是有问题的,这时仅凭这条现有数据规律去决策风险有点大,很大概率这条决策在更多样本的情况下就是失效的。
我们通过解释性的工具剖析模型决策,当模型决策不符合合理的业务逻辑或法规什么的 ,这时,就很有必要做一些特征选择,调整模型,以符合业务解释性:
如经典的逻辑回归-lr ,需要不断凭借业务含义调整特征分箱决策的单调性:一文梳理金融风控建模全流程(Python)
如树模型,一个简单的剪枝调整业务解释性的方法。
二、引入业务先验约束的树模型(GBDT)
但上面两种方法都比较依赖于手动微调模型,以符合业务解释性。为什么不直接在训练过程中,直接依据业务先验知识辅助模型训练?
在此,本文另提出一个思路,通过在树模型学习训练过程(树节点的分裂过程),简单引入个业务先验约束(当前特征值分裂如不符合业务逻辑则弃用),以让决策过程符合业务解释性。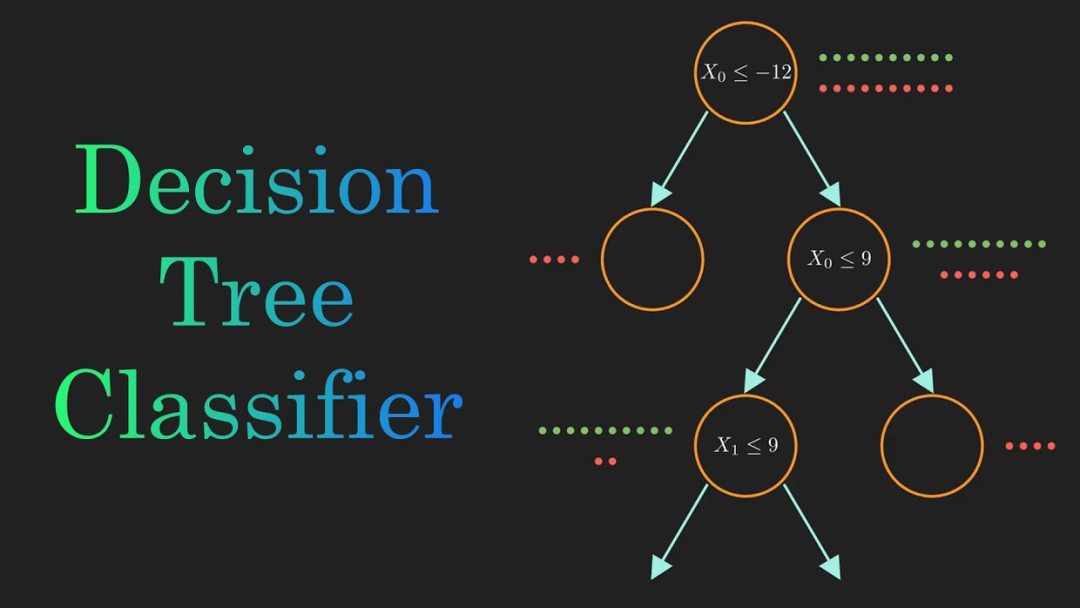
大致步骤是,
首先在 GBDT训练代码中,配置各特征业务逻辑性的约束
如 当前二分类数据集有age,weight两个特征。假设我们从业务理解上(先验知识),认为年龄age应该和标签是呈现负相关的,年龄数值越大,标签值应该要越小。那我们就可以配置特征约束的字典feas_logit, 配置特征age业务逻辑性的约束, 新增{'age': -1}, 其中-1代表该特征与标签的业务规律约束为负相关,+1代表正相关。暂不支持非单调关系的业务约束配置。
# 配置特征业务逻辑性的约束
feas_logit = {'age': -1}特征节点分裂时加入业务逻辑判断(约束)
GBDT是cart二叉决策树集成实现的,对于每一棵cart树,我们会遍历所有特征,尝试以每一特征值作为决策的分裂点。我们可以在这里加入约束限制,如年龄age特征,我们认为它和标签值是负相关的,那么对于每次分类age<特征阈值的左边分支的样本群体的标签均值应该大于右边分支的(反之亦然)。如果树生长的特征分裂不符合业务逻辑的,则会略过,继续其他特征值的搜索。
# 完整代码:https://github.com/aialgorithm/Blog
for feature in self.features:
self.logger.info(('----划分特征:', feature))
feature_values = now_data[feature].unique()
for fea_val in feature_values:
# 尝试划分
left_index = list(now_data[feature] < fea_val)
right_index = list(now_data[feature] >= fea_val)
left_labelvalue = now_data[left_index][self.target_name]
right_labelvalue = now_data[right_index][self.target_name]
# 该特征划分 加入判断业务逻辑合理性约束##
if feature in self.feas_logit: # 如果该划分不符合业务合理性约束则继续搜索其他划分
if not self.feas_logit[feature]*right_labelvalue.mean() > self.feas_logit[feature]*left_labelvalue.mean():
continue
# 计算划分后的损失
left_se = calculate_se(left_labelvalue)
right_se = calculate_se(right_labelvalue)
sum_se = left_se + right_se
self.logger.info(('------划分值:%.3f,左节点损失:%.3f,右节点损失:%.3f,总损失:%.3f' %
(fea_val, left_se, right_se, sum_se)))
if se is None or sum_se < se:
split_feature = feature
split_value = fea_val
se = sum_se
left_index_of_now_data = left_index
right_index_of_now_data = right_index代码运行
依赖环境:
操作系统:Windows/Linux
编程语言:Python3
Python库:pandas、PIL、pydotplus, 其中pydotplus库会自动调用Graphviz,所以需要去Graphviz官网下载
graphviz的-2.38.msi,先安装,再将安装目录下的bin添加到系统环境变量,此时如果再报错可以重启计算机。详细过程不再描述,网上很多解答。
文件结构(修改前GBDT手写代码如参考文末链接):
| - GBDT 主模块文件夹
| --- gbdt.py 梯度提升算法主框架
| --- decision_tree.py 单颗树生成,包括节点划分和叶子结点生成
| --- loss_function.py 损失函数
| --- tree_plot.py 树的可视化
| - example.py 回归/二分类/多分类测试文件
二分类GBDT测试,运行如下命令:
python example.py --model binary_cf还未增加约束的GBDT
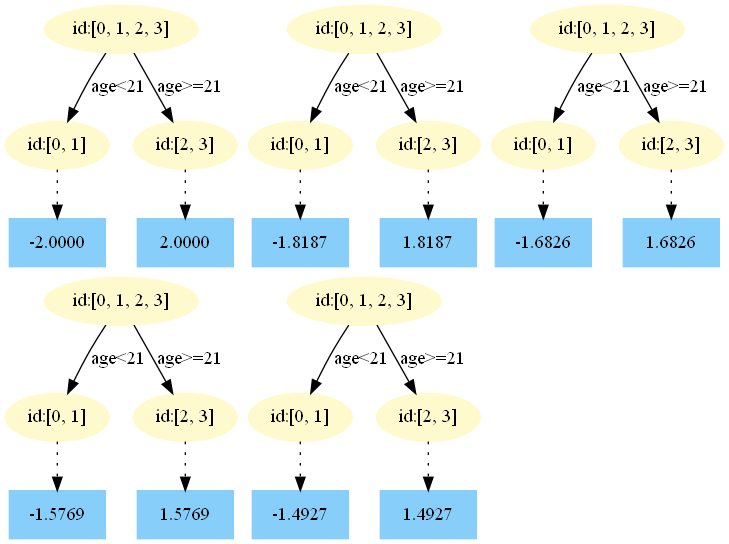 可见在原来的数据规律里面,age和标签是呈现正相关的,也就是age越高,标签值越高。
可见在原来的数据规律里面,age和标签是呈现正相关的,也就是age越高,标签值越高。当我们在example.py中新增配置业务先验约束(令age需要和标签呈负相关)的GBDT。此时,在本实验数据集age特征的各分裂点可能都是不符合业务逻辑,都没有选用,如下运行结果:
def run(args):
### 配置特征业务逻辑性得约束###
feas_logit = {'age': -1}
### 配置end###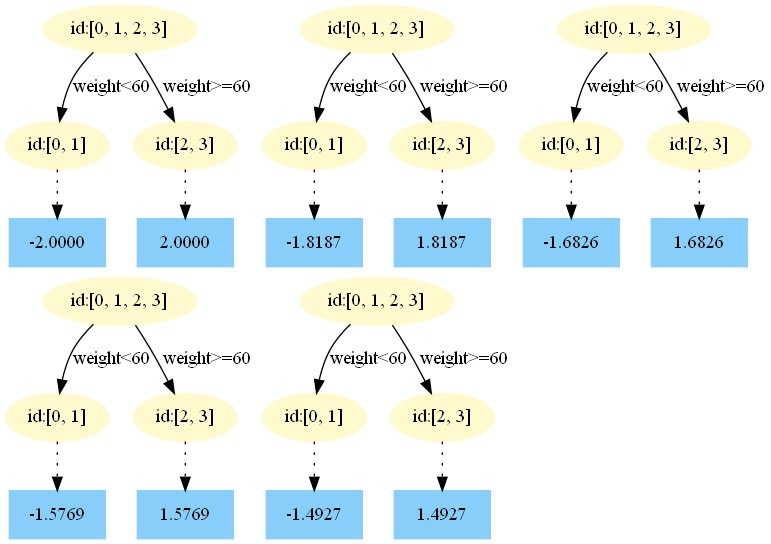 个人实践经验,当加入的业务先验比较合理的情况,模型泛化(测试集)误差可能会更低(训练集的误差通常会增加),或者训练-测试两者差异更小了。模型有更好的泛化能力。有兴趣的童鞋可以在更大数据集里面试验下,以便更客观地评估下加入业务约束的模型效果差异。
个人实践经验,当加入的业务先验比较合理的情况,模型泛化(测试集)误差可能会更低(训练集的误差通常会增加),或者训练-测试两者差异更小了。模型有更好的泛化能力。有兴趣的童鞋可以在更大数据集里面试验下,以便更客观地评估下加入业务约束的模型效果差异。
❝参考链接-GBDT算法原理以及实例理解:https://blog.csdn.net/zpalyq110/article/details/79527653
❞

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码














 2312
2312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









