






作者丨科技猛兽 编辑丨极市平台
导读
受低比特 LLM 量化感知训练方案的启发,本文研究了三值 DiT 模型的 QAT 量化方法,并引入了 DiT 特异性改进来更好地训练。
本文目录
1 TerDiT:三值 Diffusion Transformer
(来自港中文,上海交大,上海 AI Lab)
1 TerDiT 论文解读
1.1 Diffusion Transformer 变大之后的部署难题
1.2 Diffusion Transformer
1.3 模型量化
1.4 QAT 特定的模型架构改进
1.5 部署策略
1.6 实验设置
1.7 实验结果
太长不看版
大规模的预训练文生图扩散模型促进了高保真度图像的生成,尤其是随着基于 Transformer 的 Diffusion 架构的出现。在这些扩散模型中,Diffusion Transformer 表现出了优越的图像生成能力,做到了较低的 FID 分数和更高的可扩展性。然而,由于参数量大,部署大规模 DiT 模型很昂贵。尽管现有研究已经探索了有效的扩散模型部署技术,例如模型量化,但关于基于 DiT 的模型的工作仍然很少。
为了解决这一研究差距,本文作者提出 TerDiT,一种针对三值 Transformer 的量化感知训练 (QAT) 方案。作者专注于 DiT 网络的三值化和从 600M 到 4.2B 的尺度模型大小。本文有助于探索大规模 DiT 模型的有效部署策略,证明了从头开始训练极低比特的 Diffusion Transformer 的可行性,同时保持与全精度模型相当的图像生成能力。

本文做了哪些具体的工作
受低比特 LLM 量化感知训练方案的启发,研究了三值 DiT 模型的 QAT 量化方法,并引入了 DiT 特异性改进来更好地训练。
将三值 DiT 模型从 600M 扩展到 4.2B 参数量,并根据现有的 2-bit CUDA Kernel 在 GPU 上进一步部署经过训练的三值 DiT,从而能够用少于 3GB GPU 显存完成 4.2B DiT 模型推理。使用现有的 2-bit CUDA Kernel 部署经过训练的三值 DiT 模型之后,模型 checkpoint size 约十倍减少;推理显存消耗约六倍减少。
在 ImageNet Benchmark 上与全精度模型相比,实现了很有竞争力的性能,证明本文方法的有效性。
1 TerDiT:三值 Diffusion Transformer
论文名称:TerDiT: Ternary Diffusion Models with Transformers (Arxiv 2024.05)
论文地址:
http://arxiv.org/pdf/2405.14854
代码链接:
http://github.com/Lucky-Lance/TerDiT
1.1 Diffusion Transformer 变大之后的部署难题
大规模预训练文生图像扩散模型可以成功生成复杂且保真度高的图片。值得注意的是,基于 Transformer 架构的扩散模型 (DiTs[1]) 推动了这个领域的进步。与其他扩散模型相比,Diffusion Transformer 已经证明了在更高计算量 (GFLOPs) 下实现较低 FID 分数的能力。最近的研究,比如 Stable Diffusion 3[2]等方法,突出了 Diffusion Transformer 的很不错的图像生成能力;以及在视频生成方面令人印象深刻的工作,比如 Sora[3]。
鉴于 Diffusion Transformer 模型令人印象深刻的性能,研究人员现在越来越深入理解这些模型的 Scaling Law,类似于大语言模型 (LLM)。例如,Stable Diffusion 3 模型的参数量从 800M 到 800B。此外,研究人员推测 Sora 可能拥有大约 3B 的参数。鉴于其巨大的参数数量,部署 DiT 模型通常很昂贵,尤其是在某些终端设备上。
为了解决部署困境,最近已经有一些关于扩散模型高效部署的工作,大部分侧重于模型量化。然而,目前的研究仍然存在两个主要缺点。首先,虽然已经有很多关注量化基于 U-Net 的扩散模型,但对于 Transformer 的扩散模型的量化方法仍然有限。其次,当前工作中最流行的方法大多严重依赖于训练后量化 (Post-Training Quantization, PTQ) 技术进行量化,导致性能下降,尤其是在位宽极低 (如2位和1位) 的情况下。然而,神经网络的低比特量化很重要,因为它可以显著减少部署所需的计算资源,特别是对于参数量较多的模型。
为了解决这些缺点,本文使用量化感知训练 (Quantization-Aware Training, QAT) 技术来实现大规模 DiT 模型的极低比特量化。LLM 领域讨论过大模型的低比特 QAT 方法。与全精度的模型相比,从头开始训练具有低比特 (比如二值或者三值) 的大语言模型也可以实现具有竞争力的性能。这些结果表明大模型中仍然存在显着的精度冗余,意味着 QAT 方案在大规模 DiT 模型的可行性。
1.2 Diffusion Transformer
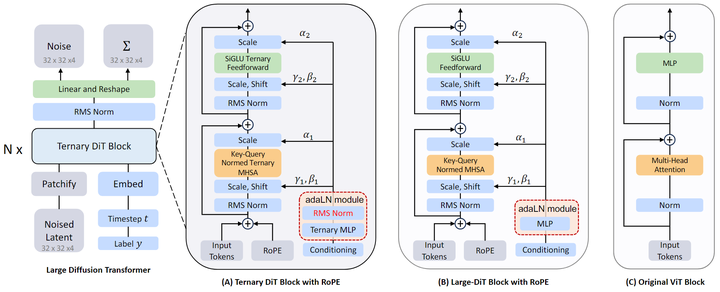
Diffusion Transformer (DiT[1]) 架构将扩散模型中常用的 U-Net Backbone 替换为对 latent patch 进行操作的 Transformer。与图 2(C) 所示的 Vision Transformer (ViT) 架构类似,DiT 首先将空间输入分成一系列 token,然后通过一系列的 Transformer Block 来执行去噪过程,如图 2(B) 所示。
为了处理额外的条件信息 (比如 noise timesteps tt 、class label ll 、自然语言输入),DiT 利用自适应归一化模块 adaptive normalization modules (adaLNZero) 将这些额外的条件输入插入到 Transformer Block 中。在最终的 Transformer Block 之后,应用标准线性解码器来预测最终的噪声和协方差。DiT 模型可以以与基于 U-Net 的扩散模型相同的方式进行训练。
DiT 中的 AdaLN 模块
DiT 与传统 ViT 的主要区别在于需要注入条件信息进行图像生成。DiT 在每个 Transformer Block 中使用零初始化的自适应层归一化 (adaLN-Zero) 模块,如图 2(B) 的红色部分所示,该模块从输入条件 计算维度缩放和移位值:
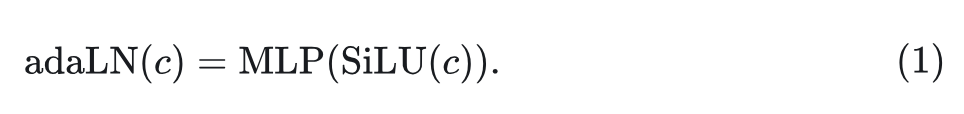
AdaLN 是 DiT 模型的重要组成部分,已被证明比 Cross-Attention 和 in-context conditioning 方法更有效。在 DiT 架构中,adaLN 模块集成了具有大量参数的 MLP 层,约占模型总参数的 10% 到 20%。在 TerDiT 的训练中,作者观察到该模块的直接权重三值化会产生不希望的训练结果。
1.3 模型量化
理解 DiT 模型的 Scaling Law 已被证明对于开发和优化 LLM 至关重要。在最近的探索中,Large-DiT [23] 通过结合 LLaMA 和 DiT 方法,成功地将模型参数从 600M 扩展到 7B。结果表明,参数的缩放可以潜在地提高模型性能并提高 ImageNet label-conditioned 生成任务的收敛速度。受此启发,作者进一步研究 DiT 模型的三值化,这可以减轻与部署大规模 DiT 模型相关的挑战。
为了构建三值量化的 DiT 模型,作者将原始 Large-DiT 的 self-attention, feedforward, 以及 MLP 中的所有线性层替换为三值线性层,得到一组三值 DiT Block,如图 2(A) 所示。对于三值线性层,作者采用了类似 BitNet b1.58[4]的 absmeanquantization 函数。首先,对权重矩阵进行归一化:把每个元素除以矩阵中所有元素的绝对值均值。归一化后,权重矩阵中的每个值都四舍五入到最接近的整数并夹入集合: 。参考目前流行的 的量化方法 和 , 作者还将可学习的缩放参数 乘以量化后的每个三值的线性矩阵, 得到最终值为 。量化函数表示为:
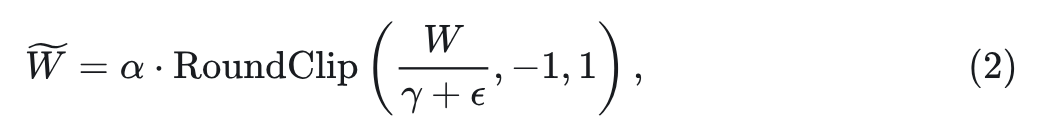
式中, 设为一个很小的值 (一般为 )。
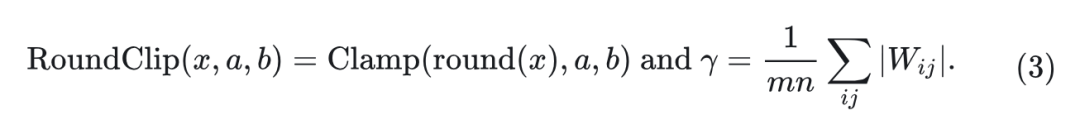
TerDiT 是一种仅权重量化方案,本文不量化激活值。
量化感知训练策略
基于上述量化函数,作者使用 Straight-Through Estimator (STE)[7]从头开始训练 DiT 模型,允许梯度通过不可微的组件传播。在整个训练过程中保留网络的全精度参数。对于每个训练步骤,通过前向传递中的三值量化函数从全精度参数计算三值权重,并将三值权重的梯度直接应用于全精度参数,以便在后向传递中进行参数更新。
然而,作者发现收敛速度非常慢。即使在许多训练迭代之后,损失也不能降低到合理的范围。作者发现这个问题可能源于三值线性层通常会导致较大的激活值的特征,并基于 QAT 的模型结构改进这个问题。
1.4 QAT 特定的模型架构改进
三值线性层的激活分析
在三值线性层中,所有参数从集合 中获取一个值。通过这一层的值将成为较大的激活值,这可能会阻碍神经网络的稳定训练。作者定性地证明三元线性权重对激活值的影响。
作者随机初始化一个三值线性层,将输入特征维度设置为 1024,输出特征维度为 9216 (对应 Large-DiT 中 adaLN 模块的线性层)。权重参数通过量化函数,并输入一个值全部为1的大小为 512×1024 的矩阵输入。激活分布框图如图3中心部分所示。
作者还计算了把这个输入矩阵通过一个全精度线性层的激活分布,如图3右侧所示。可以看出,与全精度线性层相比,三值线性层导致激活值非常大。
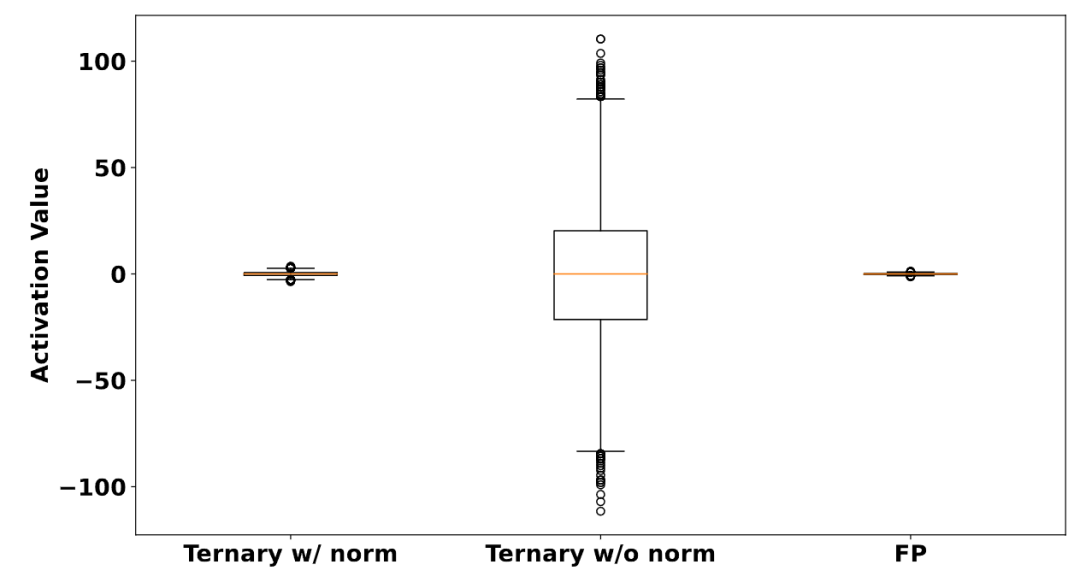
通过将 Layer Norm 应用于三值线性层的输出,可以缓解三值线性权重带来的大激活值的问题。作者在三值线性层之后添加一个 RMS Norm,并获得如图3左侧的激活值分布。激活值在通过归一化层后缩放到合理的范围,并导致更稳定的训练行为。观察结果也与[8]一致,其在每个量化线性层的激活量化之前应用层 Layer Normalization 函数。
RMS 归一化的 AdaLN 模块
在标准 ViT Block 中,Layer Normalization 被应用于每个 Self-attention 层和 Feed-forward 层。DiT 中的 Self-attention 层和 Feed-forward 层也是这样,有助于正确缩放激活值的范围。但由于 AdaLN 模块 的存在,DiT 不同于传统的 Transformer Block。AdaLN 模块没有应用归一化。在全精度训练的背景下,没有层归一化没有显着影响。然而,对于三值 DiT 架构,它的缺失会导致 adaLN 模块中的 scale 和 shift 值很大,这对模型训练产生了不良影响。为了缓解这个问题,作者在每个三值 DiT Bloc 中 adaLN 模块的 MLP 层之后引入了一个 RMS Norm:
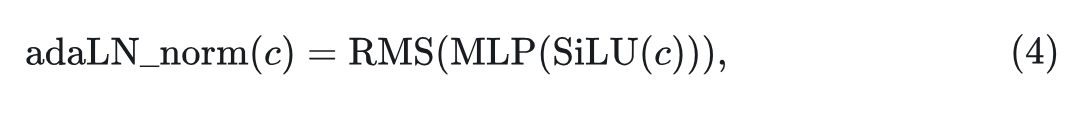
TerDiT 的最终模型结构如图 2(A) 所示。这种微小的修改可以导致更快的收敛速度和较低的训练损失,从而获得更好的定量和定性评估结果。
1.5 部署策略
作者发现三值网络目前没有有效的开源部署解决方案。在这种情况下,作者使用 2-bit 实现部署经过训练的网络。具体来说,将三值线性权重打包到 int8 值 (4 个三值表征到1个 int8) 中,其中包含[9]提供的 Package_2bit_u8() 函数。在 DiT 的推理过程中,动态调用 unpack_2bit_u8() 函数,将打包的 2-bit 数恢复为浮点值,然后进行后续计算。
1.6 实验设置
本文的 DiT 实现基于 Large-DiT-ImageNet 的开源代码[10],作者分别在 600M (DiT-XL/2) 和 4.2B (Large-DiT-4.2B) 参数的三值 DiT 模型上进行了实验。
在本文之前,DiT 量化的工作还没发现。因此,本文主要与有代表性的全精度扩散模型进行比较。
作者按照原始 DiT的评估设置,在 ImageNet 数据集上训练 600M 和 4.2B 的三值 DiT。由于计算资源的限制,作者在 256×256 分辨率下评估模型。作者将 TerDiT 与一系列全精度扩散模型进行比较,遵循[11]的做法报告 50K 生成的图像计算的 FID、sFID、Inception Score、Precision 和 Recall。作者还在训练阶段提供了图像的总数,以进一步了解不同生成模型的收敛速度。
训练细节: 作者在8个 A100-80G GPU 上训练 600M 的 TerDiT 模型 1750K iterations,Batch Size 为 256,16 个 A100-80G GPU 上训练 4.2B 模型 1180K iterations,Batch Size 为 512。作者将初始学习率设置为 5e-4。在 600M 模型训练 1550k 步和 4.2B 模型的 550k 步后,将学习率降低到 1e-4 以获得更细粒度的参数更新。
1.7 实验结果
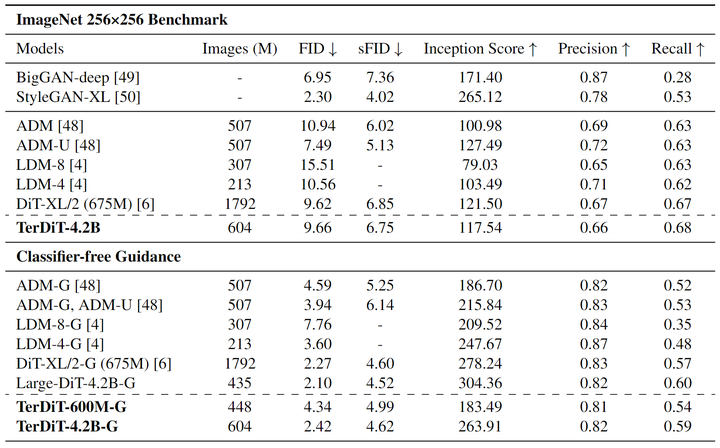
评估结果列于图4中。在不使用 classifier-free guidance 的情况下,TerDiT-4.2B 实现了与 DiT-XL/2 相当的测试结果,且训练图像的数量要少得多。在使用 classifier-free guidance 的情况下 (cfg=1.5),TerDiT-4.2B-G 优于 LDM-G,同时与两个全精度 DiT 结构模型相比,只有非常轻微的性能下降。此外,TerDiT-4.2B-G 比 TerDiT-600M-G 实现了更好的结果,这意味着具有更多参数的模型在量化后会导致更小的性能下降。
为了直观地展示 TerDiT 的有效性,作者还在图5中展示了一些定性比较结果,涉及 TerDiT-4.2B、DiT-XL/2 和 Large-DiT4.2B。在视觉感知方面,TerDiT 生成的图像与全精度模型生成的图像没有显著差异。

部署效率比较
部署效率的提高是 TerDiT 提出的动机。作者提供了 TerDiT-600M/4.2B、DiT-XL/2 和 Large-DiT-4.2B 之间的比较,以讨论 TerDiT 可以带来的实际部署效率。图6展示了4个 DiT 模型的 Checkpoint Size。作者还在单个 A100-80G GPU 上记录总的扩散样本循环 (steps=250) 的 Memory Usage 和 Inference Time。
可以看出,TerDiT 大大减少了 Checkpoint Size 和 Memory Usage。4.2B 的三值 DiT 模型的 Checkpoint Size 和 Memory Usage 明显小于 Large-DiT-4.2B 的,甚至小于 DiT-XL/2。这为在终端设备 (如手机) 上部署模型带来了显著的优势。由于所需的解包操作,观察到推理速度变慢。

RMS 归一化的 AdaLN 模块的讨论
作者在 256×256 分辨率的 ImageNet 数据集上训练具有 600M 和 4.2B 参数的三值 DiT 模型。对于每个参数大小训练了两个模型,一个在 adaLN 模块中使用 RMS Norm,一个没有。作者记录训练期间的损失曲线,并每 100K 个训练步骤测量 FID-50K 分数 (cfg=1.5)。为了公平比较,作者在 8 个 A100-80G GPU 上训练所有三值 DiT 模型,Batch Size 设置为 256。在整个训练过程中,学习率设置为 5e-4。
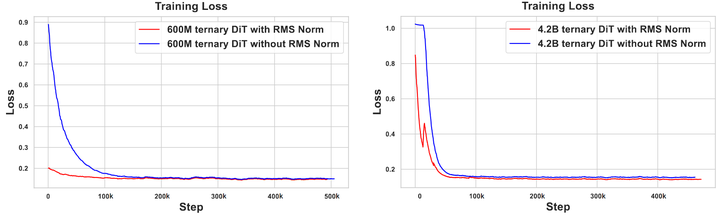
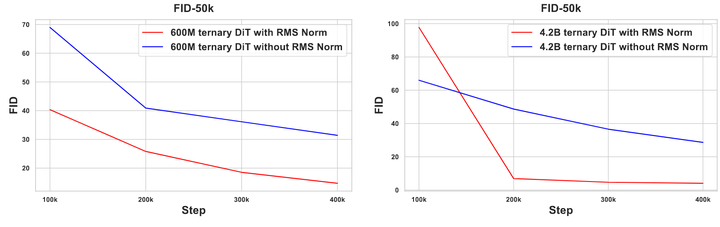
如图7和8所示为 training loss 和 FID-50K 分数。可以看出,使用 RMS Normalized adaLN 模块训练可以实现更快的收敛速度和更低的 FID 分数。另一个观察结果是,与参数较少的模型相比,具有更多参数的模型往往实现更快、更好的训练。
参考
^abScalable Diffusion Models with Transformers
^Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
^https://openai.com/index/sora/
^The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
^Gptq: Accurate post-training quantization for generative pre-trained transformers
^Awq: Activation-aware weight quantization for llm compression and acceleration
^Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
^BitNet: Scaling 1-bit Transformers for Large Language Models
^Half-quadratic quantization of large machine learning models
^https://github.com/Alpha-VLLM/LLaMA2-Accessory/tree/main/Large-DiT-ImageNet
^Diffusion Models Beat GANs on Image Synthesis

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)
















 1495
1495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









