







问题:如何区分苹果和橘子?
假设我们现在以水果的图片为基础,我们该如何辨别出是哪一种水果。

常见的方法:将橘子的像素点相加,然后比较绿色像素点的数量。这个比例可以帮你判断这是哪种水果。
针对一些简单的图片时算法工作正常,但是对于一些个例的时候可能会出错,为此,你可能需要写成千上万条规则来识别。
假如我现在又要分析香蕉和橘子了,那么我需要编写新的规则,好痛苦。。。
我们需要一种算法,可以自动生成规则,这样我们就不需要一条条的去写,这就需要机器学习来大展身手了。
机器学习分类
机器学习算法可以被分为三大类:
- 监督学习(supervised learning)
- 非监督学习(unsupervised learning)
- 强化学习(Reinforcement learning)
监督学习在数据集(训练集)的属性(标签)已知的条件下是有用的,但是在没有标签时,就失去作用了,需要使用其他方法来进行预测。
当我们面临的是没有标记的数据(属性没有预先赋值),并且需要我们发现其中隐含的关系时,非监督学习就会很有用。
强化学习介于这两者之间——对于每一个预测步骤或动作,都会有某种形式的反馈,但是没有确切的标签或着错误信息。
使用开源库
我这里使用的开源库是 scikit-learn
可以通过 pip 安装
pip install -U scikit-learn或者 conda:
conda install scikit-learn也可以使用第三方安装, Canopy 和 Anaconda 带有最新版的 scikit-learn, 并带有 Windows,Mac OSX,和 Linux 平台大量科学的 python 库。
scikit-learn 依赖:
- Python (>= 2.6 or >= 3.3)
- NumPy (>= 1.6.1)
- SciPy (>= 0.9)
监督学习的步骤:
- 收集训练数据
- 用数据训练分类器
- 预测新数据的种类
这里用到的分类器类型是决策树,训练算法包含在分类器实例中,叫做Fit。
使用鸢尾花数据集
鸢尾花数据集有 5 个特征,分别是:花萼的长度、花萼的宽度、花瓣的长度、花瓣的宽度、鸢尾花的种类。
我们使用鸢尾花的数据集来测试下:
import numpy as np
from sklearn.datasets import load_iris
from sklearn import tree
import pydotplus
# 载入 iris 数据集
iris = load_iris()
test_idx = [0, 50, 100]
# 训练数据
train_target = np.delete(iris.target, test_idx)
train_data = np.delete(iris.data, test_idx, axis=0)
# 测试数据
test_target = iris.target[test_idx]
test_data = iris.data[test_idx]
# 建立决策树分类器
clf = tree.DecisionTreeClassifier()
# 训练
clf.fit(train_data, train_target)
print test_target
print clf.predict(test_data)
# 结果可视化
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")我们来查看结果
# evince-previewer iris.pdf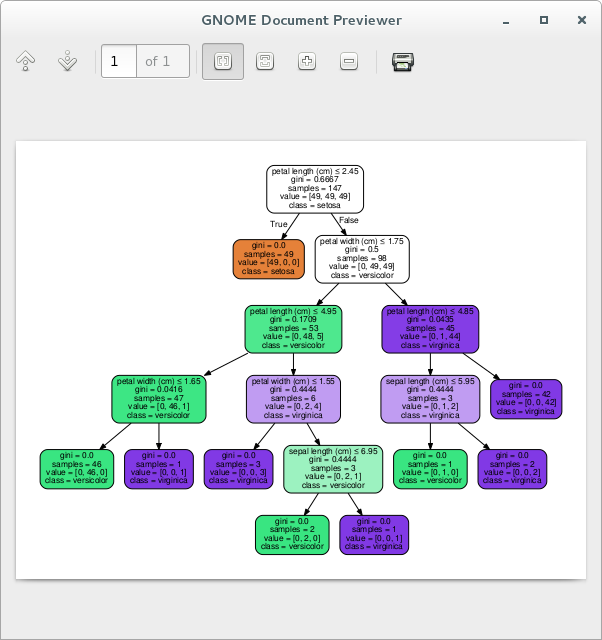
注: 执行程序时可能会报某些模块缺失,安装即可















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









