







总述
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
目标识别有两大经典结构:
- 第一类是以Faster RCNN为代表的两级识别方法,这种结构的第一级专注于proposal的提取,第二级则对提取出的proposal进行分类和精确坐标回归。两级结构准确度较高,但因为第二级需要单独对每个proposal进行分类/回归,速度就打了折扣;
- 第二类结构是以YOLO和SSD为代表的单级结构,它们摒弃了提取proposal的过程,只用一级就完成了识别/回归,虽然速度较快但准确率远远比不上两级结构。
那有没有办法在单级结构中也能实现较高的准确度呢?Focal Loss就是要解决这个问题。
为什么单级结构的识别准确度低
作者认为单级结构准确度低是由类别失衡(class imbalance)引起的。计算Loss的bbox可以分为 positive 和 negative 两类。当bbox(由anchor加上偏移量得到)与ground truth间的IOU大于上门限时(一般是0.5),会认为该bbox属于positive example,如果IOU小于下门限就认为该bbox属于negative example。在一张输入image中,目标占的比例一般都远小于背景占的比例,所以两类example中以negative为主,这引发了两个问题:
- negative example过多造成它的loss太大,以至于把positive的loss都淹没掉了,不利于目标的收敛;
- 大多negative example不在前景和背景的过渡区域上,分类很明确(这种易分类的negative称为easy negative),训练时对应的背景类score会很大,换个角度看就是单个example的loss很小,反向计算时梯度小。梯度小造成easy negative example对参数的收敛作用很有限,我们更需要loss大的对参数收敛影响也更大的example,即hard positive/negative example。
- 这里要注意的是前一点我们说了negative的loss很大,是因为negative的绝对数量多,所以总loss大;后一点说easy negative的loss小,是针对单个example而言。
Faster RCNN的两级结构可以很好的规避上述两个问题:
- 会根据前景score的高低过滤出最有可能是前景的example (1K~2K个),因为依据的是前景概率的高低,就能把大量背景概率高的easy negative给过滤掉,这就解决了前面的第2个问题;
- 会根据IOU的大小来调整positive和negative example的比例,比如设置成1:3,这样防止了negative过多的情况(同时防止了easy negative和hard negative),就解决了前面的第1个问题。
所以Faster RCNN的准确率高。
OHEM是近年兴起的另一种筛选example的方法,它通过对loss排序,选出loss最大的example来进行训练,这样就能保证训练的区域都是hard example。这个方法有个缺陷,它把所有的easy example都去除掉了,造成easy positive example无法进一步提升训练的精度。
Focal Loss
Focal Loss的目的:消除类别不平衡 + 挖掘难分样本
Focal loss是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失:
C E ( p , y ) = { − l o g ( p ) , y = 1 − l o g ( 1 − p ) , y = o t h e r w i s e . CE(p,y)=\left\{\begin{matrix} -log(p),&y=1 & & \\ -log(1-p),&y=otherwise \end{matrix}\right.. CE(p,y)={−log(p),−log(1−p),y=1y=otherwise.
可以进行如下定义:
p t = { p , y = 1 1 − p , y = o t h e r w i s e . p_t=\left\{\begin{matrix} p,&y=1 & & \\ 1-p,&y=otherwise \end{matrix}\right.. pt={p,1−p,y=1y=otherwise.
就可以得到:
C E ( p t ) = − l o g ( p t ) CE(p_t)=-log(p_t) CE(pt)=−log(pt)
对于这个公式,Pt越大,代表越容易分类,也就是越接近target。
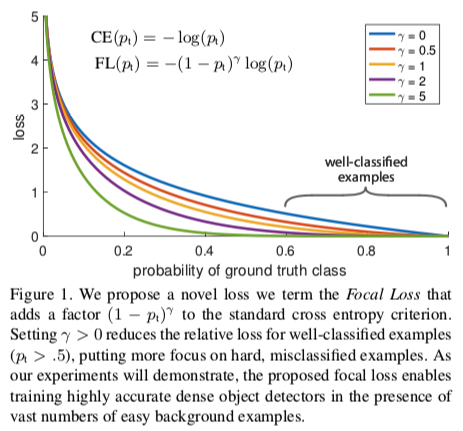
CE曲线是下图中的蓝色曲线,可以看到,相比较其他曲线,蓝色线条是变化最平缓的,即使在p>0.5(已经属于很好区分的样本)的情况下,它的损失相对于其他曲线仍然是高的,也许你会说,它相对于自己前面的已经下降很多了,对,是下降很多了,然后呢?看似每一个是微不足道,但是当数量巨大的易区分样本损失相加,就会主导你的训练过程而忽略hard examples
Balanced Cross Entropy
那怎么解决类不平衡呢?常见的思想是引入一个权重因子 α ,α ∈[0,1],当类标签是1是,权重因子是α ,当类标签是-1时,权重因子是1-α 。同样为了表示方便,用 a t a_t at 表示权重因子,那么此时的损失函数被改写为:
C E ( p t ) = − α t l o g ( p t ) CE(p_t)=-α_t log(p_t) CE(pt)=−αtlog(pt)
Focal Loss Definition
解决了正负样本的比例失衡问题(positive/negative examples),但是这种方法仅仅解决了正负样本之间的平衡问题,并没有区分简单还是难分样本(easy/hard examples),那么怎么去抑制容易区分的负样本的泛滥呢?不然整个训练过程都是围绕容易区分的样本进行,而被忽略的难区分的样本才是训练的重点。这时需要再引入一个调制因子,公式如下:
C E ( p t ) = − ( 1 − p t ) γ l o g ( p t ) CE(p_t)=-(1-p_t)^{γ} log(p_t) CE(pt)=−(1−pt)γlog(pt)
γ γ γ 也是一个参数,范围在[0,5],观察上式可以发现,当 p t p_t pt 趋向于1时,说明该样本比较容易区分,整个调制因子是趋向于0的,也就是loss的贡献值会很小;如果某样本被错分,但是 p t p_t pt 很小,那么此时调制因子是趋向1的,对loss没有大的影响(相对于基础的交叉熵),参数 γ γ γ 能够调整权重衰减的速率。还是上面这张图,当 γ = 0 γ=0 γ=0 的时候,FL就是原来的交叉熵CE,随着 γ γ γ 的增大,调整速率也在变化,实验表明,在 γ = 2 γ =2 γ=2 时,效果最佳。
上述两小节分别解决了正负样本不平衡问题和易分,难分样本不平衡问题,那么将这两个损失函数组合起来,就是最终的Focal loss:
C E ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) CE(p_t)=-α_t(1-p_t)^{γ} log(p_t) CE(pt)=−αt(1−pt)γlog(pt)
它的功能可以解释为:通过 α t α_t αt 可以抑制正负样本的数量失衡,通过 γ γ γ 可以控制简单/难区分样本数量失衡。关于focal loss,有以下结论:
1、无论是前景类还是背景类, p t p_t pt越大,权重 ( 1 − p t ) r (1-p_t)^r (1−pt)r 就越小。也就是说easy example可以通过权重进行抑制。换言之,当某样本类别比较明确些,它对整体loss的贡献就比较少;而若某样本类别不易区分,则对整体loss的贡献就相对偏大。这样得到的loss最终将集中精力去诱导模型去努力分辨那些难分的目标类别,于是就有效提升了整体的目标检测准度
2、 α t α_t αt 用于调节positive和negative的比例,前景类别使用 a t a_t at 时,对应的背景类别使用 KaTeX parse error: Expected group after '_' at position 5: 1-at_̲;
3、 r r r和 α t α_t αt的最优值是相互影响的,所以在评估准确度时需要把两者组合起来调节。作者在论文中给出 r = 2 、 α t = 0.25 r=2、α_t=0.25 r=2、αt=0.25 时,ResNet-101+FPN作为backbone的结构有最优的性能。
此外作者还给了几个实验结果:
- 在计算 p t p_t pt 时用sigmoid方法比softmax准确度更高;
- Focal Loss的公式并不是固定的,也可以有其它形式,性能差异不大,所以说Focal Loss的表达式并不crucial。
RetinaNet
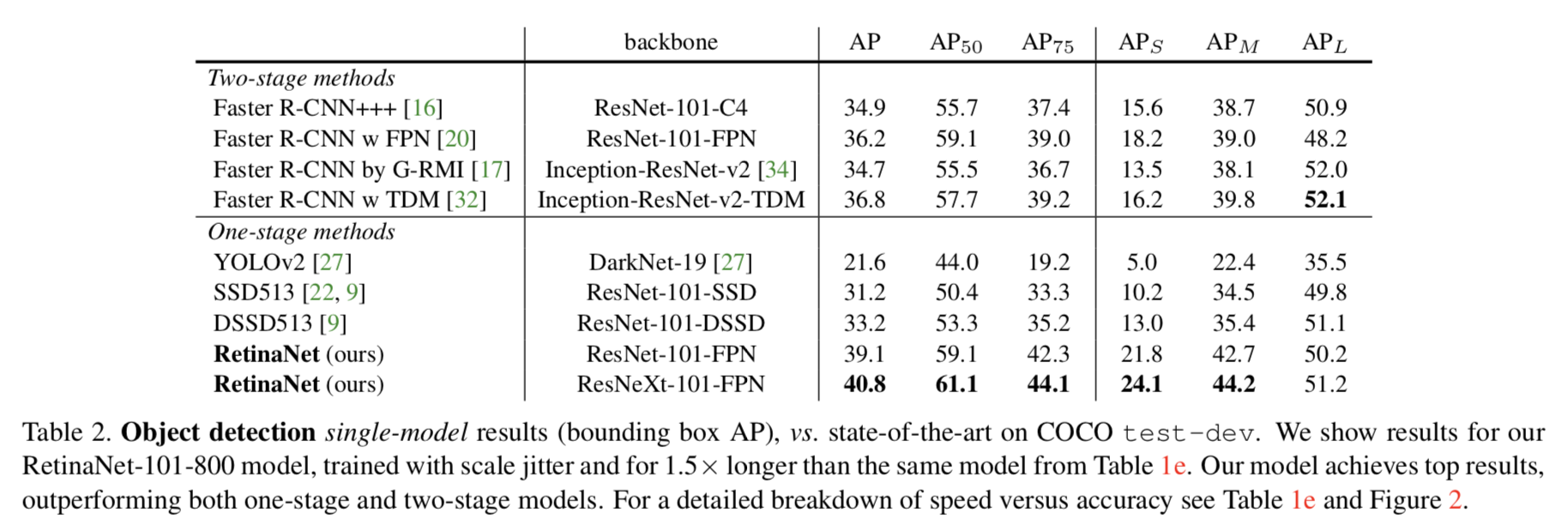
为了验证focal loss的有效性设计了一种one-stage的目标检测器RetinaNet,它的设计利用了高效的网络特征金字塔以及采用了anchor boxes,表现最好的RetinaNet结构是以ResNet-101-FPN为bakcbone,在COCO测试集能达到39.1的AP,速度为5fps;
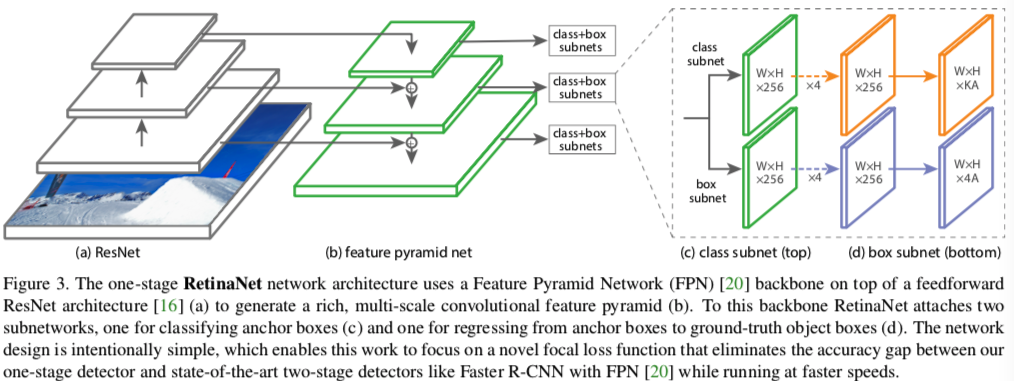
RetinaNet本质上是由 resnet+FPN+两个FCN子网络组成,设计思路是 backbone 选择vgg、resnet等有效的特征提取网络,主要尝试了resnet50、resnet101,FPN是针对resnet 里面形成的多尺度特征进行强化利用获得表达力更强包含多尺度目标区域信息的feature map,最后在 FPN 的feature map集合上分别使用两个结构相同但是不share参数的 FCN子 网络,从而完成目标框类别分类和bbox位置回归任务;
Anchor信息:与RPN网络类似,也使用anchors来产生proposals。特征金字塔的每层对应一个anchor面积。anchor的面积从 3 2 2 32^2 322 到 51 2 2 512^2 5122 在特征金字塔p3到p7等级上,在每一个level上都有三种不同的长宽比例{1:2,1:1,2:1},针对denser scale coverage,在每一个level的anchor集合上加入 2 0 , 2 1 / 3 , 2 2 / 3 {2^0, 2^{1/3}, 2^{2/3}} 20,21/3,22/3 三种不同的size;每一个anchor分配一个长度为K的vector作为分类信息,以及一个长度为4的bbox回归信息;
inference:前向推理阶段,即测试阶段,作者对金字塔每层特征图都使用0.05的置信度阈值进行筛选,然后取置信度前1000的候选框(不足1000更好) ,接下来收集所有层的候选框,进行NMS,阈值0.5
train:训练时,与GT的IOU大于0.5为正样本,小于0.4为负样本,否则忽略
Classification Subnet:分类子网对A个anchor,每个anchor中的K个类别,都预测一个存在概率。如下图所示,对于FPN的每一层输出,对分类子网来说,加上四层3x3x256卷积的FCN网络,最后一层的卷积稍有不同,用3x3xKA,最后一层维度变为KA表示,对于每个anchor,都是一个K维向量,表示每一类的概率,然后因为one-hot属性,选取概率得分最高的设为1,其余k-1为归0。传统的RPN在分类子网用的是1x1x18,只有一层,而在RetinaNet中,用的是更深的卷积,总共有5层,实验证明,这种卷积层的加深,对结果有帮助。
Box Regression Subnet:与分类子网并行,对每一层FPN输出接上一个位置回归子网,该子网本质也是FCN网络,预测的是anchor和它对应的一个GT位置的偏移量。首先也是4层256维卷积,最后一层是4A维度,即对每一个anchor,回归一个(x,y,w,h)四维向量。注意,此时的位置回归是类别无关的。分类和回归子网虽然是相似的结构,但是参数是不共享的。
模型的训练和部署:使用训练好的模型针对每个FPN level上目标存在概率最高的前1000bbox进行下一步的decoding处理,然后将所有level的bbox汇总,使用0.5threshold的nms过滤bbox最后得到目标最终的bbox位置;训练的loss由bbox位置信息L1 loss和类别信息的focal loss组成,在模型初始化的时候考虑到正负样本极度不平衡的情况对最后一个conv的bias参数做了有偏初始化;
注意几点:
- 训练时FPN每一级的所有example都被用于计算Focal Loss,loss值加到一起用来训练;
- 测试时FPN每一级只选取score最大的1000个example来做nms;
- 整个结构不同层的head部分共享参数,但分类和回归分支间的参数不共享
- 分类分支的最后一级卷积的bias初始化成 − l o g ( ( 1 − π ) / π ) -log((1-\pi)/\pi) −log((1−π)/π)
实验部分
参考
-
https://www.cnblogs.com/ziwh666/p/12494348.html















 884
884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









