







如何让 AI 智能控制电脑和手机?首先要让 AI 模仿人理解设备屏幕的内容,微软开源的 OmniParser 是一个专为图文信息解析任务设计的多模态模型,它支持图标检测、图标描述(Caption)、OCR 区域校验等任务,集成了 YOLOv8 和 FLORENCE/BLIP2 等主流视觉模型,协助 AI 看懂屏幕,从而进一步执行智能操作。本篇博客将从 安装配置、简单测试、原理解构 三个方面,全面解析 OmniParser 的使用与原理。跑通下面实例需要首选自行解决一些网络问题。
一、OmniParser 安装与环境配置
1. 克隆仓库并进入目录
git clone https://github.com/microsoft/OmniParser.git
cd OmniParser
2. 创建 环境(Python 3.12)
python -m venv omni
source omni/bin/activate # Windows 下使用 omni\Scripts\activate
3. 安装依赖
pip install -r requirements.txt
🚧 注意:某些依赖如
ultralytics会安装 YOLOv8 模型工具。
4. 下载模型权重
OmniParser 使用两个核心模型:YOLOv8(用于图标检测)与 FLORENCE2(用于图标描述)。使用以下命令下载预训练权重到 weights/ 文件夹下:
for f in icon_detect/{train_args.yaml,model.pt,model.yaml} icon_caption/{config.json,generation_config.json,model.safetensors}; do \
huggingface-cli download microsoft/OmniParser-v2.0 "$f" --local-dir weights; \
done
mv weights/icon_caption weights/icon_caption_florence
确保结构如下:
OmniParser/
├── weights/
│ ├── icon_detect/
│ └── icon_caption_florence/
二、模型测试:运行示例代码
OmniParser 提供了一个简单的 Jupyter Notebook 示例 demo.ipynb,但你也可以在 Python 脚本中测试核心功能:
加载图标模型
使用 YOLOv8
from util.utils import get_som_labeled_img, check_ocr_box, get_caption_model_processor, get_yolo_model
import torch
from ultralytics import YOLO
from PIL import Image
device = 'cpu'
model_path='weights/icon_detect/model.pt'
som_model = get_yolo_model(model_path)
som_model.to(device)
print('model to {}'.format(device))
som_model.device, type(som_model)
输出:
model to cpu
(device(type='cpu'), ultralytics.models.yolo.model.YOLO)
加载图标生成自然语言模型
可选 blip2 或 florence2
# two choices for caption model: fine-tuned blip2 or florence2
import importlib
from util.utils import get_som_labeled_img, check_ocr_box, get_caption_model_processor, get_yolo_model
caption_model_processor = get_caption_model_processor(model_name="florence2", model_name_or_path="weights/icon_caption_florence", device=device)
输出:
Florence2LanguageForConditionalGeneration has generative capabilities, as `prepare_inputs_for_generation` is explicitly overwritten. However, it doesn't directly inherit from `GenerationMixin`. From 👉v4.50👈 onwards, `PreTrainedModel` will NOT inherit from `GenerationMixin`, and this model will lose the ability to call `generate` and other related functions.
- If you're using `trust_remote_code=True`, you can get rid of this warning by loading the model with an auto class. See https://huggingface.co/docs/transformers/en/model_doc/auto#auto-classes
- If you are the owner of the model architecture code, please modify your model class such that it inherits from `GenerationMixin` (after `PreTrainedModel`, otherwise you'll get an exception).
- If you are not the owner of the model architecture class, please contact the model code owner to update it.
加载并识别图片
# reload utils
import importlib
import utils
importlib.reload(utils)
# from utils import get_som_labeled_img, check_ocr_box, get_caption_model_processor, get_yolo_model
image_path = 'imgs/Dify.png'
image = Image.open(image_path)
image_rgb = image.convert('RGB')
print('image size:', image.size)
box_overlay_ratio = max(image.size) / 3200
draw_bbox_config = {
'text_scale': 0.8 * box_overlay_ratio,
'text_thickness': max(int(2 * box_overlay_ratio), 1),
'text_padding': max(int(3 * box_overlay_ratio), 1),
'thickness': max(int(3 * box_overlay_ratio), 1),
}
BOX_TRESHOLD = 0.05
import time
start = time.time()
ocr_bbox_rslt, is_goal_filtered = check_ocr_box(image_path, display_img = False, output_bb_format='xyxy', goal_filtering=None, easyocr_args={'paragraph': False, 'text_threshold':0.9}, use_paddleocr=True)
text, ocr_bbox = ocr_bbox_rslt
cur_time_ocr = time.time()
dino_labled_img, label_coordinates, parsed_content_list = get_som_labeled_img(image_path, som_model, BOX_TRESHOLD = BOX_TRESHOLD, output_coord_in_ratio=True, ocr_bbox=ocr_bbox,draw_bbox_config=draw_bbox_config, caption_model_processor=caption_model_processor, ocr_text=text,use_local_semantics=True, iou_threshold=0.7, scale_img=False, batch_size=128)
cur_time_caption = time.time()
输出:
image size: (1800, 1302)
0: 928x1280 55 icons, 858.0ms
Speed: 5.6ms preprocess, 858.0ms inference, 5.4ms postprocess per image at shape (1, 3, 928, 1280)
len(filtered_boxes): 91 65
time to get parsed content: 56.14754319190979
显示识别后图片
import base64
import matplotlib.pyplot as plt
import io
plt.figure(figsize=(15,15))
image = Image.open(io.BytesIO(base64.b64decode(dino_labled_img)))
plt.axis('off')
plt.imshow(image)
输出:
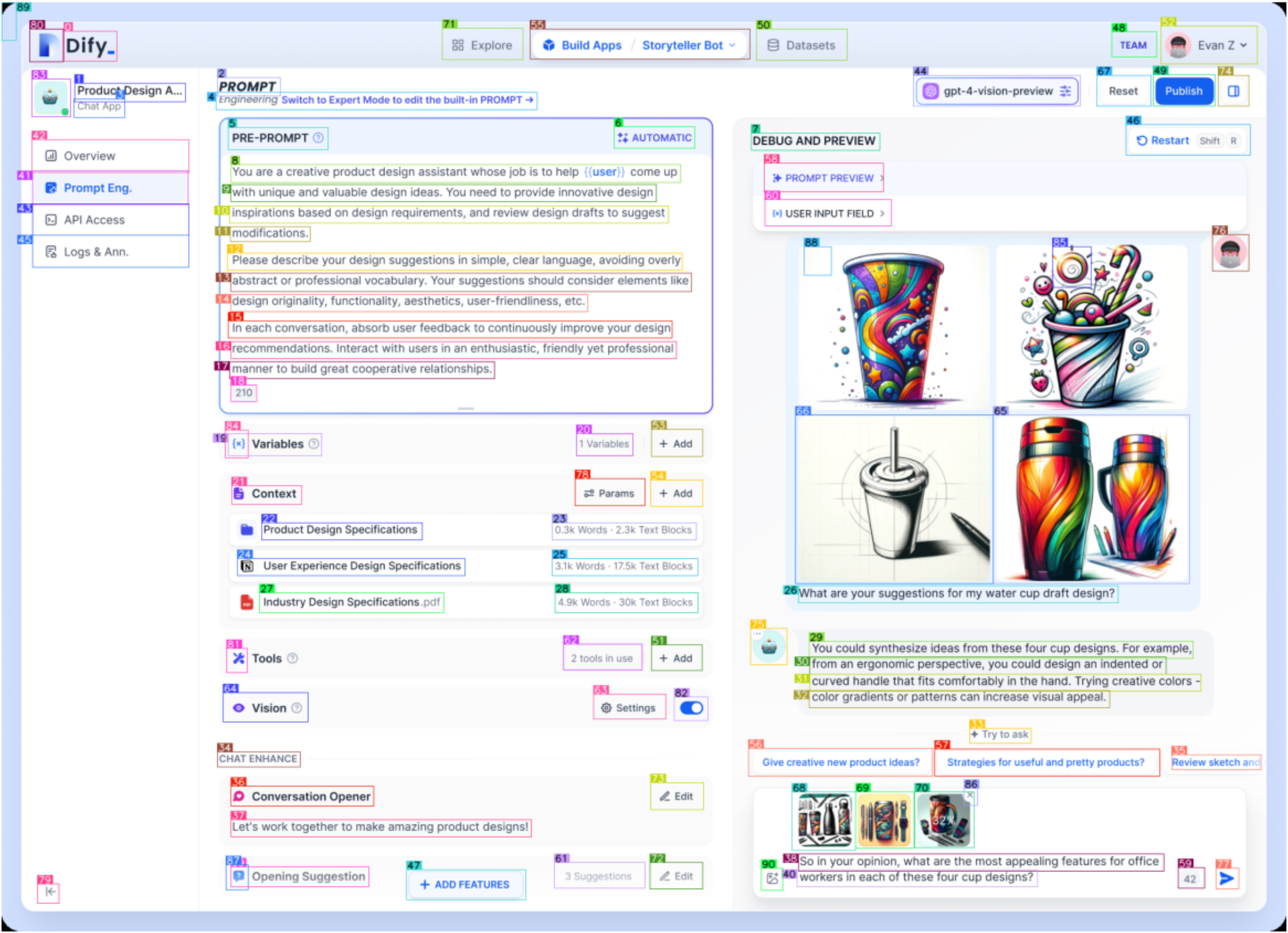
显示识别后的内容
import pandas as pd
df = pd.DataFrame(parsed_content_list)
df['ID'] = range(len(df))
df
输出:
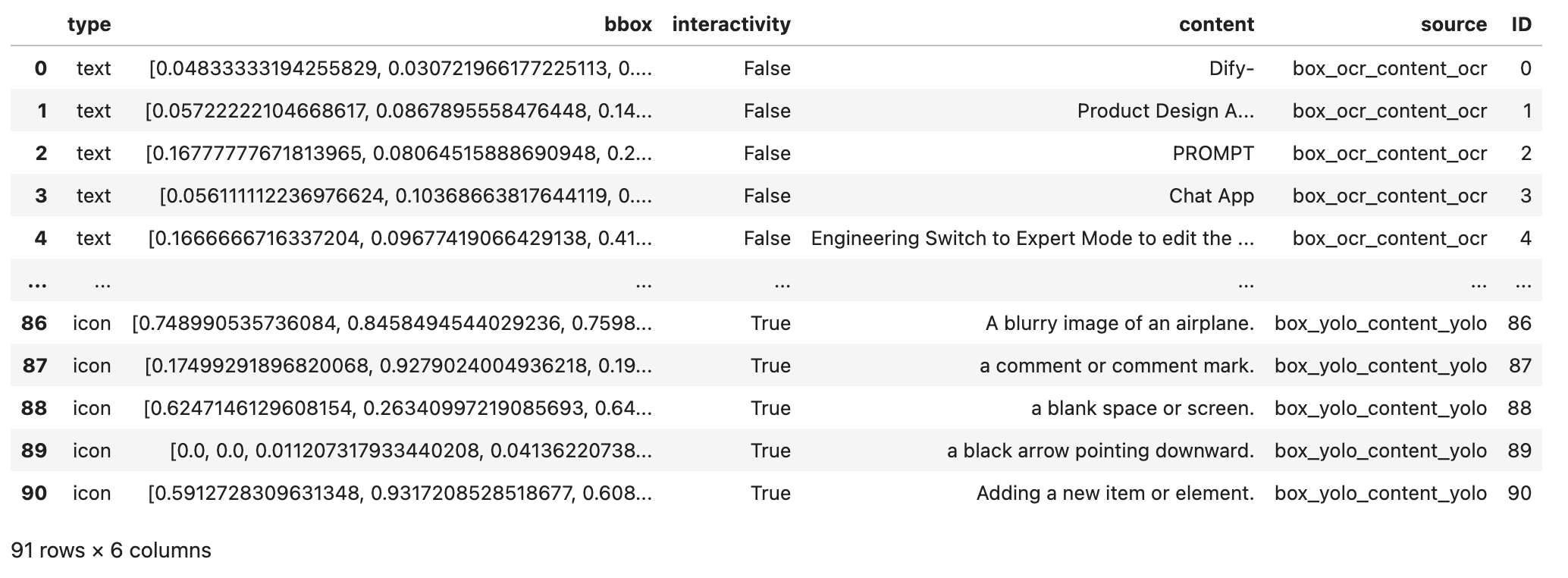
打印parsed_content_list结构
parsed_content_list
输出:
[{'type': 'text',
'bbox': [0.04833333194255829,
0.030721966177225113,
0.08944444358348846,
0.0629800334572792],
'interactivity': False,
'content': 'Dify-',
'source': 'box_ocr_content_ocr'},
{'type': 'text',
'bbox': [0.05722222104668617,
0.0867895558476448,
0.14277777075767517,
0.10675883293151855],
'interactivity': False,
'content': 'Product Design A...',
'source': 'box_ocr_content_ocr'},
......
]
三、OmniParser 背后原理解析
OmniParser 的目标是自动解析包含图表、图标、文本的复杂图文混合页面,特别适用于 PPT、PDF 报告、网页等视觉文档。
1. 模块划分与核心功能
| 模块 | 功能 | 使用模型 |
|---|---|---|
| 图标检测 | 检测图标位置及类别 | YOLOv8 |
| 图标描述 | 为每个图标生成自然语言描述 | Florence2(或 BLIP2) |
| OCR 校验 | 判断检测框是否为文本框 | OpenCV + OCR 辅助逻辑 |
2. 图标检测:YOLOv8
使用了训练好的 YOLOv8 模型 icon_detect/model.pt,其标签类型专门适配图表类图像(icon、chart、diagram 等)。优点是定位速度快,精度高,且支持多种尺寸。
# 模型预测
results = som_model(image_path)
boxes = results[0].boxes
3. 图标描述:Florence2 / BLIP2
Florence2 是微软推出的新一代图文生成模型,在多模态图像描述任务中表现优异。OmniParser 使用其对图标进行视觉特征提取 + 文本生成。
caption = caption_model_processor.generate_caption(image_crop)
可选使用 BLIP2,效果略低但部署更灵活。
4. 图文联合结构
OmniParser 支持输出如下结构:
{
"icon_boxes": [...], // 图标检测框
"captions": [...], // 每个图标的描述
"ocr_regions": [...] // 被识别为文本的区域
}
这为后续结构化解析(如知识图谱构建、文档摘要等)提供了良好的基础。
四、使用场景与扩展建议
💼 应用场景
- 文档图标自动识别与解读
- 财报、PPT 中图标自动注释
- 图文报告内容摘要生成
- 页面理解辅助视觉问答系统
🔧 可扩展方向
- 将检测框结果接入 OCR 文字识别系统(如 PaddleOCR、EasyOCR)
- 自定义图标类别与训练 YOLOv8
- 替换为轻量化描述模型部署在移动端
五、总结
OmniParser 是一个高度模块化、功能完善的图文解析工具包,结合了 YOLOv8 的检测能力与 Florence2 的语言生成能力,非常适合做复杂文档的结构化解析。本文我们完整走通了安装、测试流程,并对核心组件做了详细分析。
如果你有图文内容理解的需求,OmniParser 将是一个极具潜力的开源项目。
📌 项目地址:https://github.com/microsoft/OmniParser
📌 权重模型:https://huggingface.co/microsoft/OmniParser-v2.0
有任何问题欢迎留言探讨,后续我也会尝试做中文场景适配训练分享~

















 103
103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









