







在数据分析中,Pandas 的多层级索引(MultiIndex)功能允许用户创建复杂的数据结构,以便更好地组织和分析数据。多层级的 DataFrame 使得在多个维度上进行数据访问和操作变得更加灵活和高效。通过使用类似于 groupby 和 agg 的方法,用户可以轻松地对数据进行分组统计和描述性分析。掌握多层级的 DataFrame 是进行高级数据分析的重要技能,能够帮助分析师深入挖掘数据中的潜在信息。
1、分层索引
分层索引是 DataFrame 的重要特性,允许你在每个轴向上都可以拥有多个(两个或两个以上)索引层级。笼统地说,分层索引提供了一种在更低维度的形式中处理更高维度数据的方式。如下所示,我们看一个简单的分层索引的 DataFrame 对象
frame = pd.DataFrame(np.arange(12).reshape((4, 3)),
index=[['a', 'a', 'b', 'b'], ['one','two','one','two']],
columns=[['col1', 'col1', 'col2'],
['red', 'red', 'green']])
frame
# ---- 输出 ----
# col1 col2
# red red green
# a one 0 1 2
# two 3 4 5
# b one 6 7 8
# two 9 10 11我们可以通过 index 属性获取到 DataFrame 对象的行索引、通过 columns 属性获取到 DataFrame 对象的列索引, 如下所示,输出的是一个以 MultiIndex 对象的索引
frame.index
# ---- 输出 ----
# MultiIndex([('a', 'one'),
# ('a', 'two'),
# ('b', 'one'),
# ('b', 'two')],)
frame.columns
# ---- 输出 ----
# MultiIndex([('col1', 'red'),
# ('col1', 'red'),
# ('col2', 'green')],)当然分成的级别也可以有名字,我们可以在创建 DataFrame 对象时,定义行索引和列索引的名字,如下所示
index = pd.MultiIndex.from_tuples(
[('a', 'one'), ('a', 'two'), ('b', 'one'), ('b', 'two')],
names=['first', 'second'] # 设置索引名称
)
columns = pd.MultiIndex.from_tuples(
[('col1', 'red'), ('col1', 'green'), ('col2', 'blue')],
names=['main', 'sub'] # 设置列名称
)
# 创建 DataFrame
data = np.arange(12).reshape((4, 3))
frame = pd.DataFrame(data, index=index, columns=columns)
frame.index
# ---- 输出 ----
# MultiIndex([('a', 'one'),
# ('a', 'two'),
# ('b', 'one'),
# ('b', 'two')],
# names=['first', 'second'])
frame.columns
# ---- 输出 ----
# MultiIndex([('col1', 'red'),
# ('col1', 'green'),
# ('col2', 'blue')],
# names=['main', 'sub'])2、多层级数据获取
与 DataFrame 的基本查询一样,我们可以通过行索引和列索引组合进行数据查询,如下所示
# 获取分组
frame.loc['a']
# ---- 输出 ----
# col1 col2
# red red green
# one 0 1 2
# two 3 4 5
# 获取整行
frame.loc['a', 'two']
# ---- 输出 ----
# col1 red 3
# red 4
# col2 green 5
# Name: (a, two), dtype: int32
# 获取具体位置的值
frame.loc[('a', 'one'), ('col1', 'red')]
# ---- 输出 ----
# col1 red 0
# red 1
# Name: (a, one), dtype: int32
3、调换和层级排序
如果我们想对层级进行调换,可以使用 swaplevel 接收两个层级序号或层级名称,返回一个进行了层级变更的新对象(但是数据是不变的):
frame.swaplevel('first', 'second')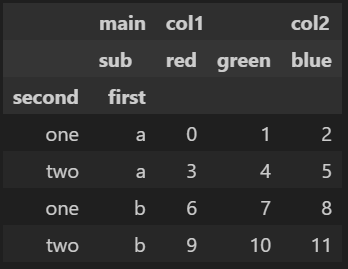
如果我们想根据层级名称进行排序,我们可以使用 sort_index 可以根据单一层级上对数据进行排序。
frame.sort_index(level=1)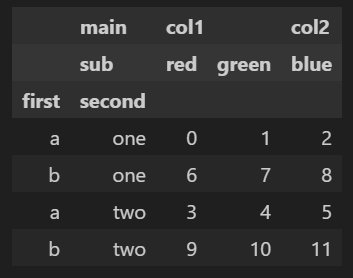
4、按层级进行汇总统计
DataFrame 中按层级进行描述性和汇总性统计可以通过 groupby 进行汇总,再调用描述性和汇总性统计的方法,如下所示,是按行索引层级进行计数统计,其它的描述性和汇总性统计的使用类似,我们不再分别赘述。
frame.groupby('first').count()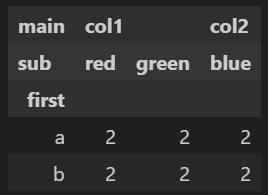
当然我们也可以按列索引层级进行计数统计,如下所示
frame.groupby('first')['col1'].count()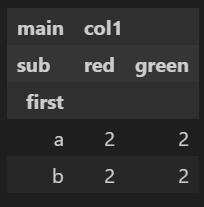
如果你喜欢本文,欢迎点赞,并且关注我们的微信公众号:Python技术极客,我们会持续更新分享 Python 开发编程、数据分析、数据挖掘、AI 人工智能、网络爬虫等技术文章!让大家在Python 技术领域持续精进提升,成为更好的自己!
添加作者微信(coder_0101),拉你进入行业技术交流群,进行技术交流


















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











