







这里写自定义目录标题
二分法
思想
每次和中间值进行比较(以中间点为分割点)
如果中间值小则取中间值右侧部分中间值继续比较
如果中间值大则取中间值左侧部分中间值继续比较
代码
public class BinarySearchFind {
public static void main(String[] args) {
int [] arr = {1,8, 10, 89, 1000, 1234};
int binarySearch = binarySearch(arr,0,arr.length-1,1234);
System.out.println(arr[binarySearch]);
}
private static int binarySearch(int[] arr, int left, int right,int searchValue) {
//代表数组中没有这个值
if(left>right){
return -1;
}
//取得中间值
int mid=(left+right)/2;
if(searchValue<arr[mid]){
//向左面进行查找
return binarySearch(arr,left,mid-1,searchValue);
}else if(searchValue>arr[mid]){
//向右面进行查找
return binarySearch(arr,mid+1,right,searchValue);
}else{
//返回位置
return mid;
}
}
}
插值查找算法
思想
和二分查找思想相同,
只是每次取的不是中间点(根据比例计算获得分割点)
如下图:中间切割点如下
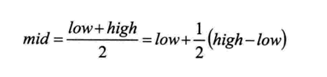
如下图:经过中间切割点思想 可以按比例获得切割点位置
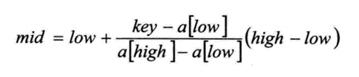
优点:对于数据量较大,关键字分布比较均匀的查找,采用插值查找, 速度比二分法快.
代码
public class BinarySearchFind {
public static void main(String[] args) {
int [] arr = {1,8, 10, 89, 1000, 1234};
int binarySearch = binarySearch(arr,0,arr.length-1,1234);
System.out.println(arr[binarySearch]);
}
private static int binarySearch(int[] arr, int left, int right,int searchValue) {
//代表数组中没有这个值
if(left>right){
return -1;
}
//取得中间值
int mid=left+(searchValue-arr[left])/(arr[right]-arr[left])*(right-left);
if(searchValue<arr[mid]){
//向左面进行查找
return binarySearch(arr,left,mid-1,searchValue);
}else if(searchValue>arr[mid]){
//向右面进行查找
return binarySearch(arr,mid+1,right,searchValue);
}else{
//返回位置
return mid;
}
}
}
斐波那契(黄金分割法)查找算法
思想
每次以0.618为分割点,在众多数据中的得到的数据更加完美,但速度较慢
代码
public class BinarySearchFind {
public static void main(String[] args) {
int [] arr = {1,8, 10, 89, 1000, 1234};
System.out.println("index=" + fibSearch(arr, 1234));
}
private static int fibSearch(int[] arr, int searchValue) {
//创建对应的斐波那契数组
int [] feiBoArr=new int[30];
CreateFibonacciArray(feiBoArr);
//找到数组长度对应的斐波那契数中的值
int k=0;
while(feiBoArr[k]<arr.length){
k++;
}
//将数组填充斐波那契长度,多出长度用0填充
int[] tempArr=Arrays.copyOf(arr, feiBoArr[k]);
//将最大数填充到数组末尾 [1, 8, 10, 89, 1000, 1234, 1234, 1234]
for(int i=arr.length;i<tempArr.length;i++){
tempArr[i]=arr[arr.length-1];
}
int left=0;
int right=tempArr.length-1;
while(left<right){
//中间坐标位置 =左面坐标+斐波纳契中间坐标
int mid=left+feiBoArr[k-1];
if(searchValue >tempArr[mid]){//要查找的值在右面
left=mid+1;
//1. 全部元素 = 前面的元素 + 后边元素
//2. f[x]=f[x-2]+f[x-1]
//其中f[x-2] 为左面部分,f[x-1]为右面部分
//f[x-2]<f[x-1], 右面部分大
//下次的分割点就是 f[x-1-1]
k--;
}else if(searchValue < tempArr[mid]){//要查找的值在左面
right=mid-1;
//1. 全部元素 = 前面的元素 + 后边元素
//2. f[x]=f[x-2]+f[x-1]
//其中f[x-2] 为左面部分,f[x-1]为右面部分
//f[x-2]<f[x-1], 左面部分小
//下次的分割点就是 f[x-2-1]
k--;
k--;
}else{
//因为后面有的数是填充的,如果匹配到填充的数,则直接返回数组最大索引
if(arr[arr.length-1]==tempArr[mid])
{
return arr.length-1;
}
return mid;
}
}
return -1;
}
/**
* 创建斐波那契数组
*/
public static void CreateFibonacciArray(int[] arr){
arr[0]=1;
arr[1]=1;
for(int i=2;i<arr.length;i++){
arr[i]=arr[i-1]+arr[i-2];
}
}
}
字符串暴力匹配算法
思想
每次只移动一位,若是不匹配,移动到下一位接着判断,浪费了大量的时间
代码
public class ViolenceMatch {
public static void main(String[] args) {
String str="asdfa asdfb asdfc asdfd";
String match="asdfc";
int index=violenceMatch(str,match);
System.out.println(index);
}
private static int violenceMatch(String str, String match) {
//每次匹配失败复原的位置
int temp=0;
//循环遍历每个字符
for(int i=0,j=0;i<str.length();i++){
temp=i;
while(str.charAt(i) == match.charAt(j)){
i++;
j++;
if(j == match.length()){
//返回匹配出来的位置
return i-match.length();
}
}
//这里应用回溯
i=temp;
j=0;
}
return -1;
}
}
kmp字符串匹配算法
思想
在匹配不成功时回溯的位置不是下一位,而是经过计算的指定位置
图解
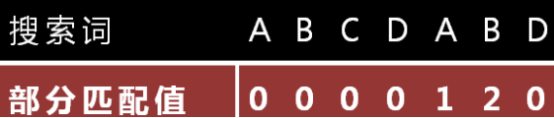
部分匹配值”就是”前缀”和”后缀”的最长的共有元素的长度。以”ABCDABD”为例
-”A”的前缀和后缀都为空集,共有元素的长度为0;
-”AB”的前缀为[A],后缀为[B],共有元素的长度为0;
-”ABC”的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
-”ABCD”的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
-”ABCDA”的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为”A”,A的长度为1;
-”ABCDAB”的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为”AB”,AB的长度为2;
-”ABCDABD”的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
代码
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









