









最近上模式识别的课需要做EM算法的作业,看了机器学习公开课及网上的一些例子,总结如下:(中间部分公式比较多,不能直接粘贴上去,为了方便用了截图,请见谅)
概要
适用问题
EM算法是一种迭代算法,主要用于计算后验分布的众数或极大似然估计,广泛地应用于缺损数据、截尾数据、成群数据、带有讨厌参数的数据等所谓不完全数据的统计推断问题。
优缺点
优点:EM算法简单且稳定,迭代能保证观察数据对数后验似然是单调不减的。
缺点:对于大规模数据和多维高斯分布,其总的迭代过程,计算量大,迭代速度易受影响;EM算法的收敛速度,非常依赖初始值的设置,设置不当,计算时的代价是相当大的;EM算法中的M-Step依然是采用求导函数的方法,所以它找到的是极值点,即局部最优解,而不一定是全局最优解。
原理
Jensen不等式

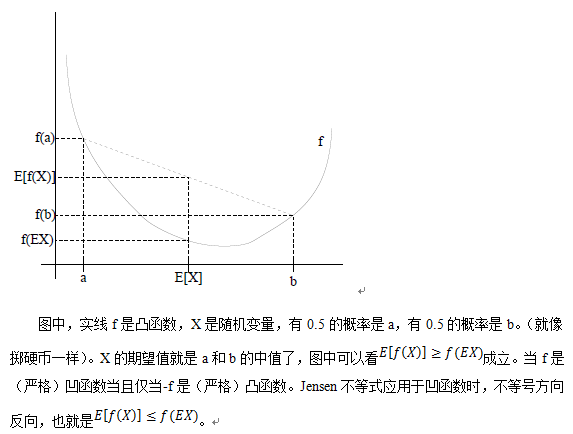







与ML估计的关系
EM算法的E-step是建立的下界,M-step是极大化下界,不断重复这两步直到收敛。最大似然估计是求参数的一种相当普遍的方法,但是它的使用场合是除了参数未知外,其它一切都已知,即不存在隐变量的情况。当存在隐变量时,我们可以通过EM算法,消掉隐变量,当期望取极大值时,最大似然函数也会在相同点取极大值。
具体模型应用
问题映射
用两个高斯函数生成数据,这两个高斯密度函数分别为N(1,2)和N(20,3.5),分别生成160和240个数据,也就是说其在混合模型中的权重分别为0.4 和 0.6。将这些数据放入同一数组中,经过EM算法可得出混合模型的密度函数及其权重。
代码
- clc;
- clear;
- %generate data fromnormal distribution.
- mu1= 1;
- sigma1= 2;
- R1 = normrnd(mu1,sigma1,160,1);
- mu2 = 20;
- sigma2 = 3.5;
- R2 = normrnd(mu2,sigma2,240,1);
- %merge
- R = [R1;R2];
- %shuffel
- r = randperm(size(R,1));
- R=R(r,:);
- figure,plot(R,'ro');
- %用两个高斯函数生成数据,这两个高斯密度函数分别为N(0,2)和N(20,3.5),分别生成160和240个数据,也就是说其在混合模型中的权重分别为0.4 和 0.6.
- [mu,sigma,phi] = mixGuassAnalysis(R,2,15);
clc;
clear;
%generate data fromnormal distribution.
mu1= 1;
sigma1= 2;
R1 = normrnd(mu1,sigma1,160,1);
mu2 = 20;
sigma2 = 3.5;
R2 = normrnd(mu2,sigma2,240,1);
%merge
R = [R1;R2];
%shuffel
r = randperm(size(R,1));
R=R(r,:);
figure,plot(R,'ro');
%用两个高斯函数生成数据,这两个高斯密度函数分别为N(0,2)和N(20,3.5),分别生成160和240个数据,也就是说其在混合模型中的权重分别为0.4 和 0.6.
[mu,sigma,phi] = mixGuassAnalysis(R,2,15);- function [mu,sigma,phi] =mixGuassAnalysis(sampleMatrix,k,maxIteration,epsilon)
- %UNTITLED Analysis the kguass distribution by the input matrix m
- %sampleMatrix the matrix of sample, in which each rowrepresents a sample.
- %k the number of guass distriubtion
- %maxIteration the max times of iteration,default 100.
- %epsilon the epsilon of loglikelihood,default 0.00001.
- %check parameters
- if nargin < 4
- epsilon = 0.00001;
- if nargin < 3
- maxIteration = 100;
- end
- end
- if k==1
- mu = mean(sampleMatrix);
- sigma = var(sampleMatrix);
- phi = 1;
- return;
- end
- [sampleNum,dimensionality] =size(sampleMatrix);
- %init k guassdistribution
- mu = zeros(k,dimensionality);
- for i=1:1:dimensionality
- colVector = sampleMatrix(:,i);
- maxV = max(colVector);
- minV= min(colVector);
- mu(1,i) = minV;
- mu(k,i) = maxV;
- for j=2:1:k-1
- mu(j:i) = minv+(j-1)*(maxV-minV)/(k-1);
- end
- end
- sigma =zeros(k,dimensionality,dimensionality);
- for i=1:1:k
- d = rand();
- sigma(i,:) = 10*d*eye(dimensionality);
- end
- phi = zeros(1,k);
- for i=1:1:k
- phi(1,i) = 1.0/k;
- end
- %the weight of sample iis generated by guass distribution j
- weight = zeros(sampleNum,k);
- oldlikelihood = -inf;
- for iter=1:maxIteration
- loglikelihood = 0;
- %E-step
- for i=1:1:sampleNum
- for j = 1:1:k
- weight(i,j)=mvnpdf(sampleMatrix(i,:),mu(j,:),reshape(sigma(j,:),dimensionality,dimensionality))*phi(j);
- end
- sum = 0;
- for j = 1:1:k
- sum = sum+weight(i,j);
- end
- loglikelihood = loglikelihood +log(sum);
- for j = 1:1:k
- weight(i,j)=weight(i,j)/sum;
- end
- end
- if abs(loglikelihood-oldlikelihood)<epsilon
- break;
- else
- oldlikelihood = loglikelihood;
- end
- %M-step
- %updatephi
- for i=1:1:k
- sum = 0;
- for j=1:1:sampleNum
- sum = sum+weight(j,i);
- end
- phi(i) = sum/sampleNum;
- end
- %updatemu
- for i=1:1:k
- sum = zeros(1,dimensionality);
- for j=1:1:sampleNum
- sum = sum+weight(j,i)*sampleMatrix(j,:);
- end
- mu(i,:) = sum/(phi(i)*sampleNum);
- end
- mu1(iter) = mu(1);
- mu2(iter) = mu(2);
- %updatesigma
- for i=1:1:k
- sum =zeros(dimensionality,dimensionality);
- for j=1:1:sampleNum
- sum = sum+ weight(j,i)*(sampleMatrix(j,:)-mu(i,:))'*(sampleMatrix(j,:)-mu(i,:));
- end
- sigma(i,:) = sum/(phi(i)*sampleNum);
- end
- end
- sigma = sqrt(sigma);
- end
function [mu,sigma,phi] =mixGuassAnalysis(sampleMatrix,k,maxIteration,epsilon)
%UNTITLED Analysis the kguass distribution by the input matrix m
%sampleMatrix the matrix of sample, in which each rowrepresents a sample.
%k the number of guass distriubtion
%maxIteration the max times of iteration,default 100.
%epsilon the epsilon of loglikelihood,default 0.00001.
%check parameters
if nargin < 4
epsilon = 0.00001;
if nargin < 3
maxIteration = 100;
end
end
if k==1
mu = mean(sampleMatrix);
sigma = var(sampleMatrix);
phi = 1;
return;
end
[sampleNum,dimensionality] =size(sampleMatrix);
%init k guassdistribution
mu = zeros(k,dimensionality);
for i=1:1:dimensionality
colVector = sampleMatrix(:,i);
maxV = max(colVector);
minV= min(colVector);
mu(1,i) = minV;
mu(k,i) = maxV;
for j=2:1:k-1
mu(j:i) = minv+(j-1)*(maxV-minV)/(k-1);
end
end
sigma =zeros(k,dimensionality,dimensionality);
for i=1:1:k
d = rand();
sigma(i,:) = 10*d*eye(dimensionality);
end
phi = zeros(1,k);
for i=1:1:k
phi(1,i) = 1.0/k;
end
%the weight of sample iis generated by guass distribution j
weight = zeros(sampleNum,k);
oldlikelihood = -inf;
for iter=1:maxIteration
loglikelihood = 0;
%E-step
for i=1:1:sampleNum
for j = 1:1:k
weight(i,j)=mvnpdf(sampleMatrix(i,:),mu(j,:),reshape(sigma(j,:),dimensionality,dimensionality))*phi(j);
end
sum = 0;
for j = 1:1:k
sum = sum+weight(i,j);
end
loglikelihood = loglikelihood +log(sum);
for j = 1:1:k
weight(i,j)=weight(i,j)/sum;
end
end
if abs(loglikelihood-oldlikelihood)<epsilon
break;
else
oldlikelihood = loglikelihood;
end
%M-step
%updatephi
for i=1:1:k
sum = 0;
for j=1:1:sampleNum
sum = sum+weight(j,i);
end
phi(i) = sum/sampleNum;
end
%updatemu
for i=1:1:k
sum = zeros(1,dimensionality);
for j=1:1:sampleNum
sum = sum+weight(j,i)*sampleMatrix(j,:);
end
mu(i,:) = sum/(phi(i)*sampleNum);
end
mu1(iter) = mu(1);
mu2(iter) = mu(2);
%updatesigma
for i=1:1:k
sum =zeros(dimensionality,dimensionality);
for j=1:1:sampleNum
sum = sum+ weight(j,i)*(sampleMatrix(j,:)-mu(i,:))'*(sampleMatrix(j,:)-mu(i,:));
end
sigma(i,:) = sum/(phi(i)*sampleNum);
end
end
sigma = sqrt(sigma);
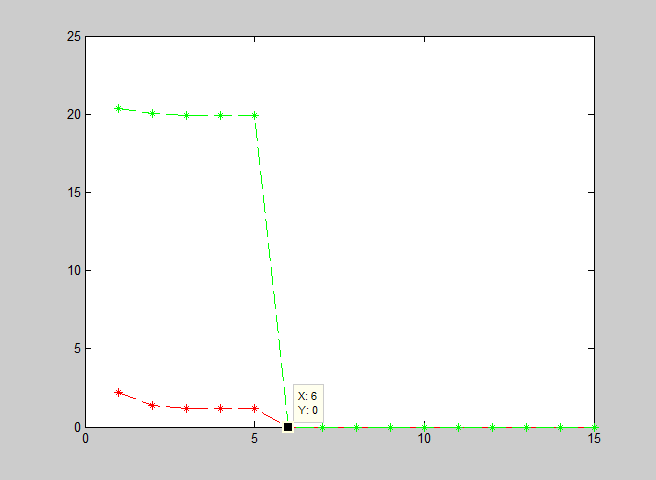
end迭代轨迹















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









