







😎 作者介绍:我是程序员行者孙,一个热爱分享技术的制能工人。计算机本硕,人工制能研究生。公众号:AI Sun,视频号:AI-行者Sun
🎈
本文专栏:本文收录于《AI实战中的各种bug》系列专栏,相信一份耕耘一份收获,我会把日常学习中碰到的各种bug分享出来,不说废话,祝大家早日中稿cvpr
🤓 欢迎大家关注其他专栏,我将分享Web前后端开发、人工智能、机器学习、深度学习从0到1系列文章。 🖥
随时欢迎您跟我沟通,一起交流,一起成长、进步!
问题
报错:subprocess.CalledProcessError: Command ‘[’/home/…/miniconda3/envs/cv2022/bin/python’, ‘-m’, ‘torch.distributed.run’, ‘–nproc_per_node’, ‘2’, ‘–master_port’, ‘34317’, ‘/home/…/.config/Ultralytics/DDP/_temp_6su8pijn140541848896384.py’]’ returned non-zero exit status 1

原因分析
在多卡训练YOLOv8时,如果遇到subprocess.CalledProcessError: Command‘[‘/home/... returned non-zero exit status 1.的错误,这通常意味着在执行多卡训练命令时,某个子进程失败了。这个问题可能由多种原因引起,包括但不限于:
-
环境配置问题:可能是由于Python环境、依赖包版本不兼容或未正确安装。
-
分布式训练参数设置不当:在使用
torch.distributed.launch或torch.distributed.run时,参数可能设置不正确。 -
代码错误:训练脚本中可能存在bug,导致训练无法正常进行。
-
资源限制:GPU资源不足或内存不足可能导致训练失败。
这个其实就是你本身显卡内存不够用了,用命令查看一下是否超内存了nvidia-smi
解决步骤
-
更新依赖:确保所有依赖包,特别是PyTorch,都是最新版本。
pip install --upgrade torch torchvision torchaudio -
检查环境变量:确保没有设置任何与分布式训练冲突的环境变量。
printenv | sort -
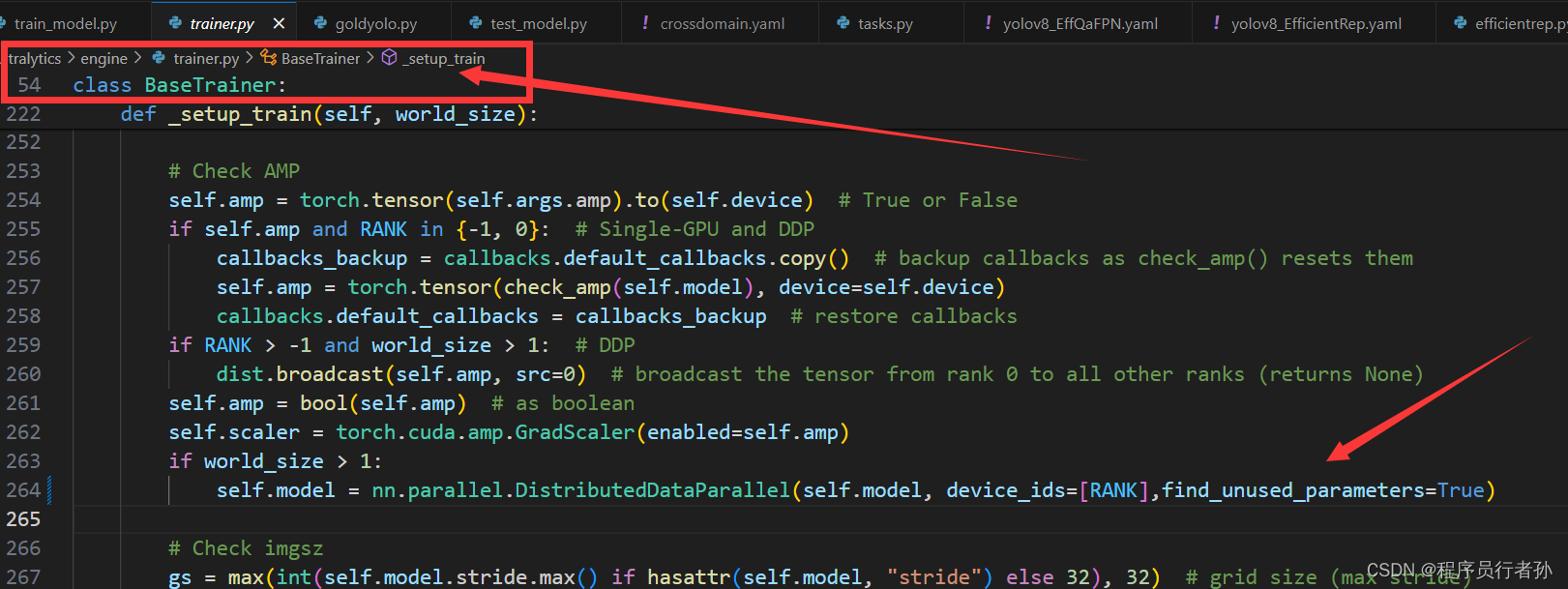
修改训练脚本:在YOLOv8的训练脚本中,特别是
train.py文件,检查是否有需要修改的地方,比如增加find_unused_parameters=True参数。self.model = DDP(self.model, device_ids=[RANK], find_unused_parameters=True)我这里加入位置为:ultralytics-main/ultralytics/engine/trainer.py 中的第264行(可能你们的不一样)
-
减少每个GPU上的进程数:如果每个GPU上的进程数过多,尝试减少进程数。
# 假设使用2个GPU,减少进程数 torch.distributed.launch --nproc_per_node 2 ... -
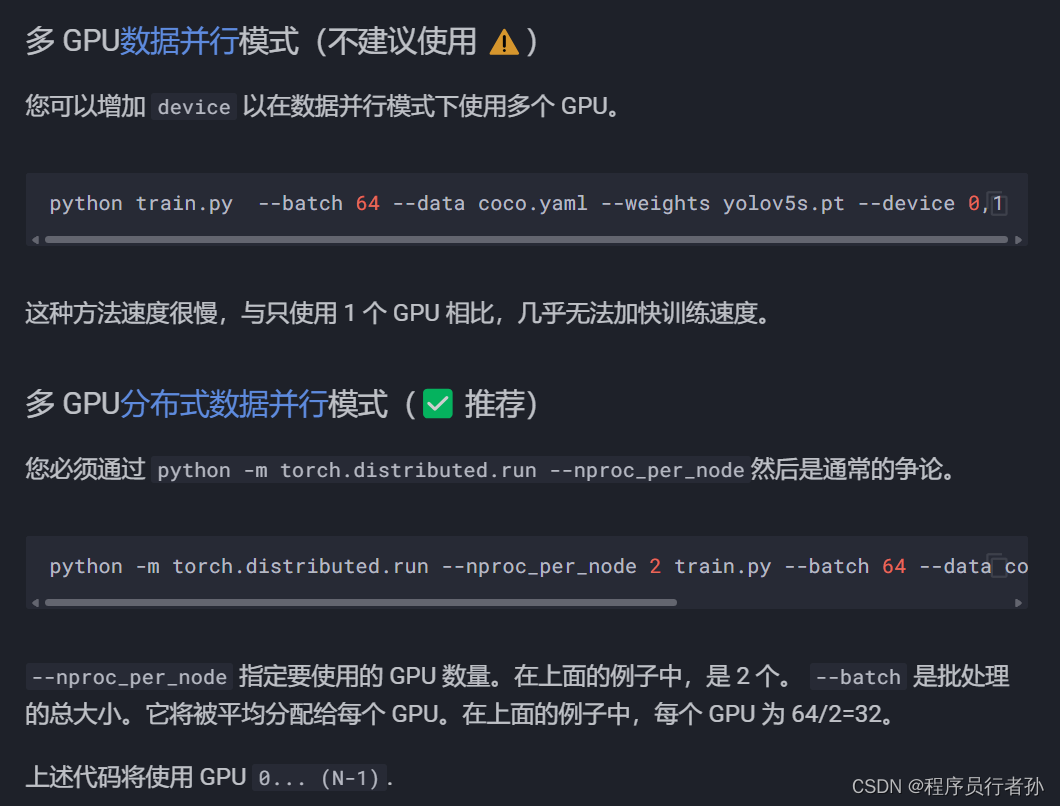
官方文档提供的另一种写法:大家用的都是上面这种
-
尝试在不同的机器上运行:如果可能,尝试在不同的机器上运行代码,以确定问题是否与特定的硬件或系统配置相关。
(这个可以尝试,在同学环境下如果可以使用,这就排除了你其他的问题)
祝大家实验顺利,有效涨点~
以上是此问题报错原因的解决方法,欢迎评论区留言讨论是否能解决,如果有用欢迎点赞收藏文章,博主才有动力持续记录遇到的问题!!!
免费资料获取
关注博主公众号,获取更多粉丝福利。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











