









Apache Beam技术愿景中,希望可以使用任意语言Beam SDK编写Beam Pipeline,然后可以运行在任何Runner中(每个Runner对应一个底层的大数据引擎,例如Flink Runner、Spark Runner)的能力,Apache Beam理论上可以视为一个VM虚拟机(想象一下Java的JVM,Scala、Groovy、Coljure等多种语言都可以在JVM中执行,可以运行在任何支持JAVA的操作系统中)。设计中通过两个可移植的层来实现这个目标:
- Runner API层提供了SDK和Runner无关的Pipeline定义。
- Fn API层,允许Runner调用使用特定语言SDK编写的UDF(用户自定义函数)
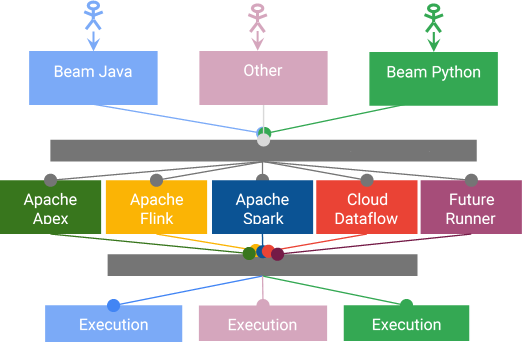
特别说明,Runner+ Fn API带来了以下的能力:
- 新的SDK可以运行在任何一个Beam Runner上
- 新的Beam Runner可以运行使用任何SDK编写的Pipeline
- (最终)在一个Pipeline中混合了使用不同SDK编写的转换代码,从此可以利用任何语言的数据源连接器类库等等。
为了让Fn API尽可能的有用,所以需要符合两个设计规范:
- 足够简单,能够允许SDK实现一个最小的Fn API集即可。
- 允许SDK能够通过额外的优化提升性能。
概括
执行一个用户编写的Pipeline可以分解成如下几个方面:
- 执行分组和触发逻辑,包括跟踪Watermark。
- 执行用户自定义函数UDF,包括自定义的Srouce/Sink,可切分的DoFn,普通的DoFn,窗口合并等等。
- 支持用户自定义函数中的旁路输入、状态和计时器、计数器等。
- Pipeline的执行管理,例如获取计数器信息、作业状态等等。
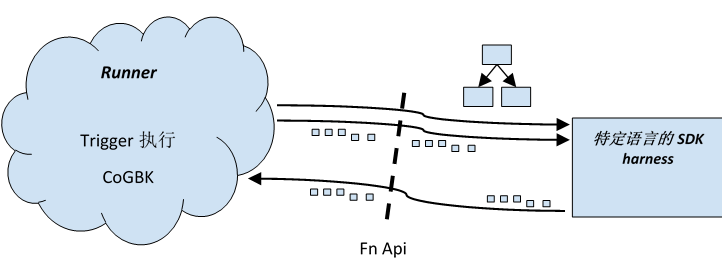
执行UDF是唯一一类需要特定需要在特定语言的SDK执行的。将UDF的执行移动到特定于语言的SDK Harness中,并且在两者之间使用RPC服务,可以获得跨语言/跨Runner移植性。
一个一个的执行UDF一定会性能非常差,所以设计的基本逻辑是对Pipeline的一个子图执行对元素的处理,如下图所示:
组件Components
在草图中提议使用docker容器来封装特定语言的SDK Harness。Runner负责启动、管理和销毁docker容器。如下的gRPC服务定义用来支持UDF的执行:
- 控制:低带宽的服务,用来通知SDK什么时候执行哪个UDF。也用来处理处理进度、任务切分、和计数。
- 数据:高带宽、低延迟的服务,用来在Runner和特定语言的SDK harness之间传送数据,建模为逻辑字节流。
- 状态:中等到高带宽的服务,用来支持用户的的State、旁路输入(使用分页的读取)
- 日志:低到中等带宽的服务,用来从特定语言的SDK harness中收集日志信息。
API & Code References
Fn API展开描述
使用Fn API如何处理一个Bundle? (待续)
如何使用Fn API发送和接受数据? (待续)
如何访问旁路输入、远程引用和支持用户自定的State Fn API? (待续)
如何使用Fn API报告Bundle的处理进度? (待续)
如何使用 Fn API初始化用户容器? (待续)
初步总结
在Dataflow上使用Fn API的方式进行测试,对10GB的数据进行读取,然后按照key进行分组,然后进行了很简单的ParDo处理,Pipeline的执行时间增加了15%。执行时间从开始读取到ParoDo处理完最后一条记录,不包含VM的启动耗费的时间。注意,大约80%的性能消耗在Fn Api的序列化和反序列化数据上,这个问题可以通过优化逻辑极大的降低。同时也需要注意,本次Pipeline的性能基准测试是非典型的,因为在ParDo中的用户代码时间非常短暂,但是在一般的场景中,Pipeline的ParDo需要处理大量的复杂逻辑,随着用户代码的执行时间变长,序列化反序列性能消耗所占的比重就会相对下降。
好处Benefits
使用Docker和gRPC接口,Fn API带来了如下好处:
- 提供了简洁的API声明,降低了实现SDK所需要了解的知识。
- 能够使Pipeline混合使用多种语言实现,允许重用不同的SDK中实现的连接器、类库等(ML等等)。
- 允许Python SDK(或任何Beam SDK)在支持Fn API的任何Runner(不限于Python实现的Runner)上运行:给出一种使用内置的UDF构建特定Runner上的执行计划的方式(Runner API是实现可移植的关键),然后Runner可以在任何特定语言的SDK中执行UDF。
- 减少了耦合性,降低了Runner的升级和打补丁的风险。
- 解决当用户代码需要与Harness不同的环境时引起的依赖关系问题。
- 对于Python用户来说,是自定义用户运行时环境的关键。
- 对于Java用户,依赖关系冲突时有用。
- 当用户希望通过安装附加库或包含大型静态数据文件来配置其运行时环境时也很有用。
结束!
转载需标明文章来源!















 2193
2193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









