









简介Overviews
在Apache Beam Fn API 总体介绍中阐述了总体视角,列出了一系列相关的文档。本文中描述了在处理Bundle时,Beam Runner和Beam SDK Harness之间使用Fn API发送和接收数据的模型。
发送和接受数据
从高层来看,Runner和SDK Harness之间需要相互传送数据,来支持Bundle的处理。SDK希望允许用户使用任意的数据类型,而不需要Runner必须支持这些类型。Runner和SDK需要接受发送大规模的乱序数据。
要求
SDK Harness已经初始化,并且通过BeamFnControl连接到一个Runner。Runner向SDK Harness发送了处理Bundle的请求。
高层视图
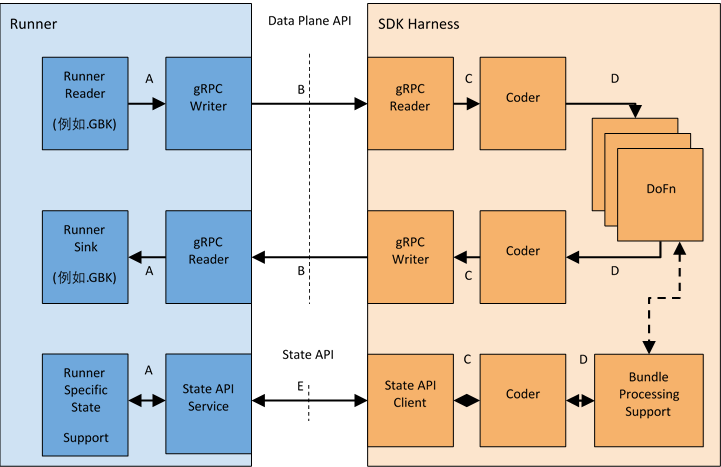
- A: 特定Runner内部的表达
- B:Data Plane API序列化
- C: 序列化之后的数据
- D: 用户指定的类型T
- E: State API 序列化
Runner和SDK之间使用State 和Data Plane API传输编码之后的数据,称之为逻辑流。SDK Harness负责编码和解码用户指定的数据类型。Runner使用内部的表达形式支持Bundle处理。
逻辑流Logical Stream
BeamFnData和BeamFnState API被建模为一系列的逻辑数据流。各自的Protobuf消息表达了部分的逻辑数据流。
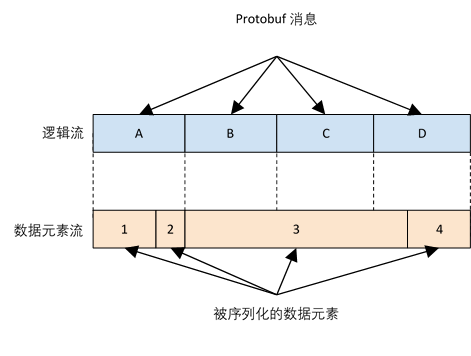
对于BeamFnData API,一组逻辑流在在单个BeamFnData gRPC流上多路复用。逻辑流使用target进行标识,以长度为0的消息结尾。
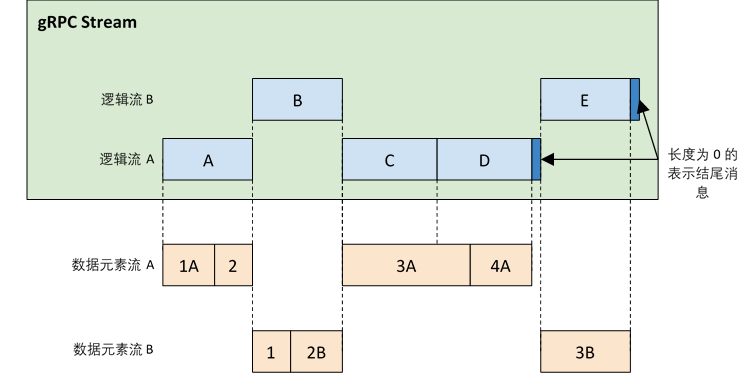
对于BeamFnState API,逻辑流使用State key进行标识,流中的数据片段使用连续的Token进行标识。BeamFnState API中的逻辑流,当返回的响应中token不连续了就算是结束了。
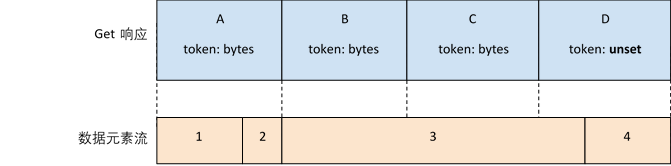
对于一个逻辑流,元素在一个嵌套的上下文中进行编码。也有很少的情况下,元素编码之后是0字节,Runner/SDK Harness负责为编码之后的数据添加额外的信息,以便在读写的时候进行识别。
编码和解码已知类型
为了能够支持确定的用例场景,例如GroupByKey,Runner和SDK Harness要对以下几种编码格式达成一致:
- KV: 键值对包装类.
- Stream: 持有0个或多个值。用来表达可迭代的数据结构,例如lists, collections, and sets 。
- LargeStream: 持有1个Steam或者State Key,用来支持迭代大规模的GroupByKey 结果。
- WindowedValue: 存储窗口、窗格、值和时间戳的类型,用来支持触发器和窗口语义的执行。
- LengthPrefix: 对被包装的值的长度进行编码的包装器类型。
- Bytes: 二进制数组。
使用Pcollection关联的Coder对数据元素进行编码(序列化)。更多的细节参考Runner API。
建议Runner能够识别如下编码方式,但不做强制要求:
-
GlobalWindow: 表示包含(负无穷,正无穷)时间范围的窗口
A window representing the time interval (-inf, +inf)
- IntervalWindow: 表示[开始时间, 结束时间)这一间隔内的窗口。
- VarInt: 变长的整数。
Runner也可以选择内置其他任意类型的元素的编码方式。
编码和解码未知类型
发送方和接收方需要能够区分不同数据元素的边界,使得连续的字节流可以由发送方正确编码并由接收方解码。 SDK Harness需要充分了解Coder的细节,以便对数据进行编码和解码,而Runner可能只是了解Coder的部分。 让我们使用ParDo的例子,然后写一个GroupByKey。
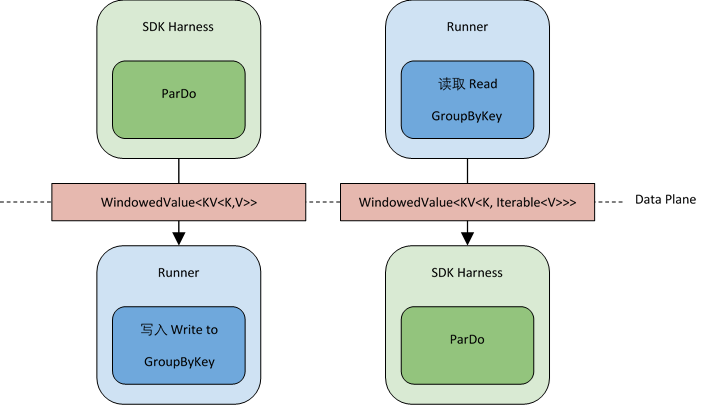
SDK Harness通过数据层传送表示为WindowedValue<KV<K, V>>的数据。窗口和KV键值对,SDK Harness和Runner都提供了支持,可以进行编码和解码。为了能够执行GroupByKey,Runner需要能够区分Key和Value。所以SDK Harness需要以Runner能够理解的方式,对Key K和值 V进行编码。
类似地,如果我们使用一个SDK Harness的例子来处理GroupByKey的输出上的ParDo。 Runner将需要能够描述价值V边界包裹在一个可迭代的方式,SDK的线束可以区分这些边界。
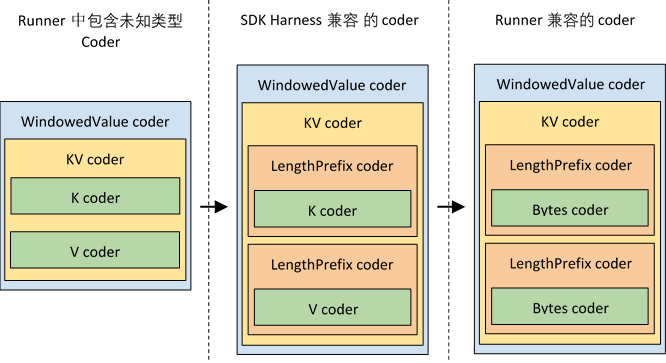
长度前缀编码器用来包装未知值类型,描述编码之后数据元素的边界,使得双方能够识别编码元素的长度,而不需要知道如何对该值进行编码或解码。 对于写入GroupByKey示例,下图显示了具有未知组件的编码器如何转换为SDK Harness和Runner兼容编码器。
应对大规模的数据
Protobuf消息有长度限制,取决于所选择语言好的Protobuf类库。由于在类库中中使用无符号/有符号32位整形,所以典型的限制是2GB或者4GB。可以将Protobuf消息视为逻辑上的字节流,跟编码的元素边界无关,来解决限制的问题。

在上例中,注意:
- 数据元素和Protobuf消息可能是对齐的也可能不对齐。
- 多个数据元素可以包含在一个Protobuf消息中。
- 一个数据元素可能跨越多个Protobuf消息。
为了在不同语言版本的Protobuf中可以进行互操作,Runner和SDK harness必须限制Protobuf的消息大小 < 2GB。
长度前缀编码
长度前缀编码器用于包装未知编码器,使得编码可以被SDK线束和Runner两者所理解。 它还允许将任意大的值分解成较小的部分。 长度前缀编码器由包含最大块大小的单个值进行参数化。
长度前缀编码器将任意长字节序列视为一组固定大小的块,其中最后一个块的长度可变长度严格小于参数化的最大值。 下面是一个具有长度前缀编码器参数化为16字节的37字节对象的编码示例。
Length 16 | Data[0, 16) | Length 16 | Data[16, 32) | Length 5 | Data[32, 37) |
结束!
转载需标明文章来源!















 57
57

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









