









一、技术概览
1. Core Data 功能初窥
对于处理诸如对象生命周期管理、对象图管理等日常任务,Core Data框架提供了广泛且自动化的解决方案。它有以下特性。
(注:对象图-Object graph的解释:在面向对象编程中,对象之间有各种关系,例如对象直接引用另外的对象,或是通过引用链间接的引用其他对象,这些关系组成了网状的结构。我们把这些对象(和它们之间的联系)成为对象图。 对象图可大可小,有繁有简。 只包含单个字符串对象的数组就是一个简单的代表;而包含了application对象,引用windows, menus和相关视图对象、其他对象这样的结构就是复杂对象图的例子——这是在说mainwindow.xib。
有时,你可能想要把这样的对象图转化形式,让它们可以被保存到文件中,以使其他的进程或其他的机器可以再次将保存的内容读出,重购对象。 这样的过程常被成之为“归档”(Archiving)。
有些对象图是不完整的——通常称之为局部对象图(partial object graphs)。局部对象图包含了“占位符”(Placeholder)对象,所谓”占位符“,就是一些暂时无内容的对象,它们将再后期被具体化。一个典型的例子就是nib文件中包含的File's Owner对象。
1) 对于key-value coding 和key-value observing完整且自动化的支持
除了为属性整合KVC和KVO的访问方法外, Core Data还整合了适当的集合访问方法来处理多值关系。
2) 自动验证属性(property)值
Core Data中的managed object扩展了标准的KVC 验证方法,以保证单个的数值在可接受的范围之内,从而使组合的值有意义。(需校准翻译)
3) 支持跟踪修改和撤销操作
对于撤销和重做的功能,除过用基本的文本编辑外,Core Data还提供内置的管理方式。
4) 关系的维护
Core Data管理数据的变化传播,包括维护对象间关系的一致性。
5) 在内存中和界面上分组、过滤、组织数据
6) 自动支持对象存储在外部数据仓库的功能
7) 创建复杂请求
你不需要动手去写复杂的SQL语句,就可以创建复杂的数据请求。方法是在“获取请求”(fetch request)中关联NSPredicate(又看到这个东东了,之前用它做过正则)。NSPrdicate支持基本的功能、相关子查询和其他高级的 SQL特性。它还支持正确的Unicode编码(不太懂,请高人指点), 区域感知查询(据说就是根据区域、语言设置调整查询的行为)、排序和正则表达式。
8) 延迟操作(原文为Futures(faulting)直译为期货,这里个人感觉就是延迟操作的形象说法。请高人指教)。
Core Data 使用延迟加载(lazy loading)的方式减少内存负载。 它还支持部分实体化延迟加载,和“写时拷贝”的数据共享机制。(写时拷贝,说的是在复制对象的时候,实际上不生成新的空间,而是让对象共享一块存储区域,在其内容发生改变的时候再分配)。
9) 合并的策略
Core Data 内置了版本跟踪和乐观锁定(optimistic locking)来支持多用户写入冲突的解决。
注:乐观锁,假定数据一般不出现冲突,所以在数据提交更新的时候,才对数据的冲突进行检测,如果冲突了,就返回冲突信息。
10) 数据迁移
就开发工作和运行时资源来说,处理数据库架构的改变总是很复杂。Core Data的schema migration工具可以简化应对数据库结构变化的任务, 而且在某些情况下,允许你执行高效率的数据库原地迁移工作。
11) 可选择针对程序Controller层的集成,来支持UI的显示同步
Core Data在iPhone OS之上 提供NSFetchedResultsController对象来做相关工作,在Mac OS X上,我们用Cocoa提供的绑定(Binding)机制来完成。
2. 为何要使用Core Data
使用Core Data有很多原因,其中最简单的一条就是:它能让你为Model层写的代码的行数减少为原来的50%到70%。 这归功于之前提到的Core Data的特性。更妙的是,对于上述特性你也既不用去测试,也不用花功夫去优化。
Core Data拥有成熟的代码,这些代码通过单元测试来保证品质。应用Core Data的程序每天被世界上几百万用户使用。通过了几个版本的发布,已经被高度优化。 它能利用Model层的信息和运行时的特性,而不通过程序层的代码实现。 除了提供强大的安全支持和错误处理外,它还提供了最优的内存扩展性,可实现有竞争力的解决方案。不使用Core Data的话,你需要花很长时间来起草自己的方案,解决各种问题,这样做效率不高。
除了Core Data本身的优点之外,使用它还有其他的好处: 它很容易和Mac OS X系统的Tool chain集成;利用Model设计工具可以按图形化方式轻松创建数据库的结构;你可以用Instruments的相关模板来测试Core Data的效率并debug。 在Mac OS X的桌面程序中,Core Data还和Interface Builder集成(打开Inspector可以看到有binding的选项,这个东东iPhone上木有。。。),按照model来创建UI变的更简单了。 这些功能能更进一步的帮助你缩短设计、开发、测试程序的周期。
3. Core Data不是。。。
看了前面的介绍之后,我们还需要了解一下关于Core Data常见的误解:
1) Core Data不是一个关系型数据库,也不是关系型数据库管理系统(RDBMS)。
Core Data 为数据变更管理、对象存储、对象读取恢复的功能提供了支持。 它可以使用SQLite作为持久化存储的类型。 它本身并不是一个数据库(这点很重要,比如,你可以使用Core Data来记录数据变更,管理数据,但并不能用它向文件内存储数据)。
2) Core Data不是银弹
它并不能取代你写代码的工作。虽然可以纯粹使用XCode的数据建模工具和Interface Builder来编写复杂程序,但在更多的程序中,你都自己动手写代码。
3) Core Data并不依赖于Cocoa Bindings
Core Data + Cocoa Binding = 减少代码数量。但Core Data完全可以在没有bindings的条件下使用。例如,可以编写一个没有UI,但包含Core Data的程序。
二、Core Data基础
1. Core Data基本架构
在大部分程序中,你要能通过某种方式打开一个包含对象归档的文件, 这个文件内至少要有一个根对象的引用。另外,还得能将所有的对象归档到文件中,如果你想要实现撤销的功能,就还要记录对象的更改情况。例如,在 Employee的示例程序中,你要能打开一个包含有employee和department对象归档的文件,而且这个文件至少包含了一个根对象——这 里,是一个包含所有employee的数组——请参考例图Figure 1。 相应的,你还要能将程序中的employee、department对象归档到文件中去。
Figure 1 按照Core Data文档结构管理的对象示意图
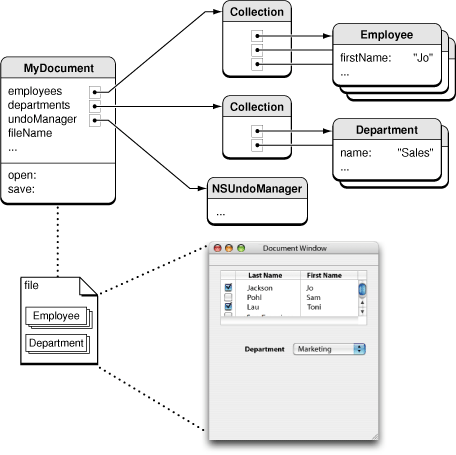
Figure 2 使用Core Data的文档管理示意图
Core Data的使用并不限制在基于文档的程序中(document-based application)。你也能创建一个包含Core Data 的Utility程序(请查看Core Data Utility tutorial文档)。当然其他类型的程序也都可以使用Core Data。
被管理对象和上下文(Managed Objects and Contexts)
你可以把被管理对象上下文想象成一个”聪明“的便笺簿。当你从数据持久层获取对象时,就把这些临时的数据拷贝拿到写在自己的便笺簿上(当然,在便笺上对象会 “恢复”以前的对象图结构)。然后你就可以随心所欲的修改这些值了(本子是你的,随便画都可以),除非你保存这些数据变化,否则持久层的东西是不会变 的。(跟修改文件后要保存是一个道理)。
附在Core Data框架中模型对象(Model objects)常被称为“被管理对象”(Managed objects)。所有的被管理对象都要通过上下文进行注册。使用上下文,你可以在对象图中添加、删除对象,并记录对象的更改(包括单个对象,或是对象间 的关系)。记录更改后就能支持撤销和重做的功能。同时,上下文还能保证关系更改后对象图的完整性。
如果你想要保存所做的修改, 上下文会保证对象的有效性。在验证有效性后,更改会被写入到persistent store(持久化存储层)中。你在程序中的添加和删除动作都会被作用在存储的数据中。
在你的一个程序中,可能存在多个上下文。 对于数据存储(store)中的每个对象,对应的都有唯一的一个被管理对象(managed object)和上下文相关联(详情请查看"Faulting and Uniquing"文档)。换个角度来想,在persistent store中存储的对象有可能被用在不同的上下文中,每个上下文都有与之对应的被管理对象,被管理对象可以被独立的修改,这样就可能在存储 时导致数据的不一致。Core Data提供了许多解决这个问题的途径(请查看"Using Managed Object"一章)。
获取数据的请求(Fetch Requests)
要使用上下文来获取数据,你需要创建相应的请求(Fetch request)。 Fetch request对象包含你想获取的对象的描述。例如:“所有 Employee”,或“所有的Employee,department是marketing,按薪资降序排列”。Fetch Request包含三个部分。使用最简单的写法,必须指定实体(Entity)的名称,这就暗示了,每次智能获得一种类型的实体。 Fetch Request 还可以包含谓词(predicate)——注:有些地方也把这个叫断言,个人感觉谓词更准确些。谓词将描述对象需要满足的条件(这就和我们在SQL里加的 限定条件差不多,正如前面的"All Employees, in the Marketing department")。另外,Fetch Request还可包含一个用于描述排序方式的对象(熟悉的Order by操作)。如图Figure3所示:
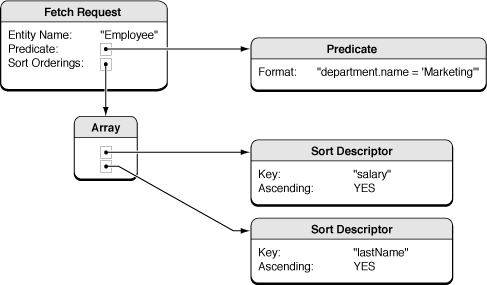
Core Data追求高执行效率。 它是“需求驱动”的,因此只会创建你确实需要的对象。对象图不需要保留所有在数据存储层中的对象。单纯指定数据持久层的动作不会将其中所有的数据放到上下 文中去。 当你想从数据存储层中获取某些对象的时候,你只会得到那些你请求的(有点罗嗦,总的意思就是需要时获取,获取的就是需要的)。如果你不在需要这个对象的时 候,默认情况下它会被释放。(当然,只是释放这个对象,而不是从对象图中移除该对象)。——注:个人感觉有点像重新拷了一个文件的某些部分,不用了就在副 本中删除,不会影响原件。
持久化存储助理(Persistent Store Coordinator)
之前提到过,程序中的对 象和外部存储的数据通过Core Data框架中的一系列对象进行协调,这一系列的对象总的被称为持久存储栈(Persistence stack)。在栈顶是被管理对象上下文(Managed object context),而栈底是持久化对象存储层(Persistence object store)。在它们之间就是持久化存储助理。
事实上,持久化存储助理定义了一个栈。从设计方面考虑,它就是可以作为上下 文的”外观“, 这样多个数据存储(Persistence store)看起来就像是一个。 然后上下文就可以根据这些数据存储来创建对象图了。持久化存储助理智能关联一个被管理对象的模型。如果你像要把不同的实体放到不同的存储中去,就需要为你 的模型实体做“分区”,方式是通过定义被管理对象模型的configurations。(请参考"Configurations"一章)。
Figure 4演示了这样的一个结构:employees和departments存储在一个文件中,customers和companies存储在另外一个文件中。当你要获取对象的时候,它们从相关的文件中自动获取;当保存时,又被归档到相应的文件中。
Figure 4存储栈—改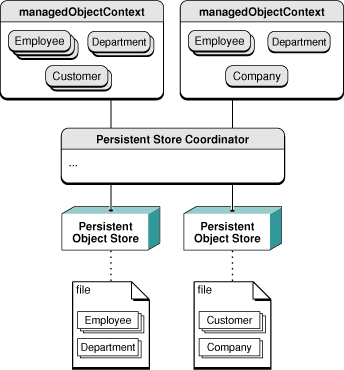
持久化存储(Persistent Stores)
持久化存储是和单独的一个文件或外部的数据关联的,它负责将数据和上下文中的对象进行对应。通常,需要你直接和持久化对象存储打交道的地方,就是指定新的、 和程序进行关联的外部数据的位置(例如,当用户打开或保存一个文档)。大多数需要访问持久化存储的动作都由上下文来完成。
程序的代码—— 特别是和被管理对象相关的部分——不应该对持久化存储做任何假设(也就是不需要自己考虑存储的方式或过程)。 Core Data对几种文件格式有原生的支持。你可以选择一种自己程序需要的。假设在某个阶段你决定换一种文件的格式,而又不想修改程序的框架,而且,你的程序做 了适当的抽象(注:这个就属于设计方面的东东了),这时,你就能尝到使用Core Data的甜头了。例如,在最初的设计中,程序只从本地文件中获取数据,而你的程序没有去硬指定对应数据的获取位置,而是可以在后期指定从远程位置添加新 的数据类型,这样你就可以使用新的类型,而不需要修改代码。(这段还是感觉翻的不太合适)。
重要提示:
虽然Core Dta支持SQLite作为一种存储类型,但它不能使用任意的SQLite数据库。Core Data在使用的过程种自己创建这个数据库。(详情,请参考"Persistence Store Features")。
持久化文档(Persistent Documents)
你可以通过代码的方式创建和配置持久存储栈,但在多数情况下,你只是想创建一个基于文档 的应用程序(Document-based application,这个是mac上的)来读写文件。这时,用NSDocument的子类NSPersistentDocument可以让你感受到使 用Core Data的便利。默认状况下,NSPersistentDocument就已经创建了它自己的持久存储栈,其中包含了上下文,和单个的持久对象存储,来处 理这样文档和外部数据“一对一”的映射关系。
NSPersistentDocument类提供了访问文档的上下文的方法,也实现了标准的NSDocument方法来通过Core Data读写文件。 一般说来,你不需要编写额外的代码来处理对象的持久化。
持久化文档的撤销(undo)操作也被集成在被管理对象的上下文中。
被管理对象和被管理对象模型(Managed Objects and the Managed Object Model)
为 了管理对象图,也为了提供对象持久化的功能,Core Data需要对对象有很强的描述能力。被管理对象模型就是程序中对象、实体描述的概要图,如图Figure 5所示。创建模型的常用做法是通过Xcode的图形化建模工具Date Model Design tool。但是如果你愿意的话,也可以在运行时通过代码来建模。
Figure 5 有两个实体的对象模型
Figure 6 带有两个属性和一个关系的的实体描述
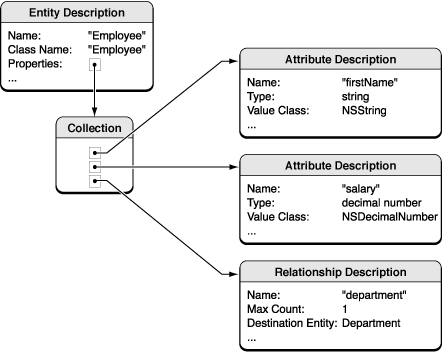
被管理对象模型(Managed Object Models)
多数Core Data的功能依赖于你创建的,用来描述程序的实体及其属性、关系的模型图。 模型图由NSManagedObjectModel所表示。一般说来,模型的信息越充实,Core Data能提供的功能就越好。 下文讲解了对象模型的特性,以及如何在程序中创建、使用对象模型。
被管理对象模型的特性
被管理对象模型是 NSManagedObjectModel的实例。它描述了你在程序中使用的实体的概要信息。(如果读者不了解entity、property、 attribute和relationship的含义,请先查看"Core Data Basics"和"Cocoa Design Patterns"文档中的"Object Modeling"一节)
实体(Entities)
模型包含了NSEntityDescription对象,NSEntityDescription对象指代了模型的实体。关于实体由两个重要特征:名称(name)和类名(name of class)。你应该弄清楚实体、实体的类和作为实体实例的被管理对象之间的区别。
NSEntityDescription 对象可包含NSAttributeDescription对象(指代实体的attribute)和NSRelationshipDescription对 象(指代实体间的relationship)。实体也可能包含fetched属性,该属性由NSFetchedPropertyDescription指 代,模型中有对应的fetch请求的模板,fetch请求由NSFetchRequest所指代。
实体的继承关系
实体的继承和类 的继承很类似,当然,也同样有用。 如果你有若干个相似的实体,就可以抽离出它们的共有特性作为一个“父实体”,就省去了在多个实体中都指定相同的属性。 例如,你可以定义一个包含firstName和lastName的“Person”实体,然后在定义子实体"Employee"和"Customer"。
如果是使用Xcode的可视化建模工具来创建模型,你就可以通过如下图的方式为一个实体指定父级实体。

抽象实体
你可以把一个实体指定为“抽象实体”,也就是说,你不打算使用这个实体来创建实例。通常,当你想把这个实体作为父实体,而有子实体来实现详细内容的时候,就 把它声明“抽象实体”。(和抽象类很像)。例如,在一个绘图程序中,你可能会设计一个Graphic实体,它包含了x和y坐标信息、颜色、绘制区域,而你 不会去创建一个Graphic的实例,而是使用具体的子实体——Circle、TextArea、Line。(这些基本的东西就不给大牛们再罗嗦 了。。。)
Properties(属性,这个和Attributes的意思一样,实在区别不出来,只好上英语了)
实体的 Properties是它的attributes和relationship,包含了fetched属性(如果有的话)。每个property都有名称和 类型。 Attribute也可能有默认值。property的名称不能和NSObject和NSManagedObject类中的无参方法名相同。例如,不能把 property命名为"description"。
临时属性(Transient Property)也是作为模型的一部分,但是不作为实体实例的数据保存在持久存储层。 Core Data也会跟踪临时属性的变化,以备撤销操作时使用。
注意:如果你用模型外的信息对临时属性执行撤销操作,Core Data将不会使用旧值,调用你的















 1392
1392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









