







Linux可能运行在多核的环境下,Linux就会在这多个核直接负载均衡,每一个核跑的调度算法都是前面说的FIFO,RR,CFS。但是Linux会自动分布在多个核上,自动负载均衡。每个核都有可能把自己的tast_struct从自己的核推到旁边一个核,然后有一个核也可能把自己的推给旁边的,但是在Linux多核场景之下,每一个核都以劳动为乐,所以当别的核把任务推给它去跑的时候,他心里面很开心。它自己闲下来的时候也会从别的地方拉task_struct去跑。我们用time命令跑前面的那个例子,time可以看到程序跑的时间
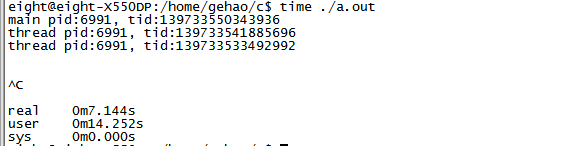
对我们人类世界的时间是7.144s,对于操作系统的userspace的时间是14.252S,对于kernel space接近0,因为太小了就是一个死循环
我们可以大小他在人类时间跑的时间是user+sys的一半,原因很简单,我两个死循环的线程被Linux瓜分到两个核上去了。
负载均衡是把N个优先级最高的RT分布到N个核上,所以RT不应该讲负载均衡,应该讲实时性,什么意思呢,我电脑4核,有8个RT的进程,他就从8个RT进程找到4个优先级最高的放到这个进程里面去
RT负载均衡做完之后,就考虑普通进程的负载均衡,周期性负载均衡,比如说操作系统的节拍来了的时候,它就会去查我这个核是不是比较闲,旁边那个核是不是比较忙,它发现旁边那个核比自己这个核的负载大到一定程度的时候
它就会自动把旁边那个核的task_struct拿过来跑,这个过程是自动的,还有IDLE时负载均衡,就是一个CPU准备去跑IDLE时,它就会看看旁边那个核是不是很忙,我这个核不能闲下来。fork和exec时负载均衡,这个时候会把你的task_struct推到最闲的一个核上去跑
但是我们程序员有个那个办法可以控制它在那个核上
设置affinity
int pthread_attr_setaffinity_np(pthread_addr_t *,size_t,const cpu_set_t *);
int pthread_attr_getaffinity_np(pthread_addr_t *,size_t,const cpu_set_t *);
int sched_setaffinity(pid_t pid,unsigned int cpusetsize,cpu_set_t *mask);
int sched_getaffinity(pid_t pid,unsigned int cpusetsize,cpu_set_t *mask);
比如说我有7个核,但是我一个线程指向到核1(其实是第二个核,因为还有一个核0)和核2上跑,它就把cpu_set_t设置为0x6 因为0x6就是0b110,如果只想运行到核3上,直接设置为0x04;
除了编程可以设置外,Linux还有一个工具,这个工具是taskset,你可以调用这个taskset来设置你这个线程想到那个地方跑,如果你想把一个进程全部线程全部设置了,你就-a,-a的意思是all
例如 taskset -a -p 01 19999 01就是掩码,表示第0个CPU,02表示第2个CPU 03表示第0个或第一个CPU。
做个实验
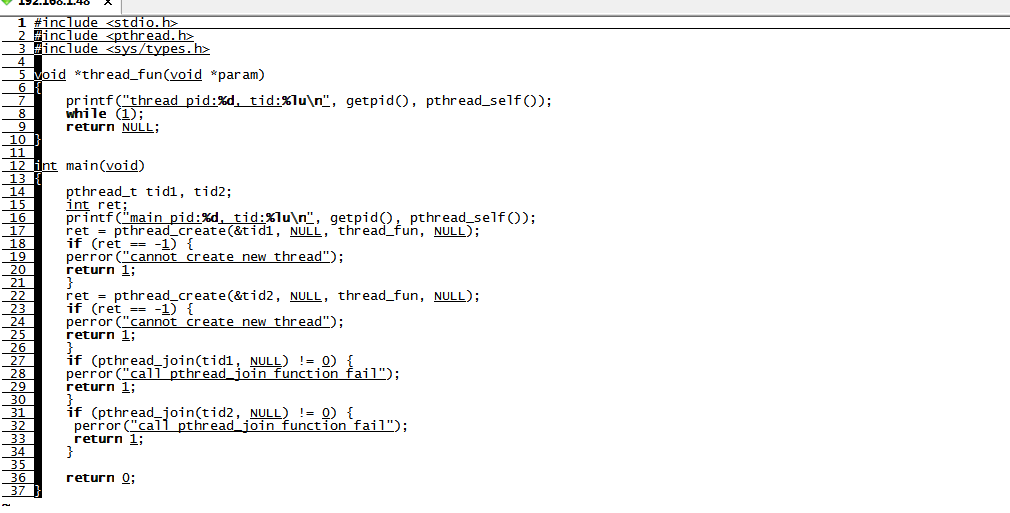
运行这个程序,一开始运行的时候是
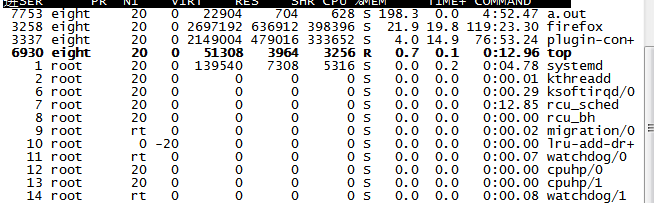
然后我们把它放到一个核上,使用这个命令taskset -a -p 01 7753,它占用CPU肯定是100%

中断也可以负载均衡,中断的负载均衡怎么做呢
在/proc下有个irq目录,然后下面有个中断号的文件夹里面有个文件是smp_affinity
比如说我电脑有个网卡,这个网卡有四个队列,4个中断的中断号分别是75,76,77,78,我一定要做一个负载均衡,怎么做呢
我把这四个队列首发的中断分别放到1 2 3 4核上去,
就用echo 01 >/proc/irq/75/smp_affinity echo 02 >/proc/irq/76/smp_affinity echo 04 >/proc/irq/77/smp_affinity echo 08 >/proc/irq/78/smp_affinity 这样就把中断负载均衡了
但是有时候中断做不了负载均衡,比如说我一个网卡,这个网卡只有一个队列,但是我有8个核,我这个中断就发给了第0个核,大家都知道在网卡驱动里面,我CPU0在收到一个中断之后,调度了一个软中断,然后会在CPU0上运行
这个时候会出现一个情况,你CPU忙得要死,其余的看热闹,所以后面Linux提供了一个补丁叫RPS,它可以做软中断的负载均衡,原理很简单每一个网卡的队列里面有个rps_cpus,给他echo 一个fffe 就是把这个软中断负载均衡到第一个核第二个核一直到到第15个核

cgroup
cgroup是指的进程的分群,前面讲过普通的task_struct和普通的task_struct之间按照CFS去调度,我现在假设有一台安卓编译服务器,就是公司搞一个很猛的电脑,所有的编译都去服务器上去搞,但是按照Linux的算法,当一个用户登录之后,它用1000个线程去编译,另外一个用户登了之后,创建10个线程去编。如果这1010个线程的nice值为0的话,那我Linux内核看到的就是1010个线程。大家nice值都是0,都是CPU消耗型,那创建1000个线程的人就很爽,按照调度算法你就可以I拿到1000/1010的CPU,这样的话第二个用户岂不是很不公平吗,所以Linux就创建了一个分群调度,你可以把一些task_struct加到一个群里面,把另外的一些task_struct加到另外一个群里吗,群和群直接,先按照CFS调度算法去调,调完之后群内再按照调度算法去调用,这样我们就可以先把1000个线程加到群A,把这10个线程加到群B
我们做个实验,把我们上面的程序联系到后台跑4个
我们创建2个cgroup,创建gcroup的方法很简单,
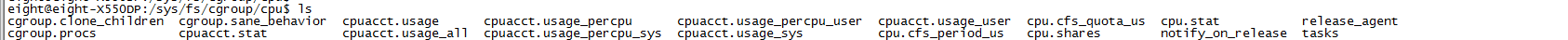
然后创建两个目录,

然后你进入A

然后你进入A,发现里面已经自动有下面这些文件了。我们可以cat cpu.shares,可以看到权重是1024,我们看B的也是1024

下面我们把第一个a.out和第二个a.out整个进程,怎么加整个进程呢,就是把你pid加到cgroup.procs这个文件里面
如果你要加某个线程,就把这个线程的内核pid加到这个tasks文件里面。我们现在只加进程,如图
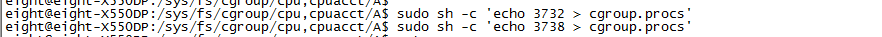
前面的图可以看到pid 我们这里加俩个
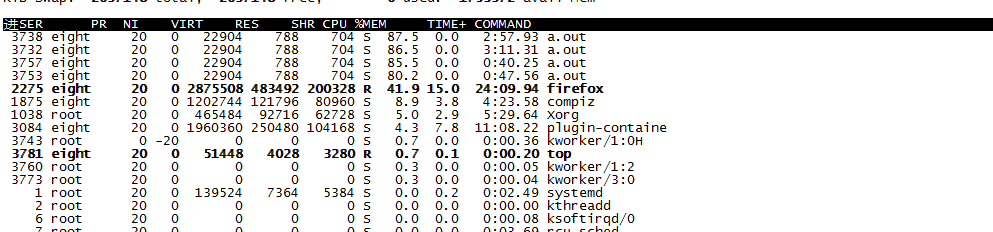
然后我们把其他的两个加到B里面去,但是这样看不出什么效果,我们还是创建3个,然后A放两个,B放一个,效果如图

这样可以看到3753和3757加起来才和3732的CPU占用率一样
如果我们想把这三个CPU的利用率变得大体相等的话,要么就是把B的权重变成2048,要么把A的变成512。因为现在A B的权重都是1024

效果如图

这是CPU的分群调度,cgroup还一个好处,你可以限制一个cgroup里面的Quota,就是它的比例,你可以现在一个group一个周期里面最多跑多少。
例子。我干掉所以的a.out,跑一个a.out,然后加入到A这个cgroup里面去

然后这个目录下有两个文件,我们cat 看一下

第一个是周期,第二个是quota,这句话是什么意思呢,就是A这个group里面的CFS进程,在10W微妙里面,就是100ms,里面最多可以跑-1微妙,-1应该是全部的。
我限制你在1000000最多跑20000毫秒,使用下面的命令

效果

cpu利用率马上降到20%,你也可以把quota升级为120000,因为你是多核的,可以比周期大
下面讲硬实时,硬实时不是越快越好。hard realtime最主要的意思是可预期,什么意思呢,就是在一个硬实时的操作系统里面,当你唤醒了一个高优先级的RT任务,从你唤醒它到它开始得以调度,这中间的延迟是不会超过一个截止期限的,比如说我按一个按钮发导弹,这个导弹从按到发射这个中间最多1MS,举个例子而已,如果你1MS没法出去,就会出现灾难性的后果,你打到的可能就是解放军了。一旦你MISS掉这个截止期限,后果将是灾难性的。这就叫做硬实时,你不能miss掉。但是你Linux不是这么样的系统,Linux是个软实时的系统,软实时系统可以超过截止期限,超过了后果不是灾难性的。一个典型的软实时就是放电源,这个电影每秒要放50帧,意味着每20ms要放出一帧,但是某个电脑比较慢,30ms才放一帧,这个人绝对不会因为这个慢而怎么怎么。所以要不要实时是你应用程序决定的。
Linux有个好玩的,就是你创建一个RT进程,你跑一段时间就会休息一段时间,然后在跑,如果是硬实时你会这段时间是稳定的,但是Linux不是,而是你这段时间+调度时间抖动,所以有个很好玩的工具叫做cyclictest,你创建一个优先级最高的,在应用层RT就是拿99-当前的

他就去评估每一次硬实时和唤醒时间之间的data,他列出最小值,实际的,平均的,和最大的 单位是ms 这个最大值会随着你系统负载的变大而变大。这个延迟具有不确定性。这是一个Linux不是硬实时操作系统的原因。
为什么会这样的呢

Linux从 早期发展到现在,不可抢占的区间越来越来越少,当你打上硬实时的补丁,你面状不可调度区域就变成点状的了,面状就是前面的红色的,点状的就是下面的黑线
CPU的时间主要用在下面这个方面,一类是中断,一类是软中断,一类是进程,但是这个进程有个特例,但是spin_lock,那个核上拿到了这个锁,调度器就会被关掉。然后这个进程里面还有一个区间是可调度的进程上下文。可调度的时间是只要这个可调度的进程上下文可以调度。什么叫中断呢,就是我程序一直跑得好好的,突然你硬件上收到一个中断这个时候就自动调到中断程序里面去执行,如果我在中断服务程序里面调度一个RT,不好意思不会抢占。软中断唯一的区别就是中断里面可以被中断。当你可以调度的事情发生在前面1 2 3的时候是不会被抢占的。你只有1 2 3类全部结束,结束的一瞬间理解抢占。
你打实时补丁就会把spinlock迁移可调度的mutex,同时报了raw_spinlock_t,mutex只是你T1拿到,T2拿不到,T2就在睡,知道T1放metux T2才醒
spinlock原理就是关了
RT补丁也会把中断软中断进行线程化















 2530
2530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









