







Spark Streaming笔记
转载自Spark修炼之道
1. Spark流式计算简介
Hadoop的MapReduce及Spark SQL等只能进行离线计算,无法满足实时性要求较高的业务需求,例如实时推荐、实时网站性能分析等,流式计算可以解决这些问题。目前有三种比较常用的流式计算框架,它们分别是Storm,Spark Streaming和Samza,各个框架的比较及使用情况,可以参见:http://www.csdn.net/article/2015-03-09/2824135。本节对Spark Streaming进行重点介绍,Spark Streaming作为Spark的五大核心组件之一,其原生地支持多种数据源的接入,而且可以与Spark MLLib、Graphx结合起来使用,轻松完成分布式环境下在线机器学习算法的设计。Spark支持的输入数据源及输出文件如下图所示:

在后面的案例实战当中,会涉及到这部分内容。中间的”Spark Streaming“会对输入的数据源进行处理,然后将结果输出,其内部工作原理如下图所示:
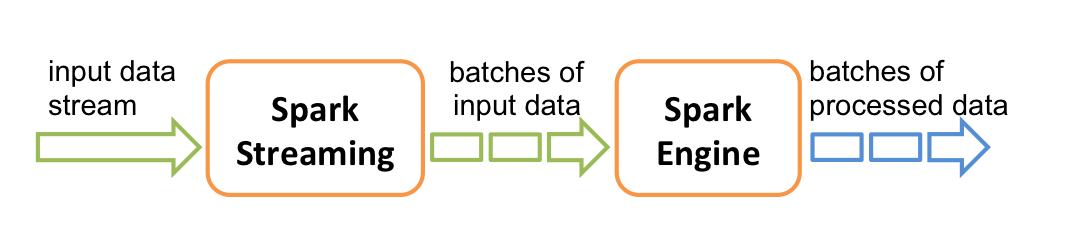
Spark Streaming接受实时传入的数据流,然后将数据按批次(batch)进行划分,然后再将这部分数据交由Spark引擎进行处理,处理完成后将结果输出到外部文件。
先看下面一段基于Spark Streaming的word count代码,它可以很好地帮助初步理解流式计算
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingWordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: StreamingWordCount <directory>")
System.exit(1)
}
//创建SparkConf对象
val sparkConf = new SparkConf().setAppName("HdfsWordCount").setMaster("local[2]")
// Create the context
//创建StreamingContext对象,与集群进行交互
val ssc = new StreamingContext(sparkConf, Seconds(20))
// Create the FileInputDStream on the directory and use the
// stream to count words in new files created
//如果目录中有新创建的文件,则读取
val lines = ssc.textFileStream(args(0))
//分割为单词
val words = lines.flatMap(_.split(" "))
//统计单词出现次数
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
//打印结果
wordCounts.print()
//启动Spark Streaming
ssc.start()
//一直运行,除非人为干预再停止
ssc.awaitTermination()
}
}
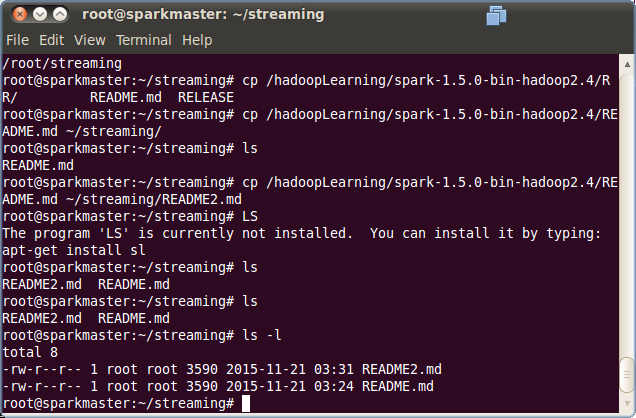
运行上面的程序后,再通过命令行界面,将文件拷贝到相应的文件目录,具体如下:
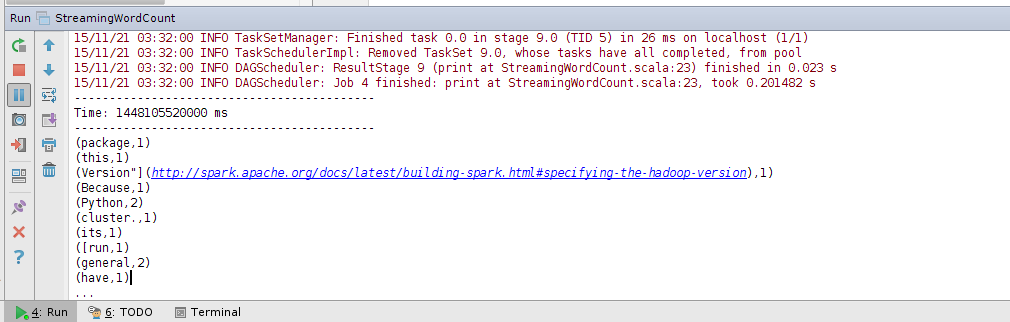
程序在运行时,根据文件创建时间对文件进行处理,在上一次运行时间后创建的文件都会被处理,输出结果如下:
2. Spark Streaming相关核心类
1. DStream(discretized stream)
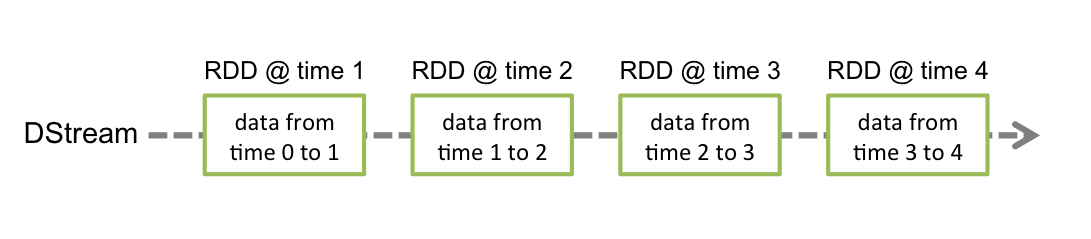
Spark Streaming提供了对数据流的抽象,它就是DStream,它可以通过前述的 Kafka, Flume等数据源创建,DStream本质上是由一系列的RDD构成。各个RDD中的数据为对应时间间隔( interval)中流入的数据,如下图所示:
对DStream的所有操作最终都要转换为对RDD的操作,例如前面的StreamingWordCount程序,flatMap操作将作用于DStream中的所有RDD,如下图所示:
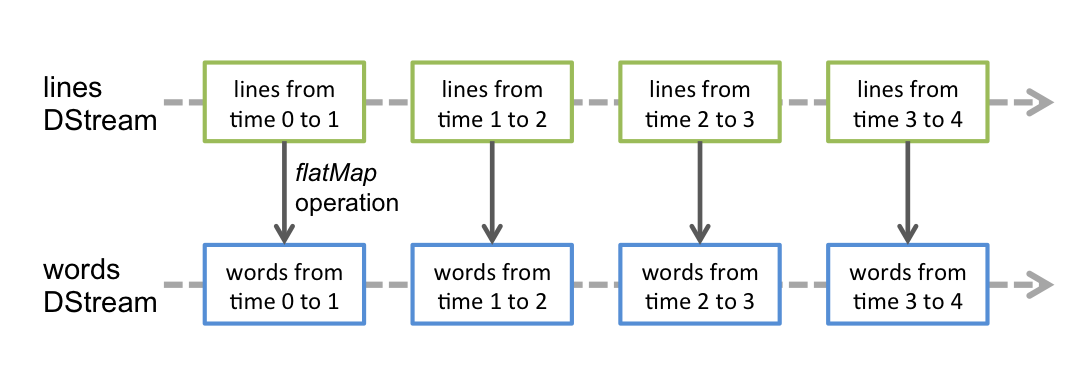
DStream是由一系列的RDD构成的,它同一般的RDD一样,也可以将流式数据持久化到内容当中,采用的同样是persisit方法,调用该方法后DStream将持久化所有的RDD数据。这对于一些需要重复计算多次或数据需要反复被使用的DStream特别有效。像reduceByWindow、reduceByKeyAndWindow等基于窗口操作的方法,它们默认都是有persisit操作的。
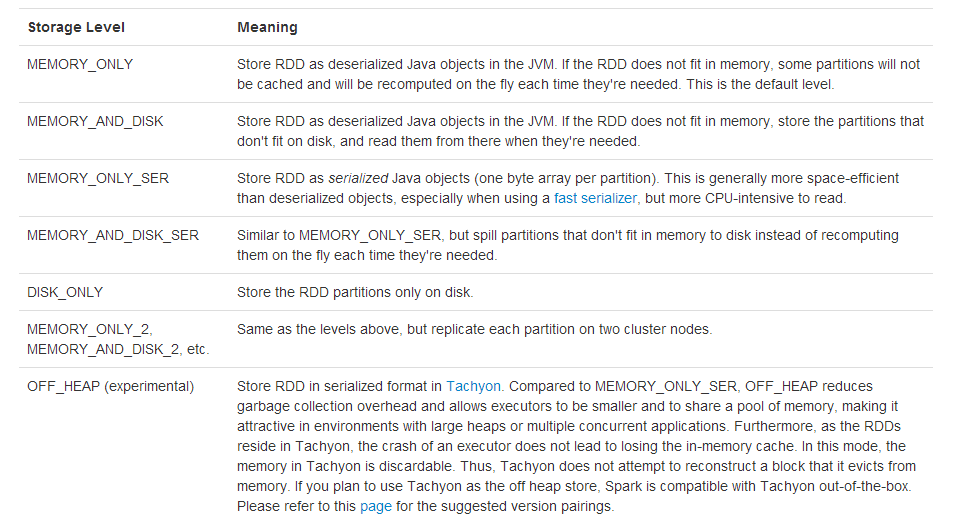
同一般的RDD类似,DStream支持的persisit级别为:
2. StreamingContext
在Spark Streaming当中,StreamingContext是整个程序的入口,其创建方式有多种,最常用的是通过SparkConf来创建:
import org.apache.spark._
import org.apache.spark.streaming._
val conf = new SparkConf().setAppName(appName).setMaster(master)
val ssc = new StreamingContext(conf, Seconds(1))
创建StreamingContext对象时会根据SparkConf创建SparkContext
/**
* Create a StreamingContext by providing the configuration necessary for a new SparkContext.
* @param conf a org.apache.spark.SparkConf object specifying Spark parameters
* @param batchDuration the time interval at which streaming data will be divided into batches
*/
def this(conf: SparkConf, batchDuration: Duration) = {
this(StreamingContext.createNewSparkContext(conf), null, batchDuration)
}
也就是说StreamingContext是对SparkContext的封装。创建StreamingContext时会指定batchDuration,它用于设定批处理时间间隔,需要根据应用程序和集群资源情况去设定。当创建完成StreamingContext之后,再按下列步骤进行:
- 通过输入源创建InputDStreaim
- 对DStreaming进行transformation和output操作,这样操作构成了后期流式计算的逻辑
- 通过StreamingContext.start()方法启动接收和处理数据的流程
- 使用streamingContext.awaitTermination()方法等待程序处理结束(手动停止或出错停止)
- 也可以调用streamingContext.stop()方法结束程序的运行
关于StreamingContext有几个值得注意的地方:
- StreamingContext启动后,增加新的操作将不起作用。也就是说在StreamingContext启动之前,要定义好所有的计算逻辑
- StreamingContext停止后,不能重新启动。也就是说要重新计算的话,需要重新运行整个程序。
- 在单个JVM中,一段时间内不能出现两个active状态的StreamingContext
- 调用StreamingContext的stop方法时,SparkContext也将被stop掉,如果希望StreamingContext关闭时,保留SparkContext,则需要在stop方法中传入参数stopSparkContext=false
- SparkContext对象可以被多个StreamingContexts重复使用,但需要前一个StreamingContexts停止后再创建下一个StreamingContext对象。
3. InputDStreams及Receivers
InputDStream指的是从数据流的源头接受的输入数据流,在前面的StreamingWordCount程序当中,val lines = ssc.textFileStream(args(0)) 就是一种InputDStream。除文件流外,每个input DStream都关联一个Receiver对象,该Receiver对象接收数据源传来的数据并将其保存在内存中以便后期Spark处理。
Spark Streaimg提供两种原生支持的流数据源:
-
Basic sources(基础流数据源)。直接通过StreamingContext API创建,例如文件系统(本地文件系统及分布式文件系统)、Socket连接及Akka的Actor。
-
文件流(File Streams)的创建方式:
a.
streamingContext.fileStream[KeyClass, ValueClass, InputFormatClass]b.
streamingContext.textFileStream(dataDirectory)实际上textFileStream方法最终调用的也是fileStream方法
def textFileStream(directory: String): DStream[String] = withNamedScope(“text file stream”) { fileStream[LongWritable, Text, TextInputFormat].map(_._2.toString) } -
基于Akka Actor流数据的创建方式:
streamingContext.actorStream(actorProps, actor-name) -
基于Socket流数据的创建方式:
ssc.socketTextStream(hostname: String,port: Int,storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2) -
基于RDD队列的流数据创建方式:
streamingContext.queueStream(queueOfRDDs)
-
-
Advanced sources(高级流数据源)。如Kafka, Flume, Kinesis, Twitter等,需要借助外部工具类,在运行时需要外部依赖(下一节内容中介绍)
Spark Streaming还支持用户 Custom Sources(自定义流数据源),它需要用户定义receiver,该部分内容也放在下一节介绍
最后有两个需要注意的地方:
- 在本地运行Spark Streaming时,master URL不能使用“local” 或 “local[1]”,因为当input DStream与receiver(如sockets, Kafka, Flume等)关联时,receiver自身就需要一个线程来运行,此时便没有线程去处理接收到的数据。因此,在本地运行SparkStreaming程序时,要使用“local[n]”作为master URL,n要大于receiver的数量。
- 在集群上运行Spark Streaming时,分配给Spark Streaming程序的CPU核数也必须大于receiver的数量,否则系统将只接受数据,无法处理数据。
3. 入门案例
为方便后期查看运行结果,修改日志级别为Level.WARN
import org.apache.spark.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}
1. NetworkWordCount基于Socket流数据
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
//修改日志层次为Level.WARN
StreamingExamples.setStreamingLogLevels()
// Create the context with a 1 second batch size
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[4]")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
//创建SocketInputDStream,接收来自ip:port发送来的流数据
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
配置运行时参数
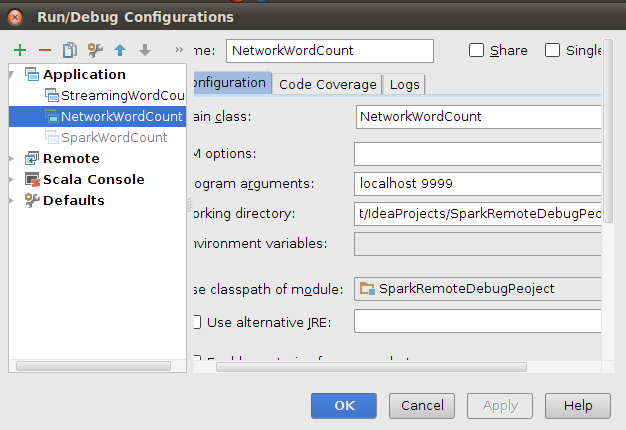
使用
//启动netcat server
root@sparkmaster:~/streaming# nc -lk 9999
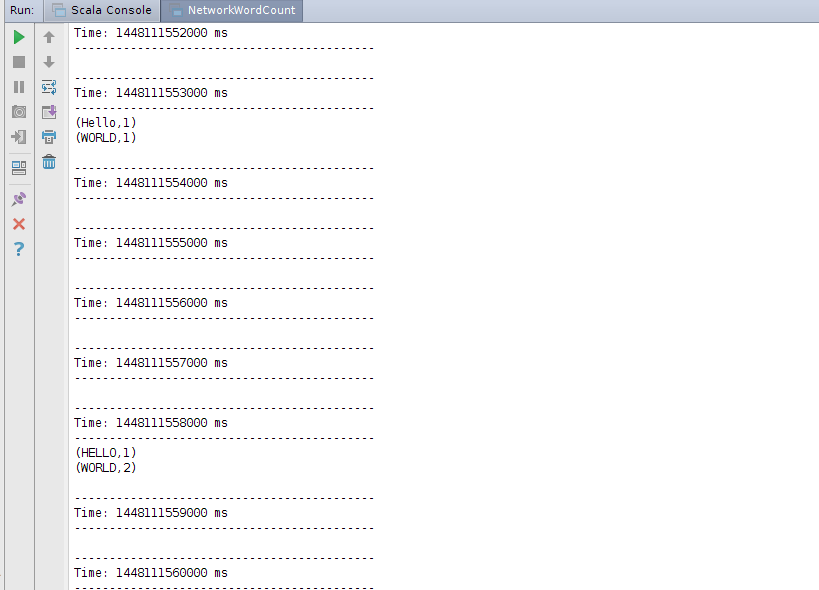
运行NetworkWordCount 程序,然后在netcat server运行的控制台输入任意字符串
root@sparkmaster:~/streaming# nc -lk 9999
Hello WORLD
HELLO WORLD WORLD
TEWST
NIMA
2. QueueStream基于RDD队列的流数据
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable
object QueueStream {
def main(args: Array[String]) {
StreamingExamples.setStreamingLogLevels()
val sparkConf = new SparkConf().setAppName("QueueStream").setMaster("local[4]")
// Create the context
val ssc = new StreamingContext(sparkConf, Seconds(1))
// Create the queue through which RDDs can be pushed to
// a QueueInputDStream
//创建RDD队列
val rddQueue = new mutable.SynchronizedQueue[RDD[Int]]()
// Create the QueueInputDStream and use it do some processing
// 创建QueueInputDStream
val inputStream = ssc.queueStream(rddQueue)
//处理队列中的RDD数据
val mappedStream = inputStream.map(x => (x % 10, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
//打印结果
reducedStream.print()
//启动计算
ssc.start()
// Create and push some RDDs into
for (i <- 1 to 30) {
rddQueue += ssc.sparkContext.makeRDD(1 to 3000, 10)
Thread.sleep(1000)
//通过程序停止StreamingContext的运行
ssc.stop()
}
}
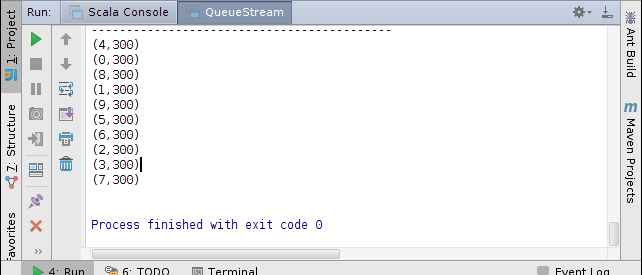
4. DStream Transformation操作
| Transformation | Meaning |
|---|---|
| map(func) | 对DStream中的各个元素进行func函数操作,然后返回一个新的DStream. |
| flatMap(func) | 与map方法类似,只不过各个输入项可以被输出为零个或多个输出项 |
| filter(func) | 过滤出所有函数func返回值为true的DStream元素并返回一个新的DStream |
| repartition(numPartitions) | 增加或减少DStream中的分区数,从而改变DStream的并行度 |
| union(otherStream) | 将源DStream和输入参数为otherDStream的元素合并,并返回一个新的DStream. |
| count() | 通过对DStreaim中的各个RDD中的元素进行计数,然后返回只有一个元素的RDD构成的DStream |
| reduce(func) | 对源DStream中的各个RDD中的元素利用func进行聚合操作,然后返回只有一个元素的RDD构成的新的DStream. |
| countByValue() | 对于元素类型为K的DStream,返回一个元素为(K,Long)键值对形式的新的DStream,Long对应的值为源DStream中各个RDD的key出现的次数 |
| reduceByKey(func, [numTasks]) | 利用func函数对源DStream中的key进行聚合操作,然后返回新的(K,V)对构成的DStream |
| join(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的DStream,返回一个新的(K,(V,W)类型的DStream |
| cogroup(otherStream, [numTasks]) | 输入为(K,V)、(K,W)类型的DStream,返回一个新的 (K, Seq[V], Seq[W]) 元组类型的DStream |
| transform(func) | 通过RDD-to-RDD函数作用于源码DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD |
| updateStateByKey(func) | 根据于key的前置状态和key的新值,对key进行更新,返回一个新状态的DStream |
具体示例:
//读取本地文件~/streaming文件夹
val lines = ssc.textFileStream(args(0))
val words = lines.flatMap(_.split(" "))
val wordMap = words.map(x => (x, 1))
val wordCounts=wordMap.reduceByKey(_ + _)
val filteredWordCounts=wordCounts.filter(_._2>1)
val numOfCount=filteredWordCounts.count()
val countByValue=words.countByValue()
val union=words.union(word1)
val transform=words.transform(x=>x.map(x=>(x,1)))
//显式原文件
lines.print()
//打印flatMap结果
words.print()
//打印map结果
wordMap.print()
//打印reduceByKey结果
wordCounts.print()
//打印filter结果
filteredWordCounts.print()
//打印count结果
numOfCount.print()
//打印countByValue结果
countByValue.print()
//打印union结果
union.print()
//打印transform结果
transform.print()
下面的代码是运行时添加的文件内容
root@sparkmaster:~/streaming# echo "A B C D" >> test12.txt; echo "A B" >> test12.txt
下面是前面各个函数的结果
-------------------------------------------
lines.print()
-------------------------------------------
A B C D
A B
-------------------------------------------
flatMap结果
-------------------------------------------
A
B
C
D
A
B
-------------------------------------------
map结果
-------------------------------------------
(A,1)
(B,1)
(C,1)
(D,1)
(A,1)
(B,1)
-------------------------------------------
reduceByKey结果
-------------------------------------------
(B,2)
(D,1)
(A,2)
(C,1)
-------------------------------------------
filter结果
-------------------------------------------
(B,2)
(A,2)
-------------------------------------------
count结果
-------------------------------------------
2
-------------------------------------------
countByValue结果
-------------------------------------------
(B,2)
(D,1)
(A,2)
(C,1)
-------------------------------------------
union结果
-------------------------------------------
A
B
C
D
A
B
A
B
C
D
...
-------------------------------------------
transform结果
-------------------------------------------
(A,1)
(B,1)
(C,1)
(D,1)
(A,1)
(B,1)
示例2:上节课中演示的WordCount代码并没有只是对输入的单词进行分开计数,没有记录前一次计数的状态,如果想要连续地进行计数,则可以使用updateStateByKey方法来进行。下面的代码主要给大家演示如何updateStateByKey的方法。
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
import org.apache.spark.streaming._
object StatefulNetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: StatefulNetworkWordCount <hostname> <port>")
System.exit(1)
}
//函数字面量,输入的当前值与前一次的状态结果进行累加
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.sum
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
//输入类型为K,V,S,返回值类型为K,S
//V对应为带求和的值,S为前一次的状态
val newUpdateFunc = (iterator: Iterator[(String, Seq[Int], Option[Int])]) => {
iterator.flatMap(t => updateFunc(t._2, t._3).map(s => (t._1, s)))
}
val sparkConf = new SparkConf().setAppName("StatefulNetworkWordCount").setMaster("local[4]")
//每一秒处理一次
val ssc = new StreamingContext(sparkConf, Seconds(1))
//当前目录为checkpoint结果目录,后面会讲checkpoint在Spark Streaming中的应用
ssc.checkpoint(".")
//RDD的初始化结果
val initialRDD = ssc.sparkContext.parallelize(List(("hello", 1), ("world", 1)))
//使用Socket作为输入源,本例ip为localhost,端口为9999
val lines = ssc.socketTextStream(args(0), args(1).toInt)
//flatMap操作
val words = lines.flatMap(_.split(" "))
//map操作
val wordDstream = words.map(x => (x, 1))
//updateStateByKey函数使用
val stateDstream = wordDstream.updateStateByKey[Int](newUpdateFunc,
new HashPartitioner (ssc.sparkContext.defaultParallelism), true, initialRDD)
stateDstream.print()
ssc.start()
ssc.awaitTermination()
}
}
下图是初始时的值:
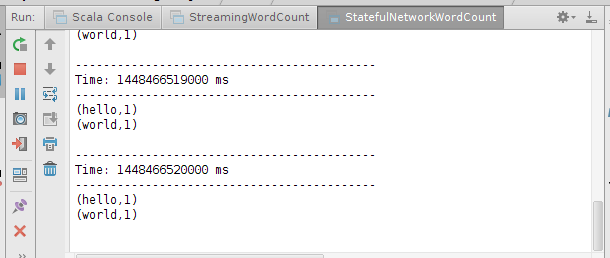
使用下列命令启动netcat server
root@sparkmaster:~/streaming# nc -lk 9999
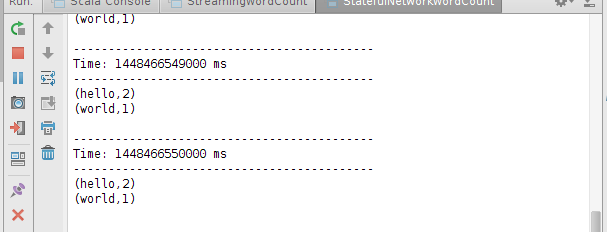
然后输入
root@sparkmaster:~/streaming# nc -lk 9999
hello
将得到下图的结果
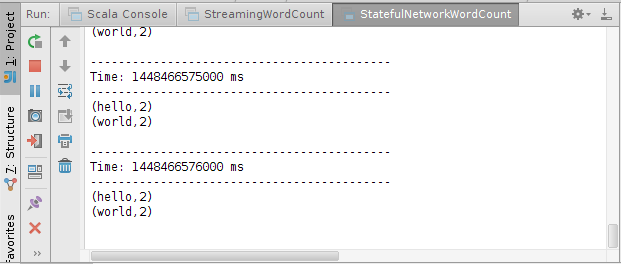
然后再输入world,
root@sparkmaster:~/streaming# nc -lk 9999
hello
world
则将得到下列结果
5. Window Operation
Spark Streaming提供窗口操作(Window Operation),如下图所示:
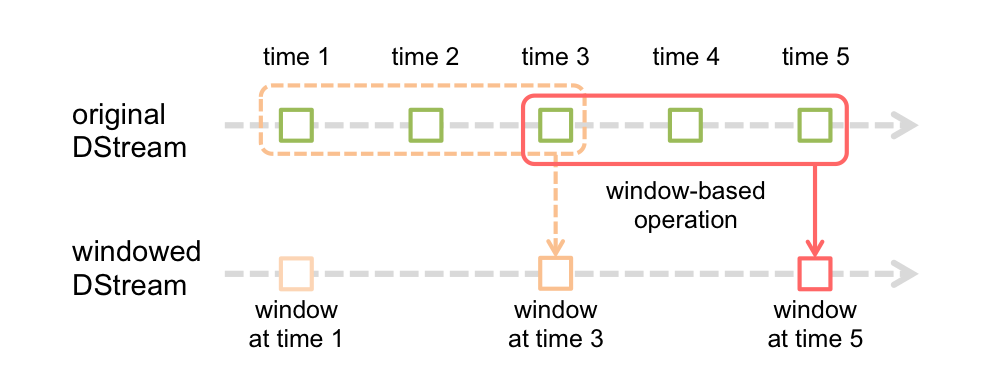
上图中,红色实线表示窗口当前的滑动位置,虚线表示前一次窗口位置,窗口每滑动一次,落在该窗口中的RDD被一起同时处理,生成一个窗口DStream(windowed DStream),窗口操作需要设置两个参数:
(1)窗口长度(window length),即窗口的持续时间,上图中的窗口长度为3
(2)滑动间隔(sliding interval),窗口操作执行的时间间隔,上图中的滑动间隔为2
这两个参数必须是原始DStream 批处理间隔(batch interval)的整数倍(上图中的原始DStream的batch interval为1)
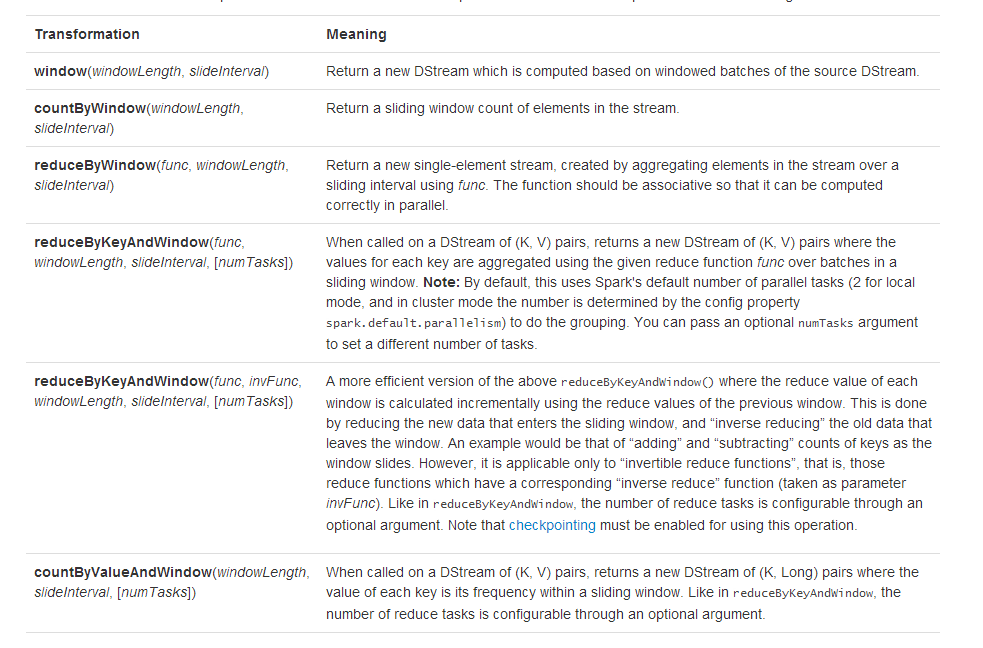
DStream支持的全部Window操作方法如下:
入门案例
1、WindowWordCount——reduceByKeyAndWindow方法使用
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object WindowWordCount {
def main(args: Array[String]) {
//传入的参数为localhost 9999 30 10
if (args.length != 4) {
System.err.println("Usage: WindowWorldCount <hostname> <port> <windowDuration> <slideDuration>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val conf = new SparkConf().setAppName("WindowWordCount").setMaster("local[4]")
val sc = new SparkContext(conf)
// 创建StreamingContext,batch interval为5秒
val ssc = new StreamingContext(sc, Seconds(5))
//Socket为数据源
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_ONLY_SER)
val words = lines.flatMap(_.split(" "))
// windows操作,对窗口中的单词进行计数
val wordCounts = words.map(x => (x , 1)).reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(args(2).toInt), Seconds(args(3).toInt))
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
通过下列代码启动netcat server
root@sparkmaster:~# nc -lk 9999
再运行WindowWordCount
输入下列语句
root@sparkmaster:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data. It provides
观察执行情况:
-------------------------------------------
Time: 1448778805000 ms(10秒,第一个滑动窗口时间)
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448778815000 ms(10秒后,第二个滑动窗口时间)
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448778825000 ms(10秒后,第三个滑动窗口时间)
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448778835000 ms(再经10秒后,超出window length窗口长度,不在计数范围内)
-------------------------------------------
-------------------------------------------
Time: 1448778845000 ms
-------------------------------------------
同样的语句输入两次
root@sparkmaster:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
观察执行结果如下:
Time: 1448779205000 ms
-------------------------------------------
(provides,2)
(is,2)
(general,2)
(Big,2)
(fast,2)
(cluster,2)
(Data.,2)
(computing,2)
(Spark,2)
(a,2)
...
再输入一次
root@sparkmaster:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
计算结果如下:
-------------------------------------------
Time: 1448779215000 ms
-------------------------------------------
(provides,3)
(is,3)
(general,3)
(Big,3)
(fast,3)
(cluster,3)
(Data.,3)
(computing,3)
(Spark,3)
(a,3)
...
再输入一次
root@sparkmaster:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
Spark is a fast and general cluster computing system for Big Data. It provides
计算结果如下:
-------------------------------------------
Time: 1448779225000 ms
-------------------------------------------
(provides,4)
(is,4)
(general,4)
(Big,4)
(fast,4)
(cluster,4)
(Data.,4)
(computing,4)
(Spark,4)
(a,4)
...
-------------------------------------------
Time: 1448779235000 ms
-------------------------------------------
(provides,2)
(is,2)
(general,2)
(Big,2)
(fast,2)
(cluster,2)
(Data.,2)
(computing,2)
(Spark,2)
(a,2)
...
-------------------------------------------
Time: 1448779245000 ms
-------------------------------------------
(provides,1)
(is,1)
(general,1)
(Big,1)
(fast,1)
(cluster,1)
(Data.,1)
(computing,1)
(Spark,1)
(a,1)
...
-------------------------------------------
Time: 1448779255000 ms
-------------------------------------------
-------------------------------------------
Time: 1448779265000 ms
-------------------------------------------
2、WindowWordCount——countByWindow方法使用
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
object WindowWordCount {
def main(args: Array[String]) {
if (args.length != 4) {
System.err.println("Usage: WindowWorldCount <hostname> <port> <windowDuration> <slideDuration>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val conf = new SparkConf().setAppName("WindowWordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
// 创建StreamingContext
val ssc = new StreamingContext(sc, Seconds(5))
// 定义checkpoint目录为当前目录
ssc.checkpoint(".")
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_ONLY_SER)
val words = lines.flatMap(_.split(" "))
//countByWindowcountByWindow方法计算基于滑动窗口的DStream中的元素的数量。
val countByWindow=words.countByWindow(Seconds(args(2).toInt), Seconds(args(3).toInt))
countByWindow.print()
ssc.start()
ssc.awaitTermination()
}
}
启动
root@sparkmaster:~# nc -lk 9999
然后运行WindowWordCount
输入
root@sparkmaster:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data
察看运行结果:
-------------------------------------------
Time: 1448780625000 ms
-------------------------------------------
0
-------------------------------------------
Time: 1448780635000 ms
-------------------------------------------
12
-------------------------------------------
Time: 1448780645000 ms
-------------------------------------------
12
-------------------------------------------
Time: 1448780655000 ms
-------------------------------------------
12
-------------------------------------------
Time: 1448780665000 ms
-------------------------------------------
0
-------------------------------------------
Time: 1448780675000 ms
-------------------------------------------
0
3、WindowWordCount——reduceByWindow方法使用
//reduceByWindow方法基于滑动窗口对源DStream中的元素进行聚合操作,返回包含单元素的一个新的DStream。
val reduceByWindow=words.map(x=>1).reduceByWindow(_+_,_-_Seconds(args(2).toInt), Seconds(args(3).toInt))
上面的例子其实是countByWindow的实现,可以在countByWindow源码实现中得到验证
def countByWindow(
windowDuration: Duration,
slideDuration: Duration): DStream[Long] = ssc.withScope {
this.map(_ => 1L).reduceByWindow(_ + _, _ - _, windowDuration, slideDuration)
}
而reduceByWindow又是通过reduceByKeyAndWindow方法来实现的,具体代码如下
def reduceByWindow(
reduceFunc: (T, T) => T,
invReduceFunc: (T, T) => T,
windowDuration: Duration,
slideDuration: Duration
): DStream[T] = ssc.withScope {
this.map(x => (1, x))
.reduceByKeyAndWindow(reduceFunc, invReduceFunc, windowDuration, slideDuration, 1)
.map(_._2)
}
与前面的例子中的reduceByKeyAndWindow方法不同的是这里的reduceByKeyAndWindow方法多了一个invReduceFunc参数。
具体来讲,下面两个方法得到的结果是一样的,只是效率不同,后面的方法方式效率更高:
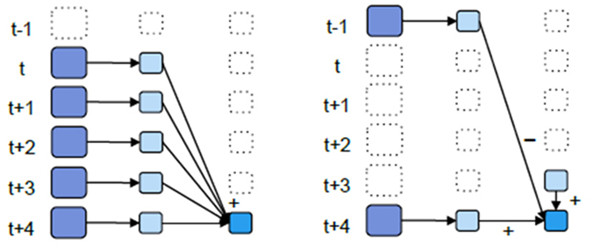
//以过去5秒钟为一个输入窗口,每1秒统计一下WordCount,本方法会将过去5秒钟的每一秒钟的WordCount都进行统计
//然后进行叠加,得出这个窗口中的单词统计。 这种方式被称为叠加方式,如下图左边所示
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, Seconds(5s),seconds(1))
与
//计算t+4秒这个时刻过去5秒窗口的WordCount,可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量
//再减去[t-2,t-1]的统计量,这种方法可以复用中间三秒的统计量,提高统计的效率。 这种方式被称为增量方式,如下图的右边所示
val wordCounts = words.map(x => (x, 1)).reduceByKeyAndWindow(_ + _, _ - _, Seconds(5s),seconds(1))
6. Spark SQL、DataFrame与Spark Streaming
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Time, Seconds, StreamingContext}
import org.apache.spark.util.IntParam
import org.apache.spark.sql.SQLContext
import org.apache.spark.storage.StorageLevel
object SqlNetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
// Create the context with a 2 second batch size
val sparkConf = new SparkConf().setAppName("SqlNetworkWordCount").setMaster("local[4]")
val ssc = new StreamingContext(sparkConf, Seconds(2))
// Create a socket stream on target ip:port and count the
// words in input stream of \n delimited text (eg. generated by 'nc')
// Note that no duplication in storage level only for running locally.
// Replication necessary in distributed scenario for fault tolerance.
//Socke作为数据源
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
//words DStream
val words = lines.flatMap(_.split(" "))
// Convert RDDs of the words DStream to DataFrame and run SQL query
//调用foreachRDD方法,遍历DStream中的RDD
words.foreachRDD((rdd: RDD[String], time: Time) => {
// Get the singleton instance of SQLContext
val sqlContext = SQLContextSingleton.getInstance(rdd.sparkContext)
import sqlContext.implicits._
// Convert RDD[String] to RDD[case class] to DataFrame
val wordsDataFrame = rdd.map(w => Record(w)).toDF()
// Register as table
wordsDataFrame.registerTempTable("words")
// Do word count on table using SQL and print it
val wordCountsDataFrame =
sqlContext.sql("select word, count(*) as total from words group by word")
println(s"========= $time =========")
wordCountsDataFrame.show()
})
ssc.start()
ssc.awaitTermination()
}
}
/** Case class for converting RDD to DataFrame */
case class Record(word: String)
/** Lazily instantiated singleton instance of SQLContext */
object SQLContextSingleton {
@transient private var instance: SQLContext = _
def getInstance(sparkContext: SparkContext): SQLContext = {
if (instance == null) {
instance = new SQLContext(sparkContext)
}
instance
}
}
运行程序后,再运行下列命令
root@sparkmaster:~# nc -lk 9999
Spark is a fast and general cluster computing system for Big Data
Spark is a fast and general cluster computing system for Big Data
Spark is a fast and general cluster computing system for Big Data
Spark is a fast and general cluster computing system for Big Data
Spark is a fast and general cluster computing system for Big Data
Spark is a fast and general cluster computing system for Big Data
Spark is a fast and general cluster computing system for Big Data
处理结果:
========= 1448783840000 ms =========
+---------+-----+
| word|total|
+---------+-----+
| Spark| 12|
| system| 12|
| general| 12|
| fast| 12|
| and| 12|
|computing| 12|
| a| 12|
| is| 12|
| for| 12|
| Big| 12|
| cluster| 12|
| Data| 12|
+---------+-----+
========= 1448783842000 ms =========
+----+-----+
|word|total|
+----+-----+
+----+-----+
========= 1448783844000 ms =========
+----+-----+
|word|total|
+----+-----+
+----+-----+
7. Checkpoint机制
Spark Streaming应用程序如果不手动停止,则将一直运行下去,在实际中应用程序一般是24小时*7天不间断运行的,因此Streaming必须对诸如系统错误、JVM出错等与程序逻辑无关的错误(failures )具有很强的弹性,具备一定的非应用程序出错的容错性。Spark Streaming的Checkpoint机制便是为此设计的,它将足够多的信息checkpoint到某些具备容错性的存储系统如HDFS上,以便出错时能够迅速恢复。有两种数据可以chekpoint:
-
Metadata checkpointing
将流式计算的信息保存到具备容错性的存储上如HDFS,Metadata Checkpointing适用于当streaming应用程序Driver所在的节点出错时能够恢复,元数据包括:
- Configuration(配置信息) - 创建streaming应用程序的配置信息
- DStream operations - 在streaming应用程序中定义的DStreaming操作
- Incomplete batches - 在列队中没有处理完的作业
-
Data checkpointing
将生成的RDD保存到外部可靠的存储当中,对于一些数据跨度为多个bactch的有状态tranformation操作来说,checkpoint非常有必要,因为在这些transformation操作生成的RDD对前一RDD有依赖,随着时间的增加,依赖链可能会非常长,checkpoint机制能够切断依赖链,将中间的RDD周期性地checkpoint到可靠存储当中,从而在出错时可以直接从checkpoint点恢复。
具体来说,metadata checkpointing主要还是从drvier失败中恢复,而Data Checkpoing用于对有状态的transformation操作进行checkpointing
Checkpointing具体的使用方式时通过下列方法:
//checkpointDirectory为checkpoint文件保存目录
streamingContext.checkpoint(checkpointDirectory)
案例
import java.io.File
import java.nio.charset.Charset
import com.google.common.io.Files
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Time, Seconds, StreamingContext}
import org.apache.spark.util.IntParam
/**
* Counts words in text encoded with UTF8 received from the network every second.
*
* Usage: RecoverableNetworkWordCount <hostname> <port> <checkpoint-directory> <output-file>
* <hostname> and <port> describe the TCP server that Spark Streaming would connect to receive
* data. <checkpoint-directory> directory to HDFS-compatible file system which checkpoint data
* <output-file> file to which the word counts will be appended
*
* <checkpoint-directory> and <output-file> must be absolute paths
*
* To run this on your local machine, you need to first run a Netcat server
*
* `$ nc -lk 9999`
*
* and run the example as
*
* `$ ./bin/run-example org.apache.spark.examples.streaming.RecoverableNetworkWordCount \
* localhost 9999 ~/checkpoint/ ~/out`
*
* If the directory ~/checkpoint/ does not exist (e.g. running for the first time), it will create
* a new StreamingContext (will print "Creating new context" to the console). Otherwise, if
* checkpoint data exists in ~/checkpoint/, then it will create StreamingContext from
* the checkpoint data.
*
* Refer to the online documentation for more details.
*/
object RecoverableNetworkWordCount {
def createContext(ip: String, port: Int, outputPath: String, checkpointDirectory: String)
: StreamingContext = {
//程序第一运行时会创建该条语句,如果应用程序失败,则会从checkpoint中恢复,该条语句不会执行
println("Creating new context")
val outputFile = new File(outputPath)
if (outputFile.exists()) outputFile.delete()
val sparkConf = new SparkConf().setAppName("RecoverableNetworkWordCount").setMaster("local[4]")
// Create the context with a 1 second batch size
val ssc = new StreamingContext(sparkConf, Seconds(1))
ssc.checkpoint(checkpointDirectory)
//将socket作为数据源
val lines = ssc.socketTextStream(ip, port)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.foreachRDD((rdd: RDD[(String, Int)], time: Time) => {
val counts = "Counts at time " + time + " " + rdd.collect().mkString("[", ", ", "]")
println(counts)
println("Appending to " + outputFile.getAbsolutePath)
Files.append(counts + "\n", outputFile, Charset.defaultCharset())
})
ssc
}
//将String转换成Int
private object IntParam {
def unapply(str: String): Option[Int] = {
try {
Some(str.toInt)
} catch {
case e: NumberFormatException => None
}
}
}
def main(args: Array[String]) {
if (args.length != 4) {
System.err.println("You arguments were " + args.mkString("[", ", ", "]"))
System.err.println(
"""
|Usage: RecoverableNetworkWordCount <hostname> <port> <checkpoint-directory>
| <output-file>. <hostname> and <port> describe the TCP server that Spark
| Streaming would connect to receive data. <checkpoint-directory> directory to
| HDFS-compatible file system which checkpoint data <output-file> file to which the
| word counts will be appended
|
|In local mode, <master> should be 'local[n]' with n > 1
|Both <checkpoint-directory> and <output-file> must be absolute paths
""".stripMargin
)
System.exit(1)
}
val Array(ip, IntParam(port), checkpointDirectory, outputPath) = args
//getOrCreate方法,从checkpoint中重新创建StreamingContext对象或新创建一个StreamingContext对象
val ssc = StreamingContext.getOrCreate(checkpointDirectory,
() => {
createContext(ip, port, outputPath, checkpointDirectory)
})
ssc.start()
ssc.awaitTermination()
}
}
输入参数配置如下:
运行状态图如下:
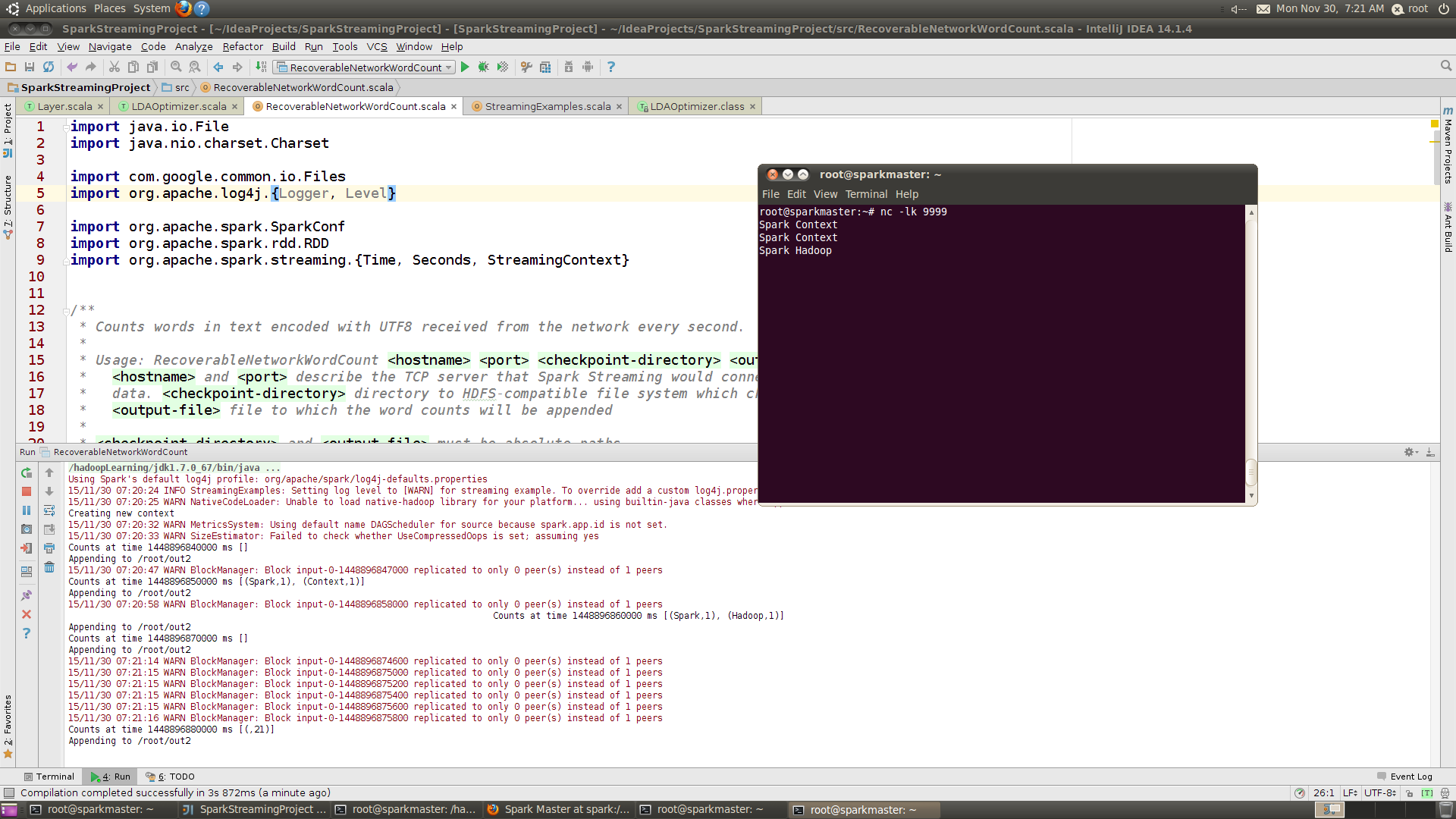
首次运行时:
//创建新的StreamingContext
Creating new context
15/11/30 07:20:32 WARN MetricsSystem: Using default name DAGScheduler for source because spark.app.id is not set.
15/11/30 07:20:33 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
Counts at time 1448896840000 ms []
Appending to /root/out2
15/11/30 07:20:47 WARN BlockManager: Block input-0-1448896847000 replicated to only 0 peer(s) instead of 1 peers
Counts at time 1448896850000 ms [(Spark,1), (Context,1)]
手动将程序停止,然后重新运行
//这时从checkpoint目录中读取元数据信息,进行StreamingContext的恢复
Counts at time 1448897070000 ms []
Appending to /root/out2
Counts at time 1448897080000 ms []
Appending to /root/out2
Counts at time 1448897090000 ms []
Appending to /root/out2
15/11/30 07:24:58 WARN BlockManager: Block input-0-1448897098600 replicated to only 0 peer(s) instead of 1 peers
[Stage 8:> (0 + 0) / 4]Counts at time 1448897100000 ms [(Spark,1), (Context,1)]
Appending to /root/out2
8. kafka 集群搭建
参考链接:Spark修炼之道(进阶篇)——Spark入门到精通:第十六节 Spark Streaming与Kafka
9. Spark Streaming与Kafka
Spark Streaming与Kafka版本的WordCount示例 (一)
-
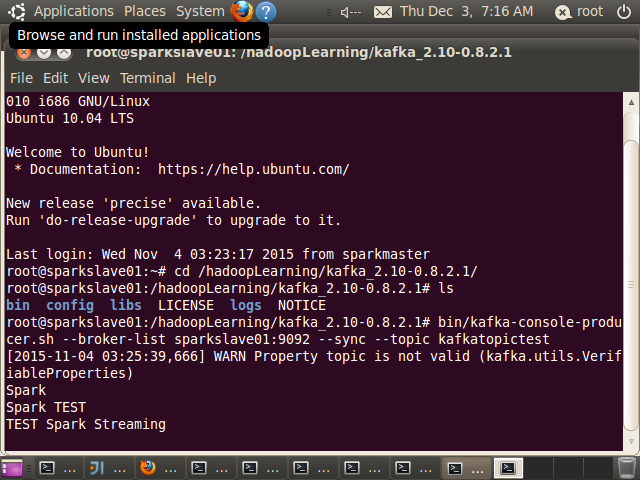
启动kafka集群
root@sparkslave02:/hadoopLearning/kafka_2.10-0.8.2.1# bin/kafka-server-start.sh config/server.properties root@sparkslave01:/hadoopLearning/kafka_2.10-0.8.2.1# bin/kafka-server-start.sh config/server.properties root@sparkmaster:/hadoopLearning/kafka_2.10-0.8.2.1# bin/kafka-server-start.sh config/server.properties -
向kafka集群发送消息
root@sparkslave01:/hadoopLearning/kafka_2.10-0.8.2.1# bin/kafka-console-producer.sh --broker-list sparkslave01:9092 --sync --topic kafkatopictest -
编写如下程序
import org.apache.kafka.clients.producer.{ProducerConfig, KafkaProducer, ProducerRecord}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.streaming._
import org.apache.spark.streaming.kafka._
import org.apache.spark.{Logging, SparkConf}
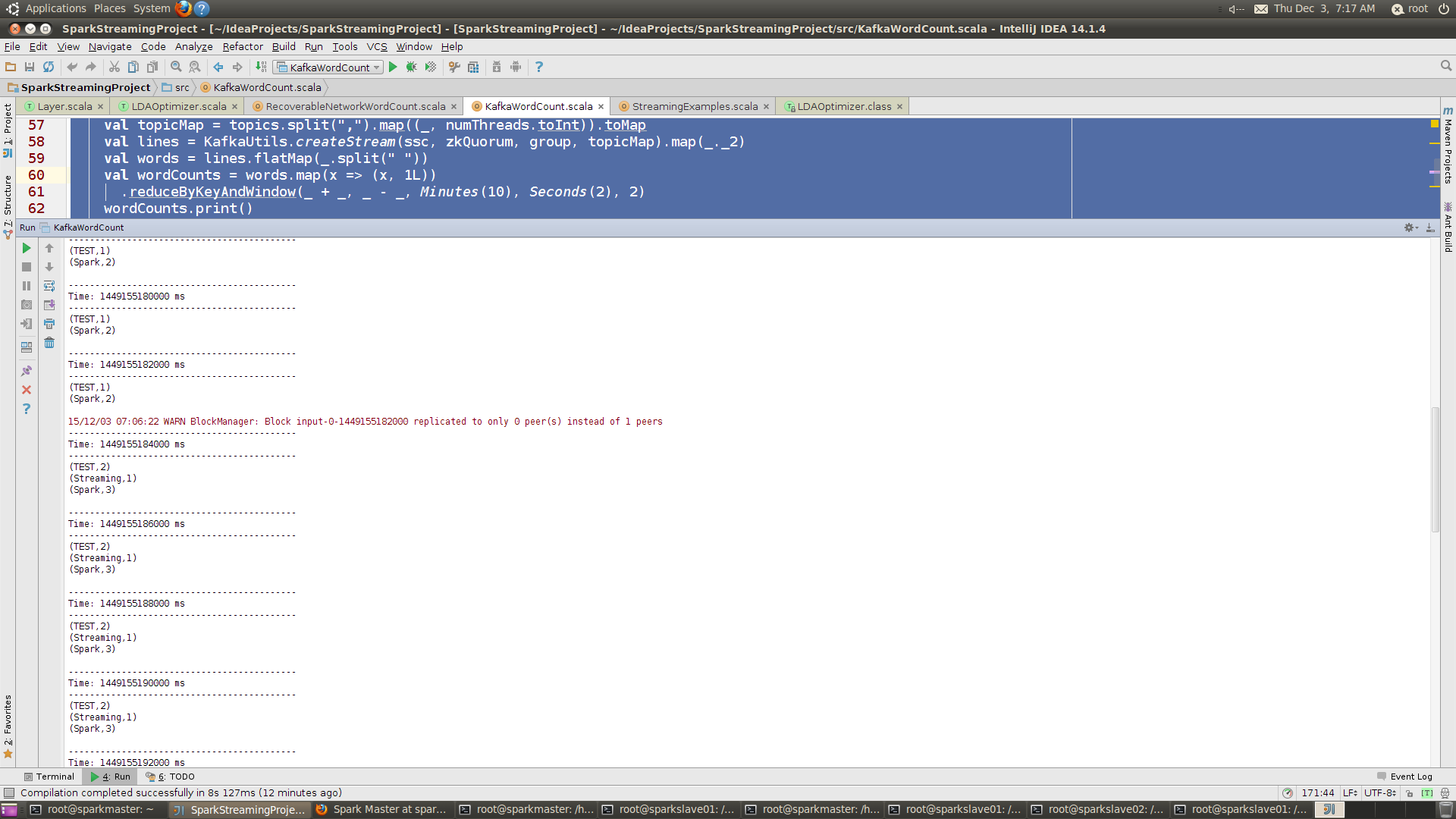
object KafkaWordCount {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCount <zkQuorum> <group> <topics> <numThreads>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount").setMaster("local[4]")
val ssc = new StreamingContext(sparkConf, Seconds(2))
ssc.checkpoint("checkpoint")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
//创建ReceiverInputDStream
val lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_ + _, _ - _, Minutes(10), Seconds(2), 2)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
配置运行参数:
具体如下:
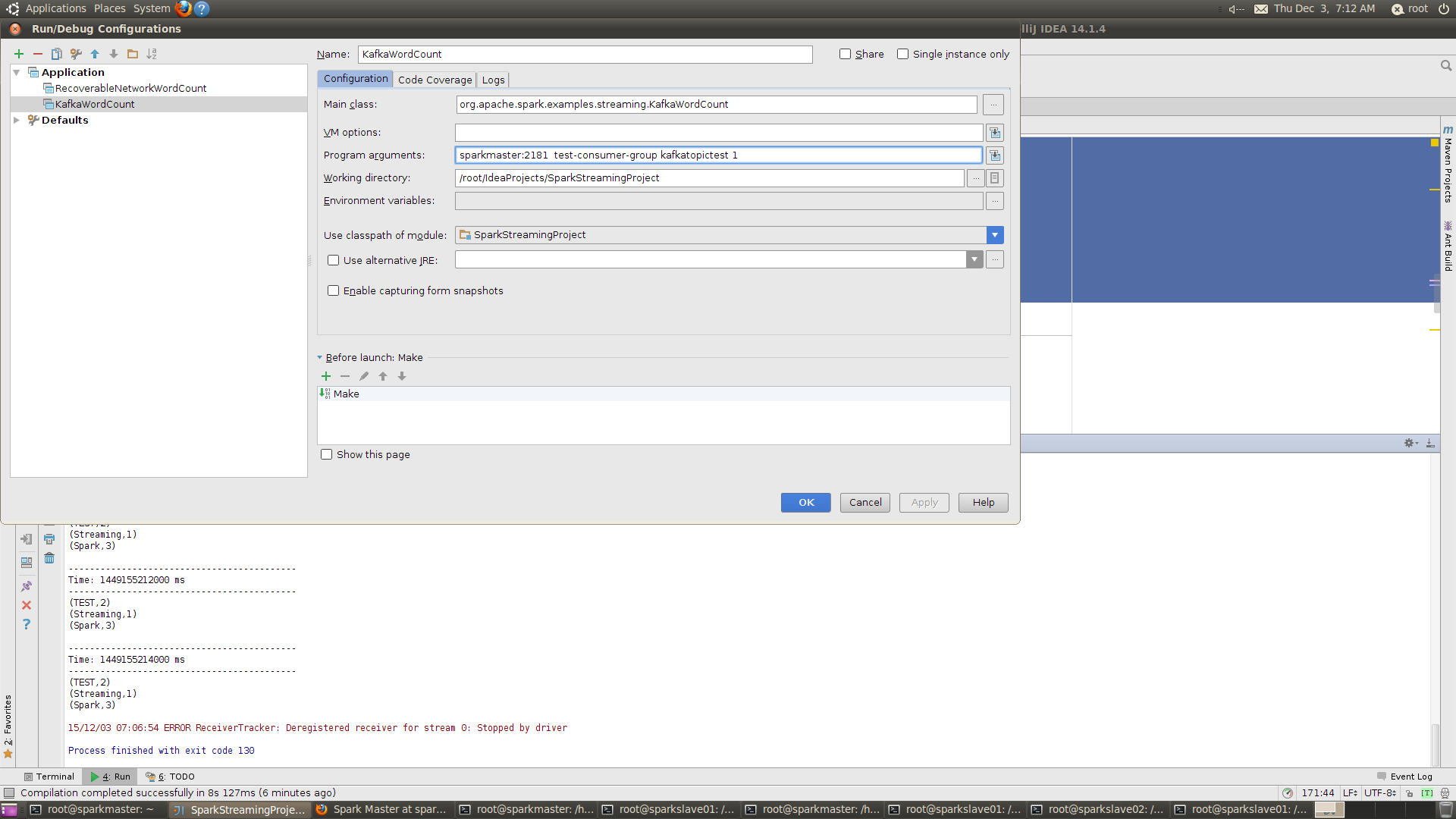
sparkmaster:2181 test-consumer-group kafkatopictest 1
- sparkmaster:2181,zookeeper监听地址
- test-consumer-group, consumer-group的名称,必须和$KAFKA_HOME/config/consumer.properties中的group.id的配置内容一致
- kafkatopictest,topic名称
- 1,线程数
运行KafkaWordCount 后,在producer中输入下列内容
root@sparkslave01:/hadoopLearning/kafka_2.10-0.8.2.1# bin/kafka-console-producer.sh --broker-list sparkslave01:9092 --sync --topic kafkatopictest
[2015-11-04 03:25:39,666] WARN Property topic is not valid (kafka.utils.VerifiableProperties)
Spark
Spark TEST
TEST Spark Streaming
得到结果如下:
Spark Streaming与Kafka版本的WordCount示例(二)
前面的例子中,producer是通过kafka的脚本生成的,本例中将给出通过编写程序生成的producer
// 随机生成1-100间的数字
object KafkaWordCountProducer {
def main(args: Array[String]) {
if (args.length < 4) {
System.err.println("Usage: KafkaWordCountProducer <metadataBrokerList> <topic> " +
"<messagesPerSec> <wordsPerMessage>")
System.exit(1)
}
val Array(brokers, topic, messagesPerSec, wordsPerMessage) = args
// Zookeeper连接属性配置
val props = new HashMap[String, Object]()
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
//创建KafkaProducer
val producer = new KafkaProducer[String, String](props)
// 向kafka集群发送消息
while(true) {
(1 to messagesPerSec.toInt).foreach { messageNum =>
val str = (1 to wordsPerMessage.toInt).map(x => scala.util.Random.nextInt(10).toString)
.mkString(" ")
val message = new ProducerRecord[String, String](topic, null, str)
producer.send(message)
}
Thread.sleep(1000)
}
}
}
KafkaWordCountProducer 运行参数设置如下:
sparkmaster:9092 kafkatopictest 5 8
- sparkmaster:9092,broker-list
- kafkatopictest,top名称
- 5表示每秒发多少条消息
- 8表示每条消息中有几个单词
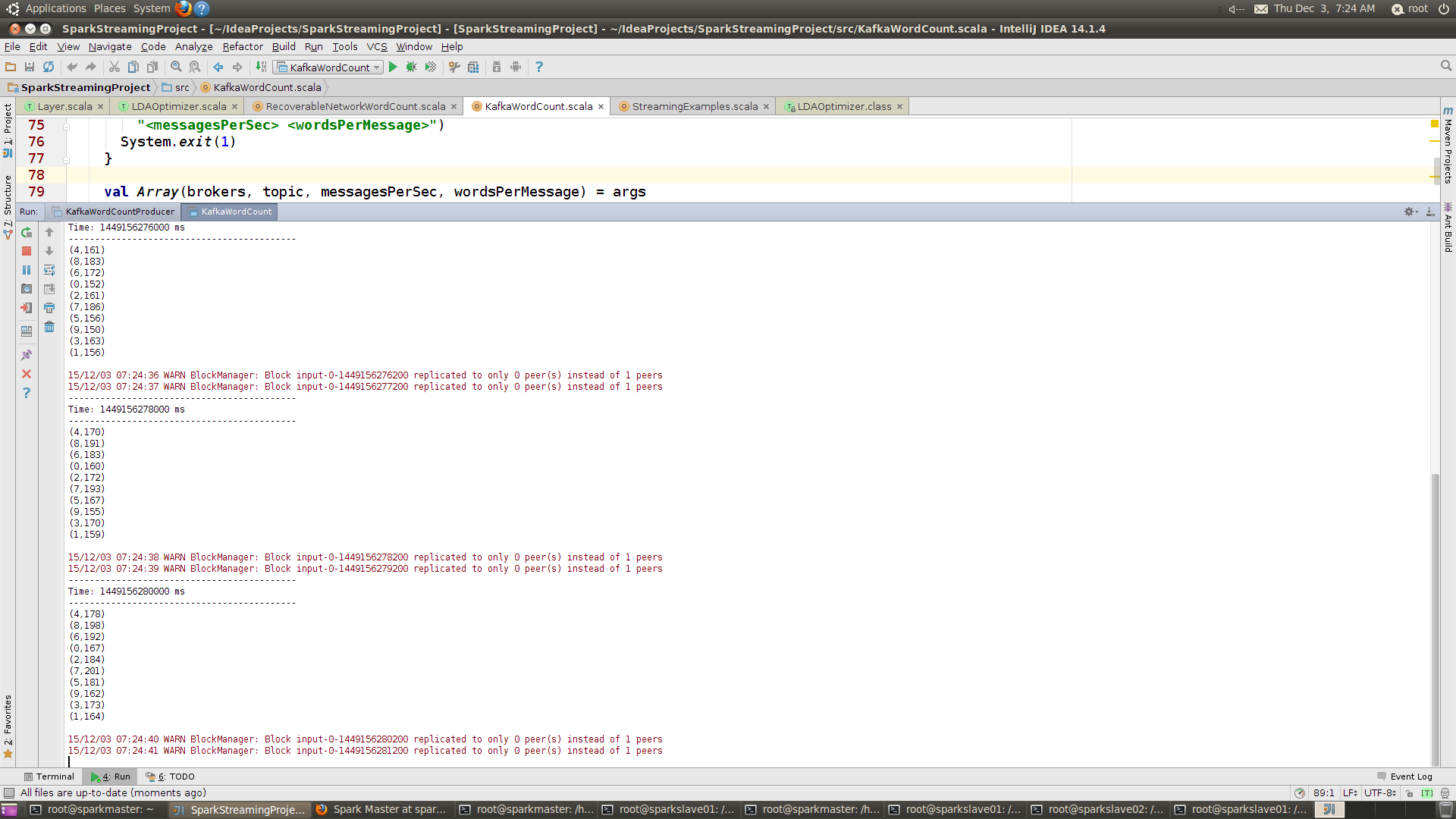
先KafkaWordCountProducer,然后再运行KafkaWordCount ,得到的计算结果如下:















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









