







现象:一个接口在4C的机器上跑最大只有7TPS,CPU使用率就已经90%多。
定位:
1、 使用top命令查看CPU使用情况,找到进程号
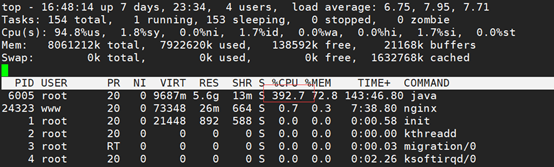
2、 使用top -H -pid命令,查看进程信息,看到有四个进程CPU占用很高,加一起已经超过100%:
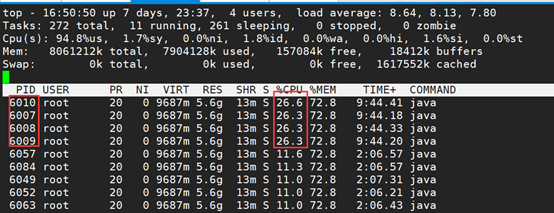
3、 查看具体的线程信息,先使用printf "%x\n" 6007,将线程ip转换成16进制,结果为1777。
4、使用jstack pid |grep pid 命令,查看具体的线程信息,打印结果发现是GC线程,对四个占用CPU高的线程逐一分析,发现刚好都是下面的四个线程,至此,初步定位性能问题是有GC引起的。
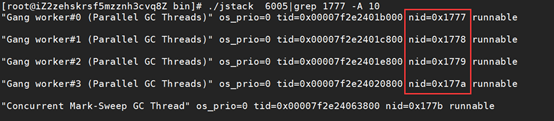
5、 配置好java visualvm ,查看GC情况,结果如下,FULL GC不存在问题,不存在内存泄漏问题,把问题缩小到年轻代。
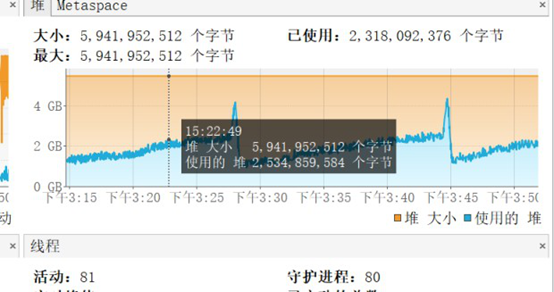
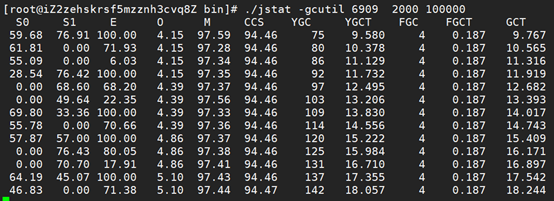
6、 使用jstat -gcutil pid命令,查看具体gc信息,发现Eden区大概5s会满一次。
7、 查看gc日志,看到minor gc频率跟高,关键是一次minor gc的时间很长,用户耗时达到了500多ms,一般几毫米,最高几十毫秒正常,至此,基本把问题定位到是有minor gc,性能问题是由于minor gc太频繁且耗时长造成的,初步猜测两个原因,一是由于Eden区过小,另一个是由于对象过大,先从简单的排查,加大Eden区看看:

8、查看JVM配置,关系到年轻代的信息基本上就是这几个参数,发现Eden配置的确实小,而且垃圾的时间有点长,感觉开发配置的不太合理,所以去掉了后面三JVM参数,使用默认设置,重启服务,使配置生效:

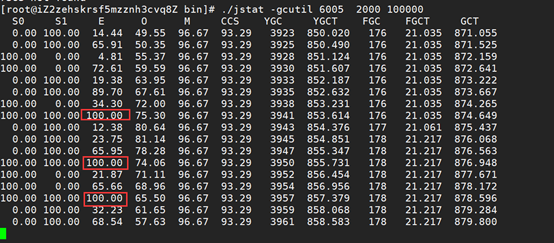
9、重启完后,再次使用jstat命令,发现gc频率降低了一半,但悲剧的是,gc的时间翻了一倍,TPS依然没变,至此确实和JVM配置无关,需要关注对象大小。

10、查看线程信息,找到部署相关的项目,定位到具体的方法:

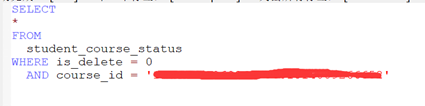
11、找到代码,是一个select操作,返回的是select的结果:

12、继续定位到具体的SQL:
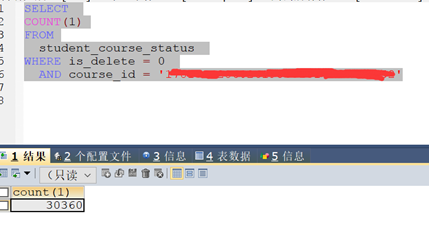
13、查看这个SQL返回的结果,有三万多条,至此基本确定问题所在,返回的list过大,导致Eden区很快就满,而且回收缓慢,造成垃圾回收出现问题,同时GC占用大量CPU,导致CPU使用过高,最终就出现了看见的TPS只有7,CPU就满了的问题。
总结:因为性能测试数据是我们自己造的,第一反应是我们造的数据有问题,再次确认后,发现我们数据没问题,这个查询的where条件传的是课次信息,一个课次有几万学生属于正常数据。正常情况下查这个表时会同时带上学生id,这样的结果不会超过十条,不会存在问题。但是开发为了方便,调用了之前的方法,结果就出现了这样的问题。
反思:其实这个问题是可以通过慢查询日志来定位的,由于我们这个项目用的是阿里云的机器,运维不给配权限,我们只好用MONyog这个工具监控慢查询,而且使用发现,不好用。除此之外,还有经验问题,由于我们数据量不是特别大,百万以下的表居多,按照以往的经验,只要走到索引都不会出现慢SQL,所以很多SQL执行时我都会explain看一下。另一个原因是当时这个项目提交了太多接口,没时间考虑太多,抱着先出个结果的态度进行的压测,此次问题的定位也是在所有接口压测完才去看的,当时看到是由于对象过大引起的性能问题,就想到了之前确实有一个SQL查到了很多数据,通过这次测试,以后在调脚本的时候,需要对SQL的结果进行关注了。
PS:其实有另一个方法定位问题,使用jmap -histo:live 10270 >2.txt ,直接看内存的对象,可以直接看到哪个对象大,然后去代码里看这个对象是什么,更直接方便。














 2639
2639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









