







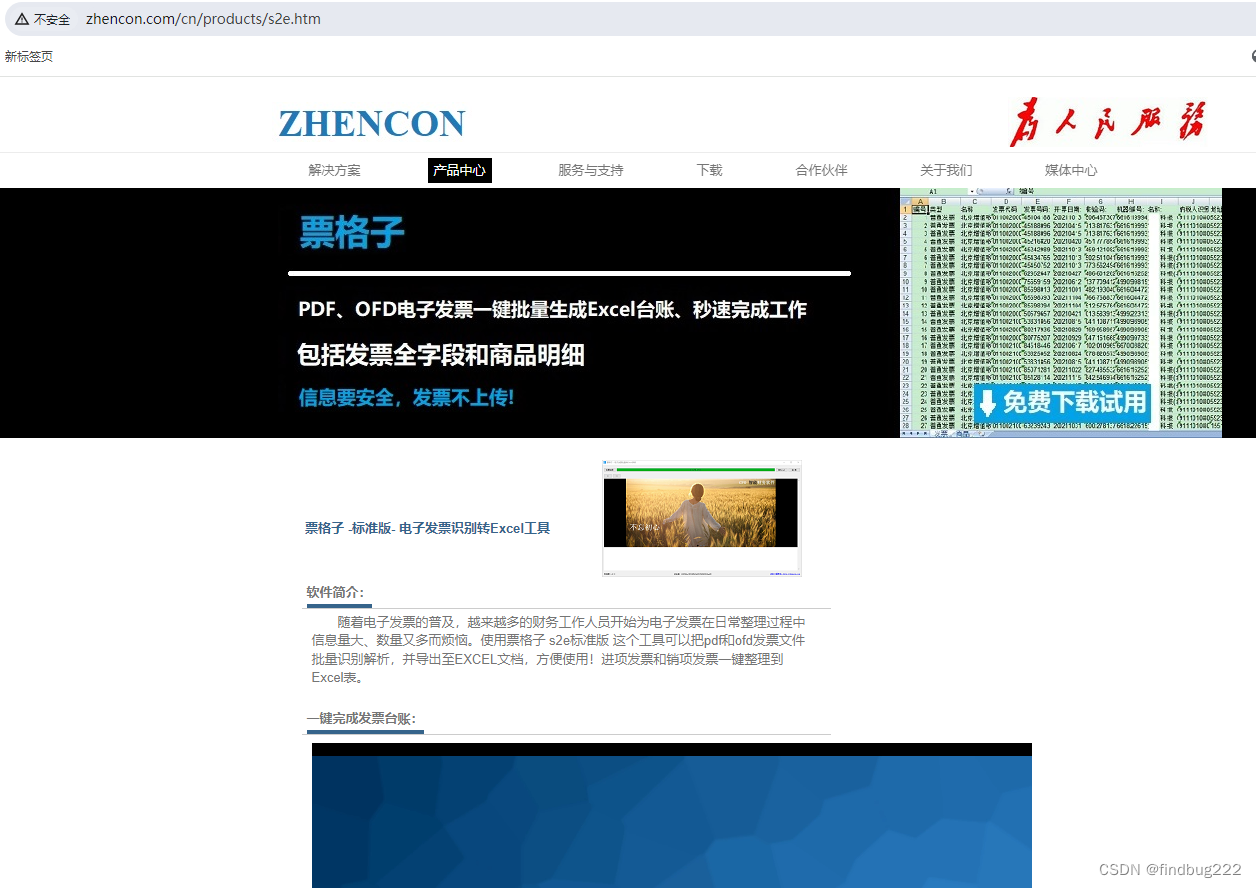
1、首先从网站下载压缩包
打开浏览器输入网址访问网站: http://www.zhencon.com/cn/products/s2e.htm 拉到下面下载部分。点击下载链接下载。
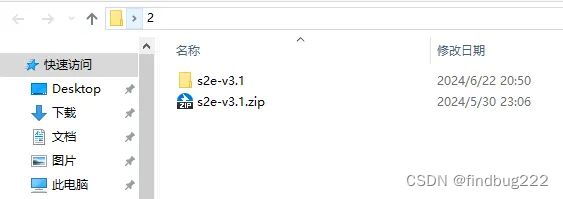
2、解压缩包到文件夹。
建议不要放在C盘和桌面。
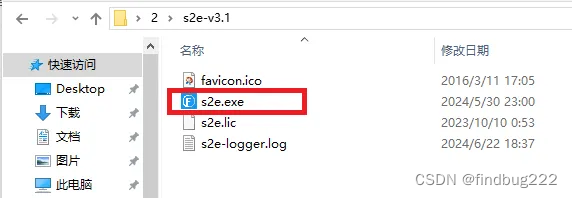
3、进入解开的文件夹里,双击.exe后缀的主文件运行。(授权lic文件放在同目录下)
4、稍等片刻即可显示软件界面。
5、点击“发票目录”按钮,选择发票所在目录后,点击转Excel按钮,完成后即可在发票目录下看到生成的发票台账Excel文件。还有批量查验和入账标识Excel文件。
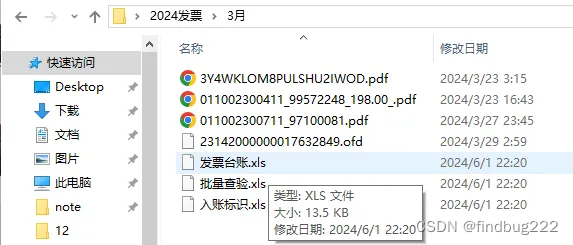
以上就是票格子发票识别软件的使用方法。希望能帮到大家。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









