







来源:http://www.tianyablog.com/blogger/post_show.asp?BlogID=132885& PostID=2101963&idWriter=0&Key=0
现有互联网的飞速发展使它的缺陷逐渐暴露了出来,如网页功能单调、搜索引擎智能化程度低等,这是因为大部分Web上的内容是设计给人阅读的,而不是让计算机程序按其意义进行操作的。计算机能熟练地解析网页的版面,知道哪里是标题,哪里有与其他页面的链接。但是,它分辨不出个人主页和天气预报的区别,因为没有可靠的方法来处理其中的语义,没有办法智能地理解网页内容和进行操作。
语义Web就是想弥补这方面的不足,为网页扩展了计算机可处理的语义信息。语义Web中,各种资源被人为地赋予了各种明确的语义信息,计算机可以分辨和识别这些语义信息,并对其自动进行解释、交换和处理。但是语义 Web与人工智能中的语义网络是两个不同的概念,它的研究对象和所采用的方法与传统自然语言处理也是不同的,它对现有的Web进行了语义扩展,从而使其能被计算机做一定的理解和处理,从功能上看它将是一个能够“理解”人类信息的智能网络。将语义Web融入现在Web结构的初步努力已经在进行中了。不久的将来,当机器有更强的能力去处理和“理解”数据时,我们将看到很多重要的新功能。例如,某人想报名参加一个研讨会,计算机就可自动地为其制定最佳日程和路线以及预定酒店等。
互联网的创始人Tim Berners-Lee在2000年提出了语义Web的概念和体系结构。
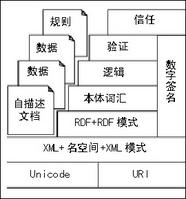
在其体系结构中,第一层是Unicode和URI,它是整个语义Web的基础,Unicode(统一编码)处理资源的编码,URI(统一资源定位器)负责 标识资源;第二层是XML+名空间+XML模式,用于表示数据的内容和结构;第三层是RDF+RDF模式,用于描述资源及其类型;第四层是本体词汇,用于描述各种资源之间的联系;第五层是逻辑,在下面四层的基础上进行逻辑推理操作;第六层是验证,根据逻辑陈述进行验证以得出结论;第七层是信任,在用户间建立信任关系。
第二、三、四层是语义Web的关键层,用于表示Web信息的语义,也是现在语义Web研究的热点所在。可扩展标记语言XML (eXtensible Markup Language)让每个人都能创建自己的标签,来对网页或页面的部分文字进行注释。 脚本,或者说是程序,可以将这些标签运用到复杂的应用中,不过程序编写者必须知道网页作者是如何使用每一个标签的。简而言之,XML允许用户在文档中加入任意的结构。资源描述框架RDF(Resource Description Framework )的基本结构是对象-属性-值三元组,也就相当于句子中的主语、动词和宾语。这些三元组可以用XML语法来表示。用这种结构描述由机器处理的大量数据,是非常自然的方法。RDF模式是一个描述RDF资源的属性(Property)和类(Class)的词汇表,提供了关于这些属性和类的层次结构的语义。
因为两个系统可能采用不同的标识符表示同一概念,也可能用一个标识符表示不同的含义,程序若要在两个数据库之间进行信息的比较和合并,就必须了解某些标识符表示的是否是同一事物。对该问题的一个解决方法就是本体论(Ontology)。本体是概念化的显式说明,包括分类和一套推理规则。分类定义对象的类别及其之间的关系,使我们能够表达实体之间的大量关系,而根据推理规则,程序可以进行自动推理。简单地说,就是在不同的系统间定义一本字典或者度量表,使它们对实体及其之间的关系达成共识,以便交流和共享。
语义Web需要能够对Web文档中的术语含义进行形式化描述。DAML+OIL(即DARPA代理标记语言+本体推论语言),OWL(Web本体语言), 它们是W3C规范的重要扩充和改进,都是建立在人工智能知识表示基础之上的本体语言,提供了一种自然方式来描述在Web词间的类与子类之间的关系,以及在 类与类之间(或子类与子类之间)关系上的限制。它们比RDF模式添加了更多的用于描述属性和类的词汇,例如类之间的不相交性 (Disjointness)、等价性、更丰富的属性类型、属性特征等。
当然,要实现语义Web是远远不够的,更主要的技术难题还在于要让电脑可以进行更多的“思考”和“推断”。为使语义Web工作,计算机必须能访问结构化的信息集合以及一套推理规则,据此进行自动推理。增加逻辑性——使用规则去推理,选择行动的方式以及回答问题的方法——是语义Web组织面临的一个任务。
有了大量富含语义信息的网页,就好像有了一个巨大的全球互联的数据库。有了语义信息的帮助,人们开发出的软件代理Agent程序的智能和自动化将大大提高,它们从不同的资源中收集网页内容,搜索和处理信息并和其他程序交换信息,真正发挥语义Web的力量。当出现更多的机器可处理的网页内容和服务(包括更 多的代理)时,通过代理之间的信息交换和协同工作,信息处理的效率将呈指数级增长,能更好地满足用户的需求。















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









