






https://blog.csdn.net/sinat_29047129/article/details/103642140
理解混淆矩阵
概念
混淆矩阵(Confusion Matrix),一个分类模型的评价指标,统计归对类、归错类的样本的个数(对图像来说就是样本就是所有像素),然后把结果放在一个表里展示出来,这个表就是混淆矩阵。
初步理解混淆矩阵
以二分类混淆矩阵作为入门,多分类混淆矩阵都是以二分类为基础作为延伸的!
Q: 什么是二分类?
A: 顾名思义,分类器(又叫:网络模型、学习器)对两个类别进行分类处理的问题,就叫二分类
对于二分类问题,将类别1称为正例(Positive),类别2称为反例(Negative),分类器预测正确记作真(True),预测错误记作(False),由这4个基本术语相互组合,构成混淆矩阵的4个基础元素,为:
TP(True Positive):真正例,模型预测为正例,实际是正例(模型预测为类别1,实际是类别1)
FP(False Positive):假正例,模型预测为正例,实际是反例 (模型预测为类别1,实际是类别2)
FN(False Negative):假反例,模型预测为反例,实际是正例 (模型预测为类别2,实际是类别1)
TN(True Negative):真反例,模型预测为反例,实际是反例 (模型预测为类别2,实际是类别2)
混淆矩阵示意图(参考:西瓜书 p30):

根据混淆矩阵计算其他常见模型评价指标:
准确率(Accuracy),对应语义分割的像素准确率 PA
公式:Accuracy = (TP + TN) / (TP + TN + FP + FN)
意义:对角线计算。预测结果中正确的占总预测值的比例(对角线元素值的和 / 总元素值的和)
精准率(Precision),对应语义分割的类别像素准确率 CPA
公式:Precision = TP / (TP + FP) 或 TN / (TN + FN)
意义:竖着计算。预测结果中,某类别预测正确的概率
召回率(Recall),不对应语义分割常用指标
公式:Recall = TP / (TP + FN) 或 TN / (TN + FP)
意义:横着计算。真实值中,某类别被预测正确的概率
三分类模型分类结果的混淆矩阵示意图

准确率:Accuracy = (a + e + i) / (a + b + c + d + e +f + g + h + i)
类别1精准率:P1 = a / (a + d + g)
类别1召回率:R1 = a / (a + b + c)
混淆矩阵计算代码
# 计算混淆矩阵
def _fast_hist(label_true, label_pred, n_class):
mask = (label_true >= 0) & (label_true < n_class)
hist = np.bincount(
n_class * label_true[mask].astype(int) +
label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)
return hist
# 例如
label_true = np.array([[0,1,0],[2,1,0],[2,2,1]])
label_pred = np.array([[1,1,0],[2,1,1],[2,2,1]])
n_class = 3
confusionmatrix = _fast_hist(label_true, label_pred, n_class)在这个例子中,各个变量、中间变量的值如下所示:
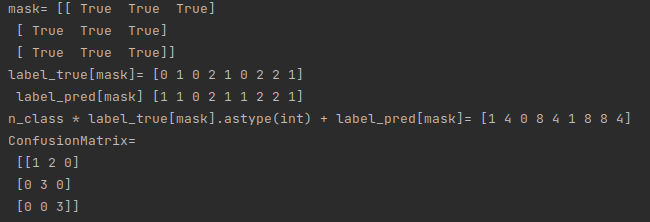
代码理解
对于核心代码 np.bincount(n_class * label_true[mask].astype(int) + label_pred[mask], minlength=n_class ** 2)的理解,此函数用于产生n*n的分类统计表

https://blog.csdn.net/weixin_43143670/article/details/104722381
mask = (label_true >= 0) & (label_true < n_class)
这一句是为了保证标记的正确性(标记的每个元素值在[0, n_class)内),标记正确得到的mask是一个全为true的数组。
label_true[mask]及label_pred[mask]把label_true、label_pred拉平为一维数组。
令a = label_true[mask],b = label_pred[mask],
c = n_class * label_true[mask] + label_pred[mask] = n_class * a + b,
当a=0,b=0时,c=0;当a=0,b=1时,c=1;……;当a=2,b=2时,c=8,得到以下对应表。
label_true[i]= | 0 | 0 | 0 | 1 | 1 | 1 | 2 | 2 | 2 |
label_pred[i]= | 0 | 1 | 2 | 0 | 1 | 2 | 0 | 1 | 2 |
c[i]= | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
因此可根据c的值推出a、b的值,以下面这个计算结果为例,

c[0]=1,可推知label_true[mask][0]=0,label_pred[mask][0]=1,即c=1,(label_true,label_pred)=(0,1)
c[1]=4,可推知label_true[mask][1]=1,label_pred[mask][1]=1,即c=4,(label_true,label_pred)=(1,1)
……
简而言之,n_class * label_true[mask] + label_pred[mask]的作用是建立一个由索引查询(label_true,label_pred)这个数对的字典。
d = np.bincount(c,minlength=n_class ** 2)的作用是统计c中每个元素出现的次数,比如0出现了1次,1出现了2次……,8出现了3次。d的维度默认是c中最大值+1,此处设为n_class ** 2。由c[i]的值可知标签图、预测图在位置i处的值,即真实值和预测值,通过np.bincount()统计c的每个元素(从0到(n_class ** 2 - 1))出现的次数,就意味着得到了每个(label_true,label_pred)对出现的次数,比如c=0出现了1次,可推知(0,0)对出现的次数就是1,c=8出现了3次,可推知(2,2)对出现的次数就是3,填入下表,就得到了混淆矩阵。
混淆矩阵 | 预测值 | |||
0 | 1 | 2 | ||
真实值 | 0 | 1 | 2 | 0 |
1 | 0 | 3 | 0 | |
2 | 0 | 0 | 3 | |














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









