







阅读本文只需要最基础的数据库知识。
但请相信我,仔细看完你一定会有收获。
设想一个场景,我们想要开发一个账号系统,初期我们设计了一个简单的数据库表结构:
CREATE TABLE `account`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
`password` varchar(45) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
我们将建表文件保存到项目里,命名为 account.sql。这样同事就能拿到建表文件创建表,在本地跑这个应用了。很快,新的需求来了,我们需要添加一个”年龄“字段,于是我们拿起建表文件做了如下修改:
CREATE TABLE `account`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
`password` varchar(45) NOT NULL,
`age` int NOT NULL DEFAULT 0, -- 新增“年龄”字段
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
兴奋的给同事分享我们的新成果,但在创建表时却遇到了问题:
Table ‘account’ already exists
报错信息翻译过来就是,表重复创建了,account 这张表在上次展示时已经在同事电脑上创建过,我们通过手动删除这张表再重新创建,很快地解决了这一问题。
这看起来是一个很小的问题,可当使用这个账号系统的同事变多时,这件事情变得越来越棘手——我们并不清楚谁已经创建过这张表。
实际开发过程中,QA、运维同事遇到最多的问题往往是这些小细节。
我们很快找到了一个好方案——在创建时,提前判断account表是否存在,存在则先删除后创建,修改如下:
DROP TABLE IF EXISTS `account`; -- 如果 account 表已经存在,则删除
CREATE TABLE `account`
(
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(45) NOT NULL,
`password` varchar(45) NOT NULL,
`age` int NOT NULL DEFAULT 0,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
开发阶段我们确实很好的解决了这个问题,随着需求的增加和系统的增加,我们项目里的建表文件保存成了如下的结构:
- model
- account
account.sql
- profile
profile.sql
trade.sql
……
手动一一创建表已经无法满足日益增加的建表文件规模,我们编写了自动化脚本来自动执行这些建表文件。
终于,我们的项目即将上线(另一个可能的时间节点是,内部需要部署一个长期测试的版本),这意味着我们必须更长时间的保留用户数据,即使表结构有调整也不能直接删表。
当然,你可以把这些麻烦事都推给运维,很多公司确实是这样做的。
开发:“xx表结构有变动,你去操作一下。”
运维:“新版本怎么一直报错?”
开发:“你没更新数据库吧?”
这种模式依赖于人与人的交流,运维人员必须清楚的知道,哪些表的结构有变动,不能有遗漏。当然,我们可以要求所有开发人员写清楚本迭代的表变动,例如:
ALTER TABLE `account` ADD `age` int; -- 对 account 表增加一个 age 字段
如果只有一套运维环境且保持单线开发,这可以解决问题。如果我们想要更进一步,项目的每个版本对应一个表结构,那当我们想部署指定版本的应用时,需要将数据库表推进到指定版本的表结构上,这时候该怎么做?
其实没有魔术:
- model
- account
1_base.sql
3_add_age.sql
4_add_nickname.sql
- profile
2_profile.sql
2_trade.sql
……
3_add_age.sql 中写入:
ALTER TABLE `account` ADD `age` int;
所有的建表和修改表的文件按照 {版本号}_描述命名即可。剩下的,就是编写一个命令行工具按照版本号顺序依次执行到最新版本即可。例如我们需要部署版本3的应用,只需要执行到版本3的sql文件即可,更高版本的文件例如 4_add_nickname.sql 跳过不执行。
至此,我们不用每次都删表了,也将修改表这个过程,完全交给自动化的工具执行,降低了人为因素导致的灾难性后果。
写到这其实可以结束了,但为了防止你看到这却毫无收获,我准备再分享一点——如何在生产环境更新版本需要修改数据库的同时,做到不停服维护更新?
(大家可以思考一下)
不管是脚本语言实现的热更还是滚动更新实现的热更,总会在某一时刻出现新旧两个代码版本同时在操作同一张数据库表的情况:

这时候会导致数据库操作执行失败。当然,你在程序侧做好异步重试和失败任务记录,是能完美解决这一问题的,但这门槛相对较高。
有一个简单的方式,那就是让表结构”只增不减“,即不管怎么修改表,每次只能增加新行,而不能修改旧列或删除旧列。
你可能会问,原先需要修改旧列的情况该怎么办?
简单来说就是让旧版本读旧列,新版本读新列。
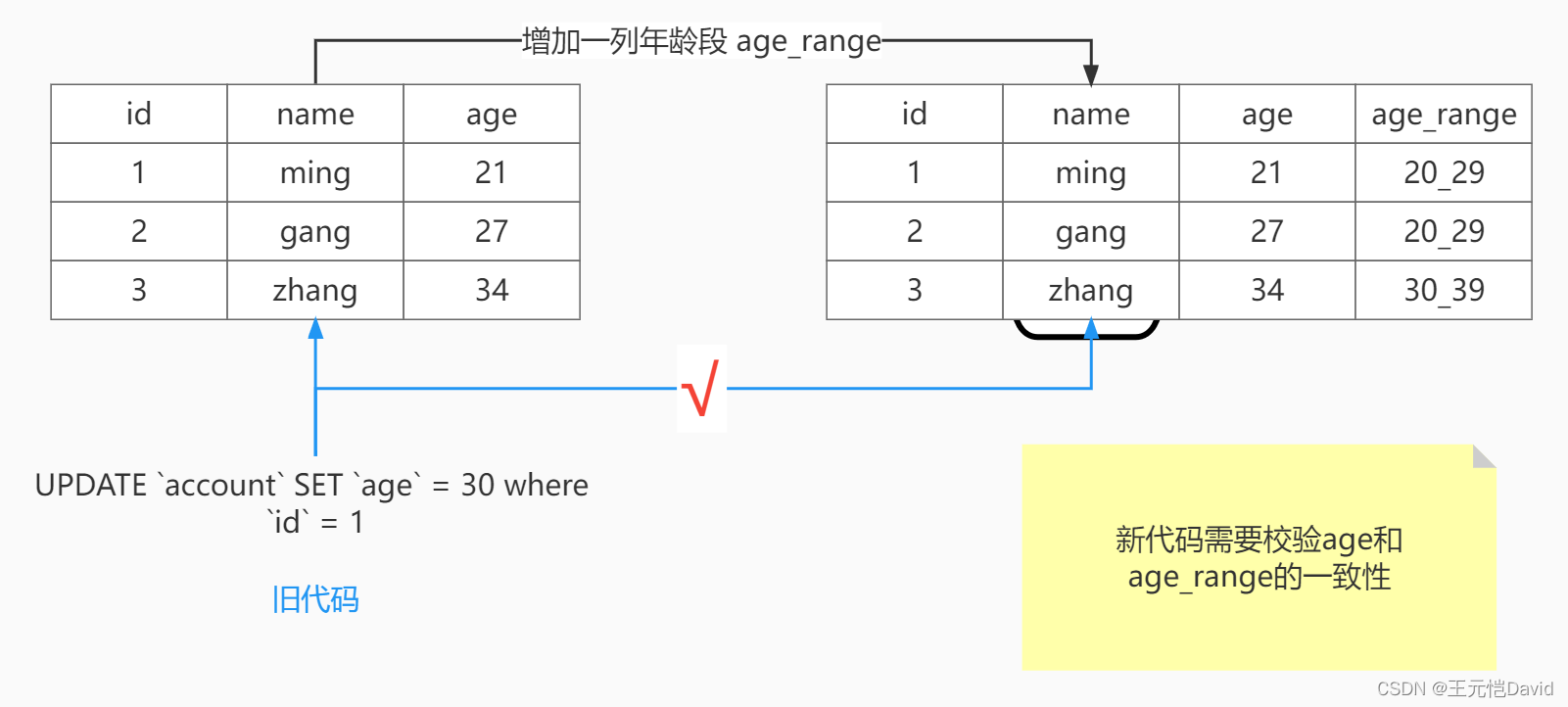
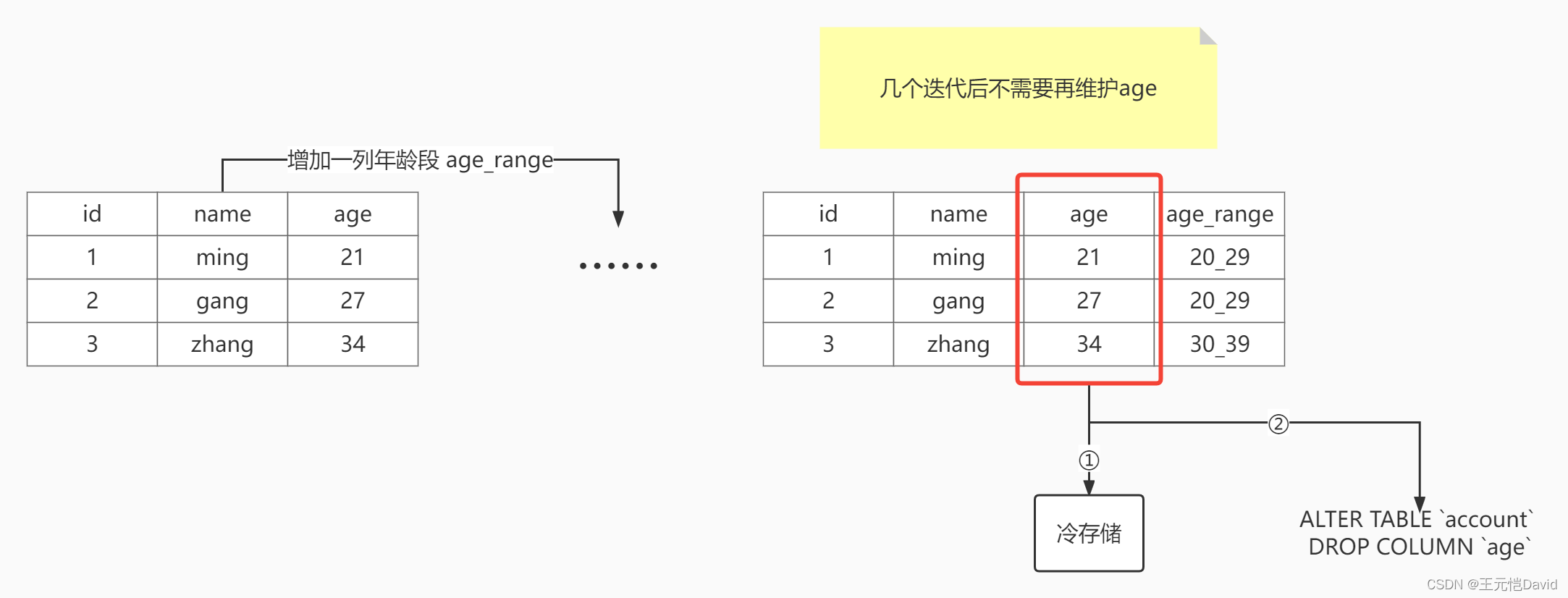
你可能会问,如果迭代速度足够快,表会无限增长无用的列怎么办?
当确认旧列已经完全废弃,即线上版本已经迭代过好几版,可以转存这些旧列的数据到更冷的存储中,例如磁盘备份。然后在用户低谷期执行ddl删除这一列。这种操作往往在阶段性运维时才需要执行,频率很低。
总结一下,本文分享了一些项目中使用关系型数据库的经验,希望能帮助到各位看官。这些经验指向一个高度统一的目标——通过自动化工具和项目规范,尽可能地降低人为操作导致的问题,降低开发运维门槛。
编写《游戏微服务架构实践》专栏是我长线的目标,尽量做到一周一篇。
在这之余,会穿插写一些日常工作生活中的思考或是总结,希望能获得更多的关注。
















 128
128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











