







1.基本知识
1.1 优化问题3个基本要素:优化变量、目标函数、约束条件
X=[x1,x2,…,xn]
min f(X)
s.t.
f(X) = hk(X)=0 ,k=1,2,…l
f(X) = gk(X)<=0 ,k=1,2,…m
引申:无约束优化、有约束优化、等式约束、不等式约束、线性优化、非线性优化。各类问题都有特定的解决办法
1.2 优化问题基本解决办法:解析解法、数值解法
- 解析解法:知道目标函数的具体形式,严格按照数学公式推导求解
- 数值解法:拟合思想。工具:泰勒展开(近似)、迭代求解(迭代)
- 优化准则法:
- 数学规划法:
实际应用中最广泛计算简单的当然是数值解法中的迭代法,也叫数学规划法。
1.3 迭代法的3个基本要素
- 初始值、迭代方向、步长
- 收敛性
- 终止条件:

1.4
函数在某一点的梯度方向变换最多上升最快、在负梯度方向下降最快、函数在某一点垂直于梯度方向的方向称为法线方向,将函数分为上升方向和下降方向
- 导数
- 偏导数
- 方向导数:方向导数是偏导数的推广、偏导数是方向导数的特例
- 梯度
1.5 多元函数求函数极小值的条件
- 必要条件:函数对Xm处的导数必须为0。----> 驻点
- 充分条件:G(Xm)或写H(Xm)正定。 各阶主子式均>0
驻点不一定是极值点,但极值点一定是驻点
2. 无约束优化问题
m
i
n
f
(
x
)
min f(x)
minf(x)
x
k
+
1
=
x
k
+
a
d
x_{k+1} = x_k + ad
xk+1=xk+ad
2.1 最速下降法
参考: 1.4 函数在某一点的梯度方向变换最多上升最快、在负梯度方向下降最快、函数在某一点垂直于梯度方向的方向称为法线方向,发现将函数分为上升方向和下降方向
Method1 : 最速下降法
1. 选一个初始值X0
2. 确定搜索方向= 负梯度方向
3. 确定最优步长,f(xk+1) =f(xk+ad) 其中只有a未知,利用求导求极值思想求解a
4. 是否满足停止条件
5. 否则反复2-5
key:
1)迭代方向为每一个点的负梯度方向
2)两次相邻的下降方向是相互垂直的,会导致搜索线路是Z型
在接近函数极小值附近搜索速度变慢
2.2 牛顿法
拟合思想:在
x
k
x_k
xk附近领域内用一个二次函数g(x),即泰勒展开保留到二阶来替代原来的目标函数f(x)。并且将g(x)的极小值作为目标函数f(x)的下一个迭代点。
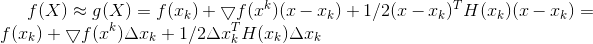
要求解g(x)的极小值点:参考1.5 多元函数求函数极小值的条件
通过必要条件求驻点:就是对g(x)求导,求出驻点:
Δ
x
=
−
H
−
1
▽
f
(
x
k
)
\Delta x = - H^{-1} \bigtriangledown f(x^k)
Δx=−H−1▽f(xk)
x
=
x
k
+
1
=
x
k
+
Δ
x
=
x
−
H
−
1
▽
f
(
x
k
)
x = x_{k+1} = x_k + \Delta x = x - H^{-1} \bigtriangledown f(x^k)
x=xk+1=xk+Δx=x−H−1▽f(xk)
再对比
x
k
+
1
=
x
k
+
a
d
x_{k+1} = x_k + ad
xk+1=xk+ad
所以牛顿法就是
搜索方向 d =
−
H
−
1
▽
f
(
x
k
)
- H^{-1} \bigtriangledown f(x^k)
−H−1▽f(xk)
搜索步长 a = 1
Method2 : 牛顿法
1. 选一个初始值X0
2. 计算gradent(J) 和 hession matrix(H)
3. 确定下一个迭代点 $\Delta x $ 以及 $ x_{k+1} = x_k + \Delta x$
本质:搜索方向 d = $- H^{-1} \bigtriangledown f(x^k)$搜索步长 a= 1
4. 是否满足停止条件
5. 否则反复2-5
Key:
1)迭代方向不一定沿梯度的负方向,没有朝着下降方向搜索的思想,所以对某些非二次项函数,有时候迭代结果会使得函数值上升
2) 计算量大,要计算gradent 和 hession matrix 以及 H的逆
3) H 有可能是奇异的,H矩阵不可逆
2.3 阻尼牛顿
Method3 : 阻尼牛顿法
1. 选一个初始值X0
2. 计算gradent 和 hession matrix
3. 确定搜索方向 $d = $- H^{-1} \bigtriangledown f(x^k)$
4. 搜索步长 a . 不再为1 ,而是利用函数极值条件求导求出最优步长
5. 是否满足停止条件
6. 否则反复2-5
7.
2.4 上面的都是间接方法,约束优化问题,还要好多其他方法,还有利用目标函数值来就求解的直接方法,
待补充
3. 最小二乘
非线性最小二乘问题来自于非线性回归,即通过观察自变量和因变量数据,求非线性目标函数的系数参数,使得函数模型与观测量尽量相似
3.1 我们面临问题举例
BA问题描述:已经相机的pose、3d点。通过针孔模型我们模型可以算出对应2d点位置,这叫预测。根据匹配我们得到实际的2d点位置,这叫观测。我们的目的是为了调整pose和3d位置,使得优化后的pose和3d点能更好的满足实际观测的情况,使得预测和观测之间的差距不至于太远。
3.2 最小二乘法的目标:求误差的最小平方和
X=[x1,x2,…,xn]
min F(X)
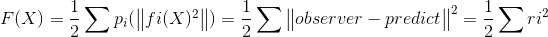
这里的
fi: object function,residual function
F: cost function
pi: loss function
3.3 最小二乘的基本解法和分类
- 线性:残差(residual)是线性的(ri是线性的)
- 非线性:残差(residual)是非线性的,ri是非线性的
线性的:直接套用公式

非线性的:利用[数值解法] [迭代求解]思想
- Line Search
- Trust Region

[Reference: ceres]
3.4 非线性最小二乘-线性搜索-line search
参考2中 无约束优化问题的求解方法。可以采用最速下降法、牛顿法、阻尼牛顿法。需要唯一需要注意的是这里的
F
(
x
)
F(x)
F(x)是一个 平方函数
F
(
x
)
=
f
i
(
x
)
2
=
r
i
(
x
)
2
F(x) = f_i(x)^2 = r_i(x)^2
F(x)=fi(x)2=ri(x)2
所以 涉及的梯度和H矩阵都是针对
f
i
(
x
)
2
f_i(x)^2
fi(x)2的
3.4.1 一阶泰勒展开 ——最速下降法
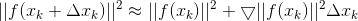
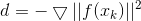
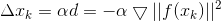
- 对 f ( x ) 2 f(x)^2 f(x)2 进行泰勒一阶展开,一阶导数也是针对 f ( x ) 2 f(x)^2 f(x)2对 Δ x \Delta x Δx 的一阶导数哦
- 确定下降方向为负梯度方向 d = − ▽ ∣ ∣ f ( x k ) ∣ ∣ 2 d = - \bigtriangledown ||f(x^k)||^2 d=−▽∣∣f(xk)∣∣2
- 确定合适的步长, min g ( x ) = \min g(x) = ming(x)=
3.4.2 二阶泰勒展开 ——牛顿法
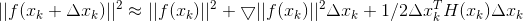
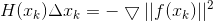
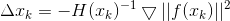
等价于Ax=b模型,线性方法的求解有很多方差,各种矩阵分解,如LU、cholesky分解等
缺陷还是计算量大
maybe H奇异不可逆 ????
3.4.3 区别 $ \bigtriangledown F(x)$ 与 ▽ ∣ ∣ f ( x ) ∣ ∣ 2 \bigtriangledown ||f(x)||^2 ▽∣∣f(x)∣∣2 与 ▽ r i ( x ) \bigtriangledown r_i(x) ▽ri(x)
是 ▽ F ( x ) \bigtriangledown F(x) ▽F(x) = ▽ ∣ ∣ f ( x ) ∣ ∣ 2 \bigtriangledown ||f(x)||^2 ▽∣∣f(x)∣∣2 = 2 ∑ r i ▽ r i ( x ) ! = ▽ r i ( x ) ∗ ▽ r i ( x ) 2 \sum r_i \bigtriangledown r_i(x) !=\bigtriangledown r_i(x) *\bigtriangledown r_i(x) 2∑ri▽ri(x)!=▽ri(x)∗▽ri(x)
梯度和海森矩阵具体求解,见笔记(笔记里的fi(x)其实表示F(x))
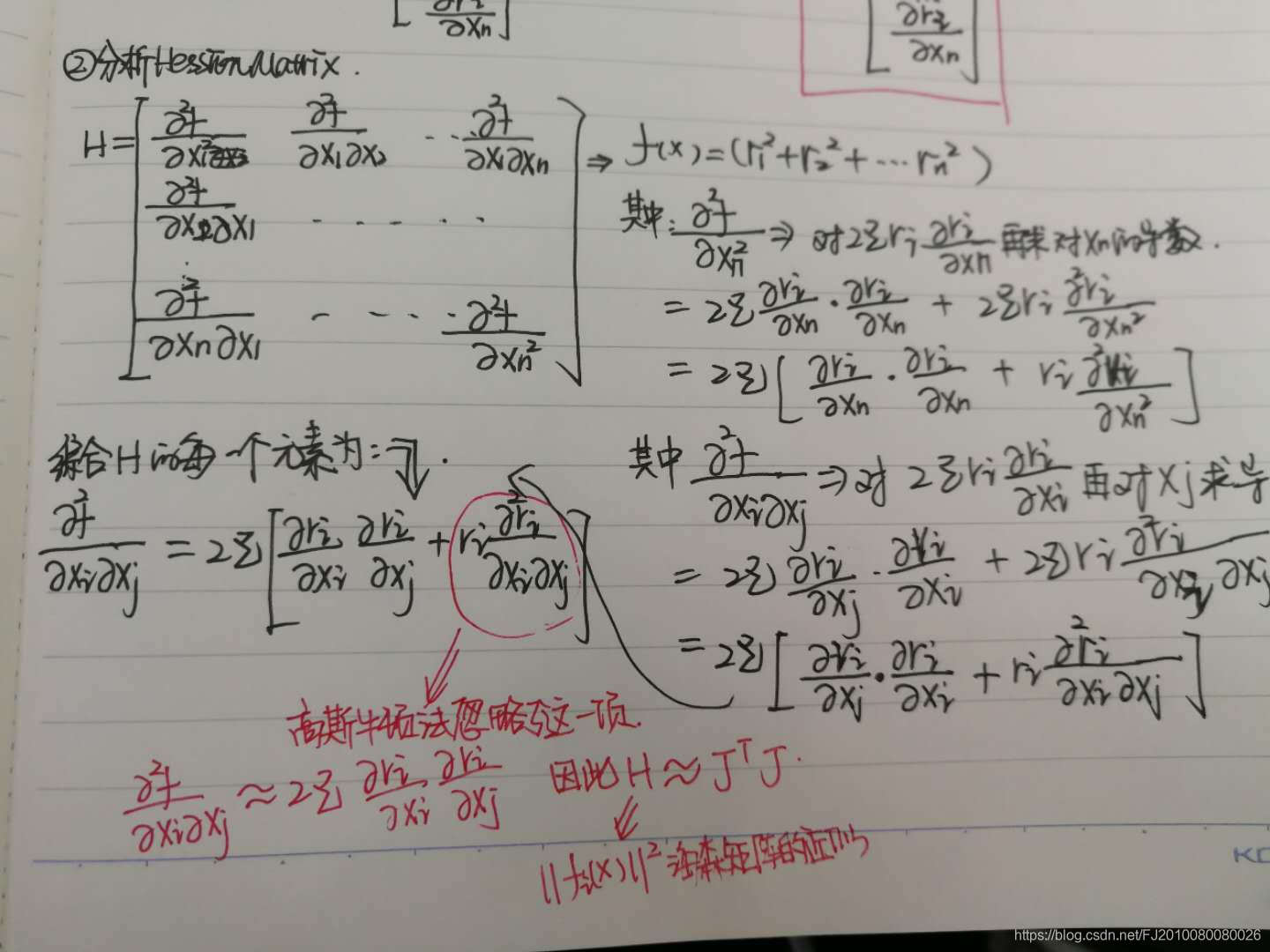
3.4.4 高斯牛顿法
高斯牛顿法解决非线性最小二乘问题的最基本方法,并且它只能处理二次函数。(使用时必须将目标函数转化为二次的)Unlike Newton’s method, the Gauss–Newton algorithm can only be used to minimize a sum of squared function values
理解方式1


注意:
(1)这里的J是ri(x)的偏导数构成的梯度
(2)这里的H = J^T J ,要求是正定的,才能保证得到的 delta x是极值
(3)然而J^T J 是一个半正定矩阵,实际情况中J^T J 会出现奇异和病态到时算法稳定性差不收敛情况
(4)还有一个问题是:如果求解出来的$\Delta x$太大,就与在xk处泰勒展开的局部近似思想矛盾,不够准确也会导致不收敛
**由此引申出信頼域方法**
理解方式2 :
参考上面笔记图2.这里的 H 是真实的ri(x)^2 的H矩阵的近似,忽略了真实H矩阵中的二阶项目,用一阶代替(用J(x)^T J(x)代替H的求法,从而节省了牛顿法的计算量).但是这里必须满足条件: 二阶可忽略的. 二阶可忽略的前提是:ri比较小,或者 ri接近linear 这样一阶微分是常数
3.5 非线性最小二乘-信頼域方法-trust region
3.5.1 LM方法
- 设置信頼域空间迭代搜索空间
- 再采用拉格朗日乘子将该有约束优化问题- >为无约束优化问题
- 转换后,即:添加一个 λ \lambda λ保证 H矩阵正定
- 计算比例因子 ρ \rho ρ,控制 λ \lambda λ的大小,从而控制迭代搜索的精度
大概思路如下:但实际使用并不是这样,做了一些改进策略

个人的理解:
- 因为迭代法的主要思想是沿着函数下降方向走,但是高斯牛顿法求解的 不一定能保证函数值下降,预期下降值与实际下降值不相符,就需要改变方法或者不取那个迭代点。
- 信頼域方法就是先限定一个范围让只能在这个区域内,就相当于加了一个约束条件,这个范围应该一开始比较小,因为是近似展开。
问题1 : 梳理基本公式
1.残差函数一阶泰勒展开:
f
(
x
+
Δ
x
)
=
l
(
Δ
x
)
=
f
(
x
)
+
J
Δ
x
f(x+\Delta x) = l(\Delta x) = f(x) + J \Delta x
f(x+Δx)=l(Δx)=f(x)+JΔx
2.误差函数展开:
1
/
2
∗
F
(
x
)
=
1
/
2
∗
∣
∣
f
(
x
)
∣
∣
2
=
L
(
Δ
x
)
=
1
/
2
∗
l
(
Δ
x
)
T
l
(
Δ
x
)
1/2 * F(x) =1/2 * ||f(x)||^2 = L(\Delta x) = 1/2 * l(\Delta x)^T l(\Delta x)
1/2∗F(x)=1/2∗∣∣f(x)∣∣2=L(Δx)=1/2∗l(Δx)Tl(Δx)
=
1
/
2
∗
(
f
(
x
)
+
J
Δ
x
)
T
∗
(
f
(
x
)
+
J
Δ
x
)
=1/2 * (f(x) + J \Delta x)^T * (f(x) + J \Delta x)
=1/2∗(f(x)+JΔx)T∗(f(x)+JΔx)
=
1
/
2
f
(
x
)
T
f
(
x
)
+
(
Δ
x
)
T
J
T
f
(
x
)
+
1
/
2
∗
(
Δ
x
)
T
J
T
J
(
Δ
x
)
=1/2 f(x)^Tf(x) + (\Delta x)^T J^Tf(x)+1/2 * (\Delta x)^T J^T J (\Delta x)
=1/2f(x)Tf(x)+(Δx)TJTf(x)+1/2∗(Δx)TJTJ(Δx)
3. 通常设:
F
(
x
)
′
=
J
T
f
(
x
)
F(x)^{'} = J^Tf(x)
F(x)′=JTf(x)
F
(
x
)
′
′
=
J
T
J
F(x)^{''} = J^T J
F(x)′′=JTJ
或则
b
=
J
T
f
(
x
)
=
J
T
f
b = J^Tf(x) = J^T f
b=JTf(x)=JTf
H
=
J
T
J
H = J^T J
H=JTJ
-
F ( x + Δ x ) = 1 / 2 f ( x ) T f ( x ) + ( Δ x ) T b + 1 / 2 ∗ ( Δ x ) T H ( Δ x ) F(x+\Delta x)=1/2 f(x)^Tf(x) + (\Delta x)^T b+1/2 * (\Delta x)^T H (\Delta x) F(x+Δx)=1/2f(x)Tf(x)+(Δx)Tb+1/2∗(Δx)TH(Δx)
为了求 Δ x \Delta x Δx对上式求导,
b + H Δ x = 0 b + H \Delta x =0 b+HΔx=0
H Δ x = − b H \Delta x = -b HΔx=−b
J T J Δ x = − J T f J^TJ \Delta x = -J^Tf JTJΔx=−JTf -
J T J J^TJ JTJ 不正定,加入 λ \lambda λ 有些地方写成 μ \mu μ
( J T J + λ I ) Δ x = − J T f (J^TJ + \lambda I )\Delta x = -J^Tf (JTJ+λI)Δx=−JTf
或者
( J T J + μ I ) Δ x = − J T f (J^TJ + \mu I )\Delta x = -J^Tf (JTJ+μI)Δx=−JTf normal equaltion
问题2: Δ x \Delta x Δx怎么求解
针对normal equaltion,
(
J
T
J
+
μ
I
)
Δ
x
=
−
J
T
f
(J^TJ + \mu I )\Delta x = -J^Tf
(JTJ+μI)Δx=−JTf
最常用矩阵分解来求解:
设 J^TJ 分解后的特征值是一系列的
λ
i
\lambda_i
λi对应的特征向量是
v
j
v_j
vj,则:
Δ
x
l
m
=
−
∑
j
=
1
n
v
j
T
F
′
T
λ
j
+
μ
\Delta x_{lm} = - \sum_{j=1}^{n} \frac{v_j^T F^{'T}}{\lambda_j + \mu}
Δxlm=−∑j=1nλj+μvjTF′T
问题3: λ \lambda λ初始怎么设置
分析 Δ x l m = − ∑ j = 1 n v j T F ′ T λ j + μ \Delta x_{lm} = - \sum_{j=1}^{n} \frac{v_j^T F^{'T}}{\lambda_j + \mu} Δxlm=−∑j=1nλj+μvjTF′T
- μ \mu μ在分母位置,最好与最大特征值是同一个数量级
- 参考一些别的说法:即矩阵最大特征值的数量级 与 矩阵主对角线元素最大值 是同一数量级,或者相似 ,或者差不多 。 来自韦达定理的一个简化???
- 对于式子: ( J T J + μ I ) Δ x = − J T f (J^TJ + \mu I )\Delta x = -J^Tf (JTJ+μI)Δx=−JTf , 当u较大时,算法近似为一阶梯度的最速下降法; 当u较小时,算法近似高斯牛顿法
所以有:
μ
0
=
τ
∗
m
a
x
(
J
T
J
i
i
)
\mu_0 = \tau * max( J^TJ_{ii})
μ0=τ∗max(JTJii)
τ \tau τ取值 [ 1 0 − 8 , 1 ] [10^{-8},1] [10−8,1]之间,用来控制初始值 μ 0 \mu_0 μ0的大小
- 如果初始值 x 0 x_0 x0与真实值 x ∗ x^* x∗差异较小,可以用二阶近似展开,即,希望算法偏向于高斯牛顿法,因此 μ \mu μ可以取小一点,即 τ \tau τ 可以取 1 0 − 8 10^{-8} 10−8 附近。
- 如果初始值 x 0 x_0 x0与真实值 x ∗ x^* x∗差异较大,二阶近似不准确,即,希望算法偏向于一阶梯度下降法,因此 μ \mu μ可以取大一点,即 τ \tau τ 可以取 1附近。
问题4: λ \lambda λ怎么更新
理论
计算一个比例因子
ρ
=
实
际
下
降
值
/
理
论
下
降
值
\rho = 实际下降值/ 理论下降值
ρ=实际下降值/理论下降值
实际下降的值:
F
(
x
+
Δ
x
)
−
F
(
x
)
=
∣
∣
f
(
x
+
Δ
x
)
∣
∣
2
−
∣
∣
f
(
x
)
∣
∣
2
F(x+\Delta x) - F(x) = ||f(x+\Delta x)||^2 -||f(x)||^2
F(x+Δx)−F(x)=∣∣f(x+Δx)∣∣2−∣∣f(x)∣∣2
近似理论下降的值:
L
(
Δ
x
)
−
L
(
0
)
L(\Delta x) - L(0)
L(Δx)−L(0)
怎么得到下面这一步,还没推出来????
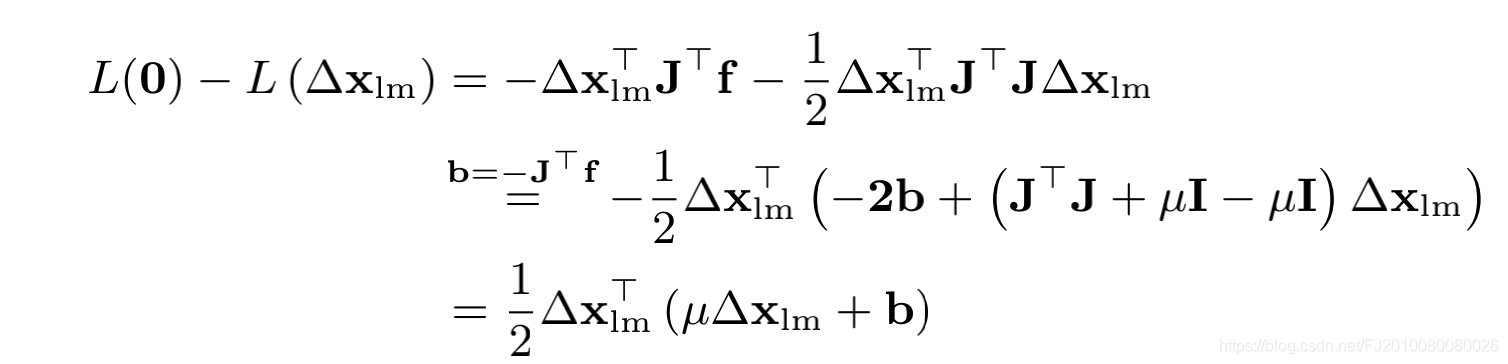
原始

改进
Marquardt 做了统计实验,发现
μ
\mu
μ会有震荡现象,因此用类似曲线拟合的方式对
μ
\mu
μ 的取值进行如下改进
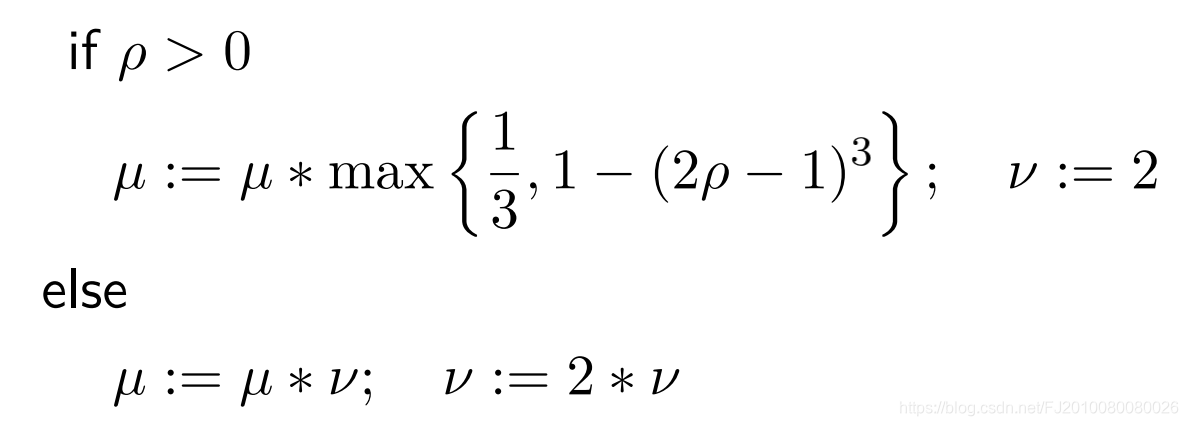
g2o里的实现 就是这种方式 参考《SBA论文》

问题5: 核函数的影响

方程16的推导没有看懂????

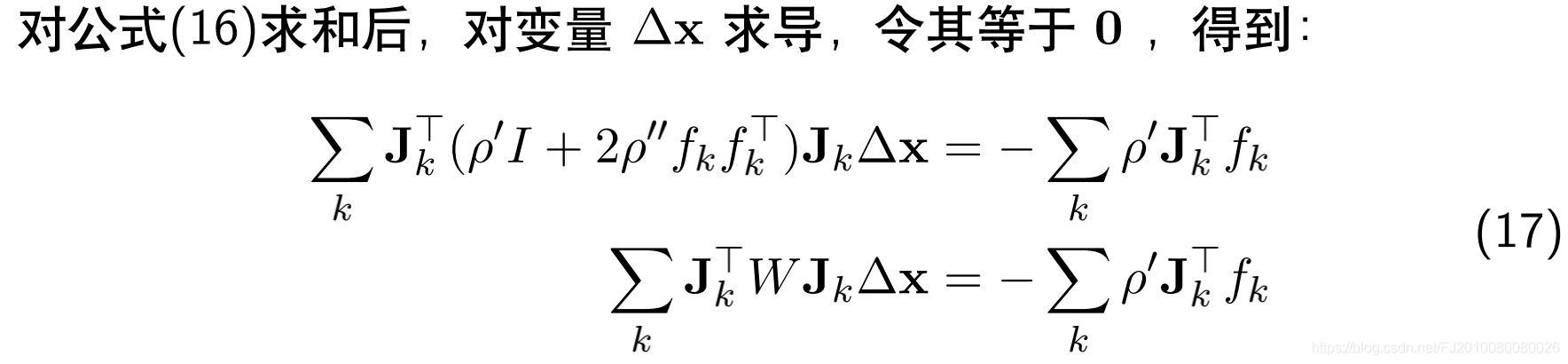


3.5.2 DogLeg
TODO
-
个人理解1:通过拉格朗日法将一个不等式约束问题转换为无约束优化问题,然后再用KKT条件可以知道信頼域范围与最优解之间的关系。就是说当最优解本来就在信頼域范围内,其实信頼域对最优解不起约束,那么最优解=就是求得的高斯牛顿的解。而当最优解在信頼域外部最优解被信頼域范围约束,在信頼域边缘上找到一个近似的最优解。
-
个人理解2:与LM相比Dogleg的关键优势在于:如果选择的信頼域大小会导致函数值实际下降量少,就是说近似的不准确,那么LM会重新减小信頼域,重新计算. 但是Dogleg 利用最速下降和高斯牛顿思想,保证得到的近似点在信頼域范围上,只需要计算高斯牛顿和柯西矢量之间的值.
参考:https://blog.csdn.net/stihy/article/details/52737723


推荐一个博客:
1)traditional-dogleg:思想是利用了最速下降和高斯牛顿的结合
https://blog.csdn.net/fangqingan_java/article/details/46956643
还有其他dog-leg的扩展方法,此处不再讲
https://blog.csdn.net/lucylove3943/article/details/41588491
https://blog.csdn.net/hlx371240/article/details/39676003
- 若高斯牛顿的结果在信頼域内,说明信頼域的约束不起作用
- 若高斯牛顿结果再信頼域外,计算最速下降法,结果再信頼域外,说明沿着负梯度方向下降最多,直接取信頼域边缘上的点即可
- 若高斯牛顿结果再信頼域外,计算最速下降法,结果再信頼域内,说明沿着负梯度方向下降多,而结果又在信頼域内部,我们可以让其更向着高斯牛顿方向再下降一点点,这样子可以加快收敛,于是最优的结果在两个结果的连线上。














 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









