







 超级会员免费看
超级会员免费看
目录
**(4) 级联分类器(Cascade Classifier)**
链接:https://pan.baidu.com/s/1VhGdyIW5GWuTNkfbCEc5eA?pwd=z0eo
提取码:z0eo
--来自百度网盘超级会员V2的分享
创建环境
conda create -n 环境名称
python=3.8 conda activate 环境名称然后配置环境
pip install requirements.txt运行程序,点击你想运行的ipynb,选择对应的内核
人脸检测速成
haar检测人脸
运行face_detection\1.haar.ipynb
Haar特征人脸检测是一种基于机器学习的传统目标检测方法,由Viola和Jones在2001年提出。它通过计算图像中的Haar-like特征(类似边缘、线、矩形区域的亮度差异),结合AdaBoost分类器和级联分类器(Cascade Classifier),实现高效的人脸检测。
1. Haar特征人脸检测的核心原理
**(1) Haar-like特征**
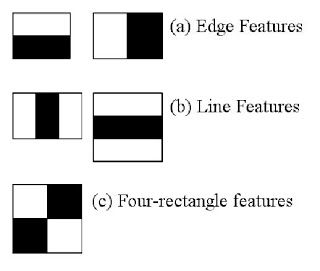
Haar特征是通过计算图像中矩形区域的像素和差异来描述的,例如:
-
边缘特征(Edge Features):检测垂直或水平边缘。
-
线特征(Line Features):检测线条结构。
-
中心环绕特征(Center-Surround Features):检测中心与周围区域的对比度。
示例:
[ 白色区域像素和 ] - [ 黑色区域像素和 ] = 特征值
https://docs.opencv.org/4.x/haar_features.jpg
**(2) 积分图(Integral Image)**
为了快速计算矩形区域的像素和,使用积分图(Integral Image)进行优化,使得特征计算复杂度从O(N²)降到O(1)。
**(3) AdaBoost分类器**
-
从大量Haar特征中,AdaBoost算法选择最具区分度的特征,构建一个强分类器。
-
每个弱分类器对应一个Haar特征,最终组合成一个强分类器。
**(4) 级联分类器(Cascade Classifier)**
-
采用多级分类器,每一级过滤掉大量非人脸区域,减少计算量。
-
只有通过所有级联分类器的区域,才被判定为人脸。
2. Haar人脸检测流程
步骤1:准备训练数据
-
正样本(人脸图片):包含人脸的图片,标注人脸位置。
-
负样本(非人脸图片):不包含人脸的背景图片。
步骤2:训练分类器
-
计算Haar特征:对每张图片计算所有可能的Haar特征。
-
AdaBoost训练:选择最佳特征,构建强分类器。
-
级联分类器训练:组合多个强分类器,形成级联检测模型。
步骤3:检测人脸(OpenCV实现)
python
import cv2
# 加载预训练的Haar级联分类器(OpenCV自带)
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
# 读取图像并转为灰度图(Haar检测需要单通道)
img = cv2.imread("test.jpg")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测人脸
faces = face_cascade.detectMultiScale(
gray,
scaleFactor=1.1, # 缩放因子(调整检测窗口大小)
minNeighbors=5, # 最小邻居数(过滤误检)
minSize=(30, 30) # 最小检测窗口
)
# 绘制检测框
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 显示结果
cv2.imshow("Face Detection", img)
cv2.waitKey(0)
cv2.destroyAllWindows()步骤4:优化检测
detections = face_detector.detectMultiScale(img_gray,scaleFactor=1.3)
-
调整参数:
-
scaleFactor(默认1.1):控制检测窗口的缩放步长,越小越慢但更精确。 -
minNeighbors(默认3~6):越高误检越少,但可能漏检。 -
minSize/maxSize:限制检测的最小/最大人脸尺寸。
-
-
多尺度检测:适应不同大小的人脸。
1. scaleFactor:
作用:此参数用于控制图像的缩放比例。它告诉检测器在多大程度上缩放图像,以便检测不同尺寸的对象。
默认值:通常默认值为1.1(即每次图像尺寸增加10%)。
影响: 如果scaleFactor设置为大于1的值(如1.3),它会在每次缩放时减少图像的尺寸,从而提高检测速度,但可能会丢失较小物体的检测结果。 如果scaleFactor设置为较小的值(如1.05),则会更仔细地检查图像的每个细节,从而增加检测的准确性,但也会导致更长的计算时间。 对于scaleFactor=1.3,它意味着每次图像的尺寸减少30%,让检测器能够处理不同大小的物体,同时提高效率。选择此值通常在效率和准确性之间提供了一个良好的平衡。
2. minNeighbors:
作用:此参数用于控制检测结果的严格性,定义了每个检测区域周围需要多少个邻近的矩形框来保留该区域为有效检测。
影响: 增加minNeighbors值会导致检测更加严格,只有在该区域有更多的邻近矩形框时才会认为这是一个有效的检测区域,减少误报,但也可能错过一些真实的人脸。 减少minNeighbors值则会放宽条件,允许更多的区域被标记为有效检测,可能会增加误报。
3. minSize 和 maxSize:
作用:这两个参数用于定义检测器应该关注的最小和最大对象尺寸(例如人脸的尺寸)。 影响: minSize:设置人脸检测器可以检测到的最小物体尺寸。如果物体小于该尺寸,则不会被检测到。它有助于过滤掉那些非常小的目标(如背景噪声)。
maxSize:设置最大物体尺寸。如果物体大于该尺寸,则不会被检测到。这有助于防止过大的物体被错误检测为目标(例如,检测到过大的脸或背景中的大型物体)。
4. img_gray(输入图像): 作为detectMultiScale()方法的输入,必须提供一张灰度图像,通常是通过cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)将原始彩色图像转换为灰度图像。这是因为人脸检测通常在灰度图像上进行,速度更快且计算资源需求较低。
3. Haar检测的优缺点
✅ 优点
-
计算速度快(积分图优化)。
-
适合实时检测(如摄像头人脸检测)。
-
OpenCV内置预训练模型,开箱即用。
❌ 缺点
-
对光照、遮挡敏感。
-
只能检测正脸,侧脸效果较差。
-
不如深度学习(如MTCNN、YOLO)准确。
4. 改进方案
-
结合HOG+SVM(如Dlib人脸检测)。
-
使用深度学习模型(如MTCNN、RetinaFace、YOLO)。
-
Haar+CNN混合检测(提高精度)。


HOG检测人脸
代码位置:face_detection\2.hog.ipynb
如果缺失dlib
https://blog.csdn.net/qq_58691861/article/details/119116148
这里直接通过百度网盘提供的
dlib-19.19.0-cp38-cp38-win_amd64.whl进行下载
HOG(Histogram of Oriented Gradients)是一种基于图像局部梯度方向分布的特征描述方法,广泛应用于行人检测、人脸识别等计算机视觉任务。其核心思想是通过统计图像局部区域的梯度方向分布来表征目标特征,对光照变化和几何形变具有较好的鲁棒性。
HOG人脸检测流程
1.图像预处理
-
灰度化:将彩色图像转为灰度图,减少计算量并聚焦于纹理信息。
- Gamma校正:调整图像对比度,降低光照不均的影响。公式为
![]()
,通常取 γ=0.5。
2.梯度计算
-
使用Sobel算子等微分工具计算每个像素的水平梯度(gx)和垂直梯度(gy):
![]()
-
计算梯度幅值和方向:

-
方向范围约束为0-180度,以消除梯度符号影响。
3.’分块与直方图统计
- Cell划分:将图像划分为8×8像素的单元(Cell),每个Cell内统计梯度方向直方图。将方向分为9个区间(BIN),每个BIN覆盖20度范围,按梯度幅值加权投影。
- Block整合:将相邻的2×2个Cell组成16×16像素的块(Block),对块内所有Cell的直方图进行L2归一化,消除局部对比度差异。
4.特征向量生成
-
滑动窗口遍历图像,将每个Block的特征向量串联,形成整幅图像的HOG描述子。例如,64×128像素的窗口可生成3780维特征向量(7×15个Block × 36维/Block)。
5.分类与检测
-
训练分类器:常用支持向量机(SVM)或深度神经网络(DNN)对正负样本(人脸/非人脸)的HOG特征进行分类训练。
-
滑动窗口检测:在输入图像中多尺度滑动窗口,提取HOG特征并输入分类器判断是否包含人脸。通过非极大值抑制(NMS)消除重叠框。
HOG的优势与局限性
| 优点 | 局限性 |
| 对光照、阴影鲁棒性强 | 计算复杂度较高,实时性受限 |
| 能捕捉局部结构特征(如五官轮廓) | 对遮挡或极端角度人脸检测效果下降 |
| 无需依赖肤色或颜色信息 | 需手动调整参数(如Cell/Block大小) |
应用场景
-
实时人脸检测:结合轻量级HOG模型(如Dlib库)实现快速检测。
-
疲劳驾驶监测:通过HOG定位人脸后,结合眼部、嘴部特征和头部姿态分析疲劳状态。
-
安防与身份识别:用于门禁系统、视频监控中的人脸检测与跟踪。
与其他方法的对比
-
Haar级联:HOG在复杂背景下的准确率更高,但Haar级联速度更快。
-
深度学习(如CNN):HOG计算量较小,适合资源受限场景;深度学习在精度和泛化性上更优,但依赖大量数据和算力。
代码示例(Python + OpenCV)
python
import cv2
# 加载HOG+SVM预训练模型
hog = cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
# 检测人脸
image = cv2.imread("input.jpg")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces, _ = hog.detectMultiScale(gray, winStride=(4,4), padding=(8,8), scale=1.05)
# 绘制结果
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.imshow("HOG Face Detection", image)
cv2.waitKey(0)CNN检测人脸
代码位置:face_detection\3.CNN.ipynb
1、介绍
CNN(Convolutional Neural Network,卷积神经网络)是一种深度学习模型,广泛应用于计算机视觉任务,包括人脸检测、识别和分类。相比于传统方法(如Haar、HOG),CNN能够自动学习图像的多层次特征(如边缘、纹理、形状等),具有更高的检测精度和鲁棒性。
CNN人脸检测的优势:
-
高精度:能够检测不同角度、光照、遮挡的人脸。
-
端到端训练:无需手动设计特征提取器(如Haar、HOG)。
-
适应性强:适用于复杂背景、多人脸场景。
-
可扩展性:可结合目标检测框架(如Faster R-CNN、YOLO、SSD)实现实时检测。
2. CNN人脸检测流程
(1)数据准备
-
正样本(人脸):标注人脸位置(bounding box)。
-
负样本(非人脸):背景图片或误检区域。
-
数据增强:旋转、缩放、翻转、亮度调整等,提高泛化能力。
(2)网络架构
CNN人脸检测通常采用以下结构:
-
输入层:输入图像(如224×224×3)。
-
卷积层(Conv):提取局部特征(如边缘、纹理)。
-
池化层(Pooling):降维,减少计算量(如Max Pooling)。
-
全连接层(FC):分类或回归人脸位置。
-
输出层:
-
分类任务:判断是否为人脸(Softmax)。
-
回归任务:预测人脸边界框(Bounding Box)。
-
常见CNN结构:
-
LeNet-5(早期CNN,适用于简单人脸检测)
-
AlexNet(更深的网络,提高检测精度)
-
VGG-16/VGG-19(小卷积核,深层网络)
-
ResNet(残差连接,解决梯度消失问题)
(3)训练CNN
-
损失函数:
-
分类损失:交叉熵损失(Cross-Entropy Loss)。
-
回归损失:Smooth L1 Loss(用于Bounding Box回归)。
-
-
优化器:Adam、SGD(随机梯度下降)。
-
训练技巧:
-
Dropout:防止过拟合。
-
Batch Normalization:加速训练,提高稳定性。
-
(4)检测阶段
-
滑动窗口(Sliding Window):
-
在图像上滑动不同大小的窗口,用CNN判断是否包含人脸。
-
缺点:计算量大,效率低。
-
-
基于区域提议(Region Proposal):
-
Faster R-CNN:使用RPN(Region Proposal Network)生成候选框。
-
YOLO(You Only Look Once):单次检测,速度快。
-
SSD(Single Shot MultiBox Detector):多尺度检测,平衡速度与精度。
-
import cv2
import numpy as np
import matplotlib.pyplot as plt
import dlib
# 设置Matplotlib显示参数
plt.rcParams['figure.dpi'] = 200 # 提高图像显示分辨率
# 读取输入图像
img = cv2.imread('./images/faces2.jpg')
# 初始化Dlib的CNN人脸检测器
cnn_face_detector = dlib.cnn_face_detection_model_v1('./weights/mmod_human_face_detector.dat')
# 执行人脸检测
detections = cnn_face_detector(img, 1)
# 遍历检测结果并绘制边界框
for face in detections:
# 获取人脸边界框坐标
x = face.rect.left()
y = face.rect.top()
r = face.rect.right()
b = face.rect.bottom()
# 获取检测置信度
c = face.confidence
print(f"Detection Confidence: {c:.4f}") # 打印置信度(保留4位小数)
# 在图像上绘制绿色矩形框(线宽为5像素)
cv2.rectangle(img, (x, y), (r, b), (0, 255, 0), 5)
# 将BGR图像转为RGB格式并显示
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.axis('off') # 关闭坐标轴
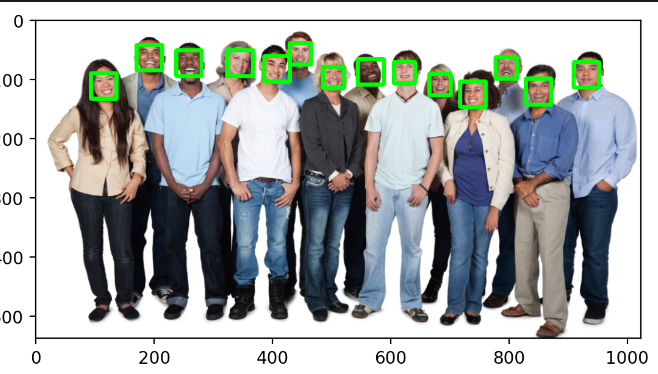
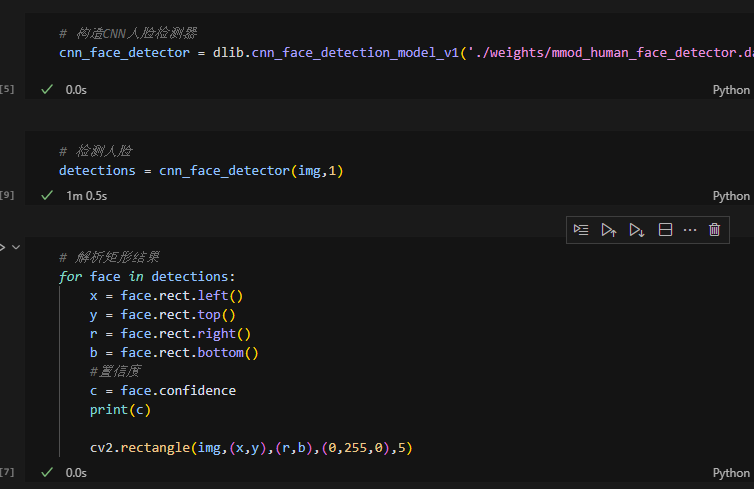
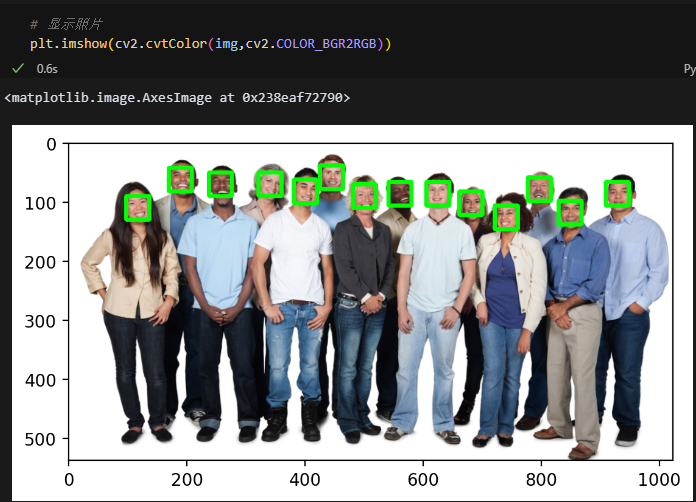
plt.show()分步解析
1. 导入依赖库
import cv2 # OpenCV,用于图像处理和绘制矩形框
import numpy as np # 数值计算(本代码中未直接使用,但通常与OpenCV配合)
import matplotlib.pyplot as plt # 图像显示
import dlib # 加载Dlib的深度学习人脸检测器2. 设置Matplotlib参数
plt.rcParams['figure.dpi'] = 200-
作用:提高Matplotlib显示图像的分辨率,使输出更清晰。
3. 读取输入图像
img = cv2.imread('./images/faces2.jpg')-
作用:通过OpenCV读取图像文件,返回一个
BGR格式的NumPy数组。
4. 初始化Dlib CNN检测器
cnn_face_detector = dlib.cnn_face_detection_model_v1('./weights/mmod_human_face_detector.dat')-
作用:
-
加载Dlib预训练的CNN人脸检测模型(
mmod_human_face_detector.dat)。 -
该模型基于Max-Margin Object Detection (MMOD)算法,对遮挡和多角度人脸有较好效果。
-
5. 执行人脸检测
detections = cnn_face_detector(img, 1)-
参数说明:
-
img:输入图像(BGR格式)。 -
1:表示对图像进行上采样(upscale)1次,提高对小脸的检测率。
-
-
返回值:
-
detections:包含检测结果的列表,每个元素是一个mmod_rectang对象,包含边界框坐标和置信度。
-
6. 解析检测结果并绘制框
for face in detections:
x = face.rect.left() # 左边界x坐标
y = face.rect.top() # 上边界y坐标
r = face.rect.right() # 右边界x坐标
b = face.rect.bottom() # 下边界y坐标
c = face.confidence # 检测置信度(0~1)
print(f"Detection Confidence: {c:.4f}") # 打印置信度
cv2.rectangle(img, (x, y), (r, b), (0, 255, 0), 5) # 绘制绿色矩形框-
作用:
-
遍历每个检测到的人脸,提取其边界框坐标和置信度。
-
用OpenCV的
rectangle函数在图像上绘制绿色矩形框(线宽5像素)。
-
7. 显示结果
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # BGR转RGB
plt.axis('off') # 隐藏坐标轴
plt.show() # 显示图像-
关键点:
-
OpenCV默认使用
BGR格式,而Matplotlib使用RGB格式,需通过cv2.cvtColor转换。 -
axis('off')隐藏坐标轴,使显示更简洁。
-
补充说明
-
模型性能:
-
Dlib的CNN检测器精度高,但速度较慢(适合离线或GPU环境)。
-
若需实时检测,可改用Dlib的HOG检测器(
dlib.get_frontal_face_detector())。
-
-
置信度阈值:
-
可通过
if c > 0.5:过滤低置信度检测结果(示例未体现,但实际应用建议添加)。
-
-
输出优化:
-
可添加标题
plt.title('Face Detection Results')。 -
保存结果:
cv2.imwrite('output.jpg', img)。
-
代码执行流程总结
-
输入:图像文件 → 加载为NumPy数组。
-
检测:CNN模型生成人脸边界框和置信度。
-
输出:在原图上绘制检测框,并显示高分辨率结果。
SSD检测人脸
代码在:face_detection\4.SSD.ipynb
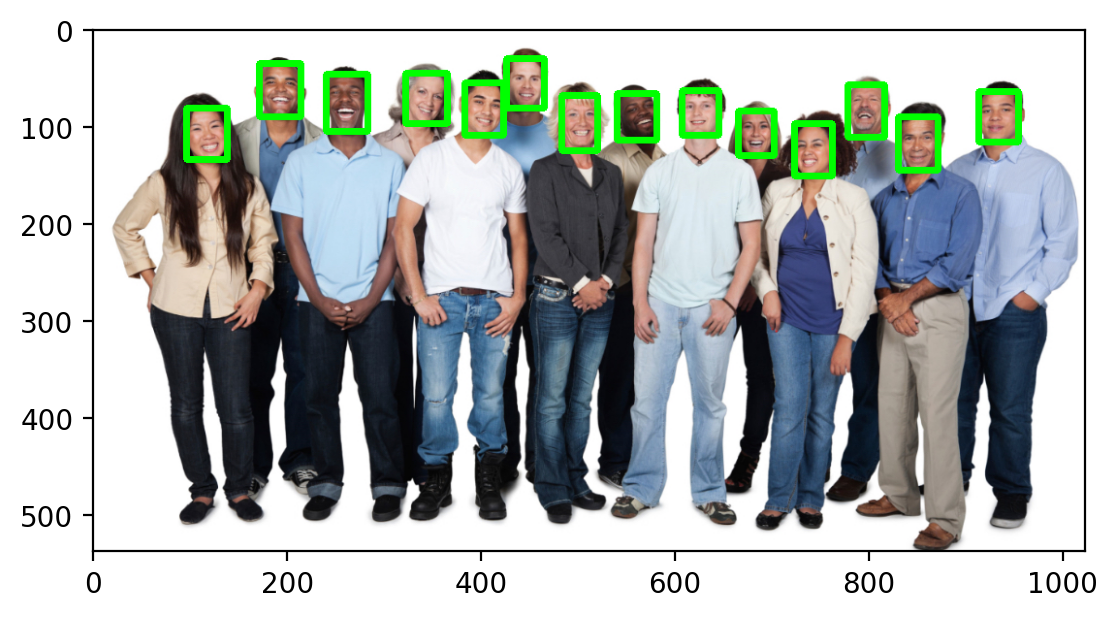
1.SSD简介
SSD(Single Shot MultiBox Detector)是一种单阶段目标检测算法,由Wei Liu等人在2016年提出。其核心特点是:
-
单次检测(Single Shot):直接在网络中预测目标类别和位置,无需区域提议(如Faster R-CNN)。
-
多尺度特征图(MultiBox):利用不同层级的卷积特征图检测不同大小的目标,适应多尺度人脸。
-
高效实时:比两阶段方法(如Faster R-CNN)更快,适合实时应用。
SSD的优势:
-
速度快:可达到实时检测(如30+ FPS)。
-
精度高:尤其对小目标(如远距离人脸)检测效果优于YOLO早期版本。
-
端到端训练:直接输出检测框和类别,无需后处理复杂步骤。
2. SSD人脸检测流程
(1)网络架构
SSD基于VGG16(或其他Backbone)改进,主要结构如下:
-
Backbone网络:提取基础特征(如VGG16的前几层)。
-
多尺度特征图:在Backbone后添加多个卷积层,生成不同尺度的特征图(如38×38、19×19、10×10等)。
-
Default Boxes(锚框):每个特征图单元预设不同长宽比的默认框(类似Faster R-CNN的Anchor)。
-
预测头:对每个Default Box预测:
-
类别得分(是否为人脸)。
-
边界框偏移量(调整Default Box的位置)。
-
(2)训练流程
-
数据准备:
-
标注人脸边界框(Bounding Box)。
-
数据增强:随机裁剪、翻转、颜色抖动等。
-
-
匹配Default Boxes:
-
将真实框(Ground Truth)与最接近的Default Box匹配。
-
-
损失函数:
-
分类损失:Softmax交叉熵(判断是否为人脸)。
-
定位损失:Smooth L1 Loss(调整边界框位置)。
-
-
难例挖掘:
-
针对负样本(背景)远多于正样本(人脸)的问题,保留分类损失最高的部分负样本。
-
(3)检测流程
-
输入图像:调整大小至固定尺寸(如300×300)。
-
前向传播:通过SSD网络,输出所有Default Box的类别和位置。
-
后处理:
-
非极大值抑制(NMS):去除重叠的冗余检测框。
-
阈值过滤:保留置信度高于阈值的检测结果(如0.5)。
-
代码在face_detection\4.SSD.ipynb
3.SSD vs. 其他人脸检测方法
| 方法 | 速度 | 精度 | 适用场景 |
| Haar | ⚡⚡⚡ | ⚡⚡ | 实时性要求高,资源受限设备 |
| HOG | ⚡⚡ | ⚡⚡⚡ | 中等精度,光照复杂场景 |
| YOLO | ⚡⚡⚡ | ⚡⚡⚡ | 实时检测,平衡速度与精度 |
| SSD | ⚡⚡⚡ | ⚡⚡⚡⚡ | 高精度实时检测,小目标优化 |
| Faster R-CNN | ⚡ | ⚡⚡⚡⚡⚡ | 高精度需求,非实时场景 |
MTCNN检测人脸
代码在face_detection\5.MTCNN.ipynb

-
MTCNN简介
MTCNN(Multi-Task Cascaded Convolutional Networks)是一种基于深度学习的高精度人脸检测算法,由Kaipeng Zhang等人在2016年提出。其核心特点是通过三级级联网络(P-Net、R-Net、O-Net)逐步细化检测结果,同时完成以下任务:
-
人脸检测:定位图像中的人脸边界框。
-
关键点检测:标记5个面部特征点(双眼、鼻尖、嘴角)。
-
人脸对齐:通过仿射变换矫正人脸角度。
优势:
-
高精度检测多角度、遮挡、小尺寸人脸。
-
实时性较好(在GPU上可达30+ FPS)。
-
开源实现广泛(如Python的
mtcnn库)。
2. MTCNN检测流程
(1)三级级联网络
| 网络 | 输入 | 作用 |
| P-Net (Proposal Net) | 原始图像金字塔 | 快速生成候选窗口,初步过滤非人脸区域。 |
| R-Net (Refinement Net) | P-Net输出的候选框 | 进一步剔除误检,优化边界框位置。 |
| O-Net (Output Net) | R-Net输出的候选框 | 精确定位人脸边界框和5个关键点,输出最终结果。 |
(2)具体步骤
-
图像金字塔构建
-
缩放原始图像至不同尺寸(如12×12、24×24等),以检测不同大小的人脸。
-
-
P-Net粗检测
-
对每个缩放后的图像滑动窗口,预测:
-
是否为人脸(二分类)。
-
边界框的偏移量(用于调整窗口位置)。
-
-
通过非极大值抑制(NMS)合并重叠候选框。
-
-
R-Net精炼
-
将P-Net的候选框resize到24×24,输入R-Net。
-
进一步过滤误检,优化边界框坐标。
-
-
O-Net输出结果
-
将R-Net的候选框resize到48×48,输入O-Net。
-
输出:
-
最终人脸边界框。
-
5个关键点坐标(左眼、右眼、鼻尖、左嘴角、右嘴角)。
-
-
3.完整代码示例
import cv2
from mtcnn import MTCNN
import matplotlib.pyplot as plt
# 初始化MTCNN检测器
detector = MTCNN()
# 读取图像
img = cv2.imread('test.jpg')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # MTCNN需要RGB格式
# 检测人脸
results = detector.detect_faces(img_rgb)
# 绘制结果
for result in results:
# 获取边界框和关键点
x, y, w, h = result['box']
keypoints = result['keypoints']
# 绘制人脸矩形框
cv2.rectangle(img, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 绘制5个关键点
for point in keypoints.values():
cv2.circle(img, (int(point[0]), int(point[1])), 3, (0, 255, 0), -1)
# 显示结果(BGR转RGB)
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
plt.axis('off')
plt.show()输出结果解析
-
results列表中的每个元素包含:-
box: 人脸边界框坐标[x, y, width, height]。 -
confidence: 检测置信度(0~1)。 -
keypoints: 5个关键点的字典:
-
{
'left_eye': (x, y),
'right_eye': (x, y),
'nose': (x, y),
'mouth_left': (x, y),
'mouth_right': (x, y)
}4. 参数调优
| 参数 | 作用 | 推荐值 |
| min_face_size | 最小人脸尺寸(像素),越小越能检测小脸,但会增加计算量。 | 20 |
| scale_factor | 图像金字塔缩放因子(0~1),越小检测越精细,但速度越慢。 | 0.709 |
| thresholds | 三级网络的置信度阈值(P-Net, R-Net, O-Net),越高误检越少,但可能漏检。 | [0.6, 0.7, 0.7] |
示例:
detector = MTCNN(
min_face_size=20,
scale_factor=0.709,
thresholds=[0.6, 0.7, 0.7]
)5. 性能对比
| 方法 | 速度 | 精度 | 关键点支持 | 适用场景 |
| MTCNN | ⚡⚡ | ⚡⚡⚡⚡ | ✅ | 高精度检测+关键点需求 |
| Haar | ⚡⚡⚡ | ⚡⚡ | ❌ | 实时性要求高的简单场景 |
| Dlib (HOG) | ⚡⚡ | ⚡⚡⚡ | ✅ | 平衡速度与精度 |
| YOLO | ⚡⚡⚡ | ⚡⚡⚡ | ❌ | 多人脸快速检测 |
6. 常见问题解决
-
速度慢:
-
减小输入图像尺寸(如缩放到640×480)。
-
使用GPU加速(需安装
tensorflow-gpu)。
-
-
漏检小脸:
-
降低
min_face_size(如设为10)。 -
增大
scale_factor(如0.8)。
-
7. 应用场景
-
人脸识别预处理:检测+对齐(如FaceNet)。
-
美颜滤镜:基于关键点添加特效(如贴纸、美瞳)。
-
视频会议:实时人脸跟踪和虚拟背景。
总结
MTCNN通过三级级联网络实现高精度人脸检测和关键点定位,适合需要精细结果的场景(如人脸识别、AR应用)。若需更高速度,可尝试轻量化模型(如MobileNet-SSD)。
人脸检测训练模型
文件在face_recognition\1.Eigen_fisher_LBPH.ipynb
这个文件需要读取一些图片路径可能有问题,根据实际的路径进行修改
这里主要介绍3个不同分类器训练人脸检测的效果

1.LBPH (Local Binary Patterns Histograms)
原理
-
基于局部二值模式(LBP),通过比较像素点与其邻域的灰度值生成二进制编码,统计直方图作为特征。
-
对光照变化鲁棒性强,计算效率高。
特点
-
训练速度快,适合小型数据集。
-
对局部纹理敏感,能捕捉人脸细节。
-
支持增量学习(可动态添加新样本)。
代码示例
recognizer = cv2.face.LBPHFaceRecognizer_create(
radius=1, # LBP半径(默认1)
neighbors=8, # 邻域像素数(默认8)
grid_x=8, # 水平分块数
grid_y=8, # 垂直分块数
threshold=100.0 # 分类阈值
)
recognizer.train(train_images, labels) # 训练
label, confidence = recognizer.predict(test_image) # 预测适用场景
-
实时应用(如门禁系统)。
-
光照条件多变的环境。
2. EigenFaces (PCA-Based)
原理
-
使用主成分分析(PCA)将高维人脸图像降维,保留最大方差的特征向量(即“特征脸”)。
-
通过投影到特征空间进行识别。
特点
-
全局特征,对姿态和表情敏感。
-
要求所有输入图像尺寸相同。
-
对光照变化敏感,需预处理(如直方图均衡化)。
代码示例
python
recognizer = cv2.face.EigenFaceRecognizer_create(
num_components=100, # 保留的主成分数量(默认80)
threshold=5000.0 # 分类阈值
)
recognizer.train(train_images, labels)
label, confidence = recognizer.predict(test_image)适用场景
-
人脸数据库较小且对齐良好的场景。
-
需要快速原型验证时。
3. FisherFaces (LDA-Based)
原理
-
基于线性判别分析(LDA),在降维的同时最大化类间距离、最小化类内距离。
-
是EigenFaces的改进版,增强了分类判别能力。
特点
-
对光照和姿态变化比EigenFaces更鲁棒。
-
需要更多样本(每类至少2张图像)以优化类间分离。
-
计算复杂度高于EigenFaces。
代码示例
python
recognizer = cv2.face.FisherFaceRecognizer_create(
num_components=100, # 保留的成分数量(默认80)
threshold=5000.0 # 分类阈值
)
recognizer.train(train_images, labels)
label, confidence = recognizer.predict(test_image)适用场景
-
中等规模数据集(如员工考勤系统)。
-
需要更高精度的分类任务。
对比总结
| 分类器 | 核心算法 | 优点 | 缺点 | 适用场景 |
| LBPH | LBP直方图 | 光照鲁棒,计算快,支持增量学习 | 对全局特征不敏感 | 实时应用、动态环境 |
| EigenFaces | PCA | 简单高效,适合小数据集 | 对光照和姿态敏感 | 快速验证、对齐良好的图像 |
| FisherFaces | LDA | 分类精度高,比EigenFaces更鲁棒 | 需要更多样本,计算复杂 | 中等规模数据库、高精度需求 |
选择建议
-
优先尝试LBPH:
-
适用于大多数实时场景,尤其是光照多变的条件。
-
-
数据对齐良好时用FisherFaces:
-
若样本充足且需要高精度,FisherFaces优于EigenFaces。
-
-
EigenFaces用于基线测试:
-
适合快速验证算法可行性,但对环境敏感。
-
报错:
--------------------------------------------------------------------------- error Traceback (most recent call last) Cell In[4], line 1 ----> 1 plt.imshow(cv2.cvtColor(img,cv2.COLOR_BGR2RGB)) error: OpenCV(4.11.0) D:\a\opencv-python\opencv-python\opencv\modules\imgproc\src\color.cpp:199: error: (-215:Assertion failed) !_src.empty() in function 'cv::cvtColor'
解压文件,修改一下路径
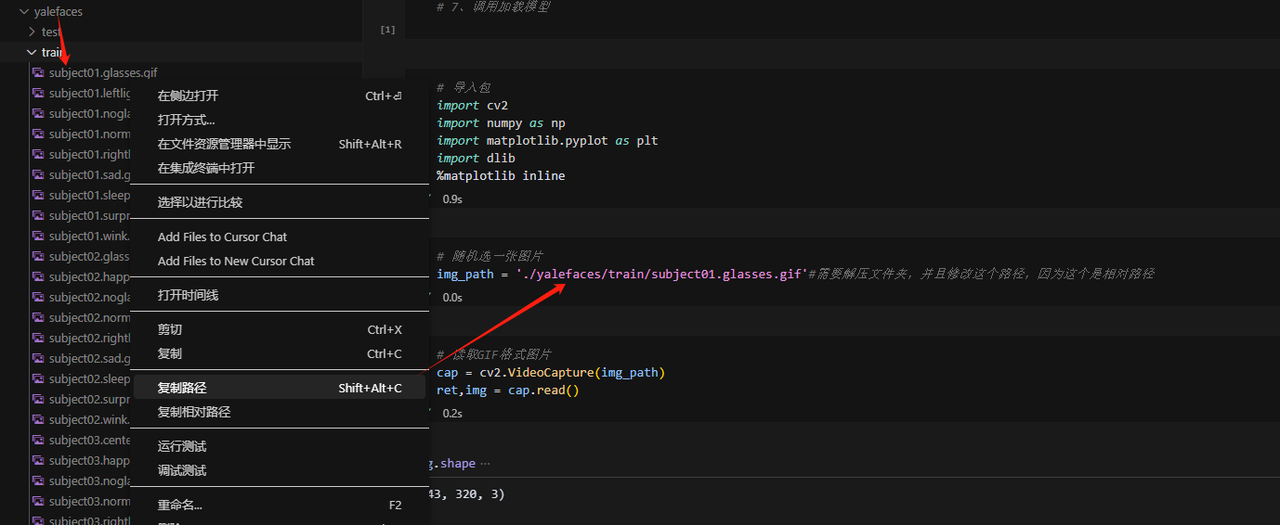
运行到
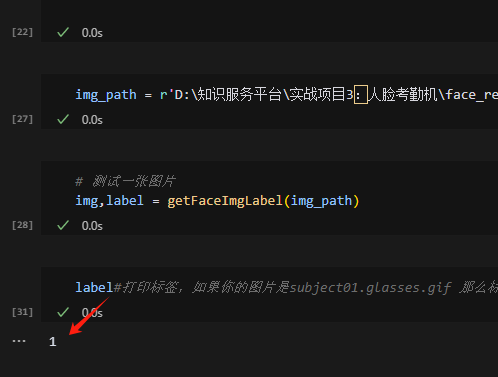
查看打印标签,发现和图片的id一致,则说明模型预测正确
resnet人脸关键点检测
文件在face_recognition\2.resnet.ipynb
这个文件需要读取一些图片路径可能有问题,根据实际的路径进行修改

人脸关键点检测(Facial Landmark Detection)是计算机视觉中的核心任务,用于定位人脸的五官轮廓(如眼睛、鼻子、嘴角等)。ResNet(残差网络)因其强大的特征提取能力和训练稳定性,被广泛用于高精度关键点检测。以下是详细解析:
1. ResNet在人脸关键点检测中的优势
**(1) 深层网络的优势**
-
残差连接(Residual Block):解决深层网络的梯度消失问题,支持训练超过100层的网络。
-
多尺度特征融合:通过不同层级的特征图捕捉局部细节和全局结构。
-
高精度:在300W、WFLW等公开数据集上达到SOTA(State-of-the-Art)性能。
**(2) 适用场景**
-
人脸对齐:为后续的人脸识别、表情分析提供标准化输入。
-
AR/VR:虚拟化妆、表情驱动。
-
医学分析:唇语识别、面部肌肉运动研究
2.与其他方法的对比
| 方法 | 优点 | 缺点 |
| ResNet | 高精度,支持端到端训练 | 计算量大 |
| Dlib (HOG+SVM) | 速度快,适合实时应用 | 对遮挡和侧脸效果差 |
| MTCNN | 多任务(检测+关键点),轻量级 | 关键点数量少(仅5点) |
| HRNet | 保持高分辨率,适合密集关键点 | 训练复杂 |
代码思路:
LBPH训练的是人脸和id,然后辨别是哪个人
resnet用的是人脸和关键点进行训练,然后辨别是哪个人
人脸识别
代码在demo_course.py
在用之前先查看data\feature.csv和data\attendance.csv是否有内容,如果有内容的话就清空,因为这里面注册的是作者的人脸信息。
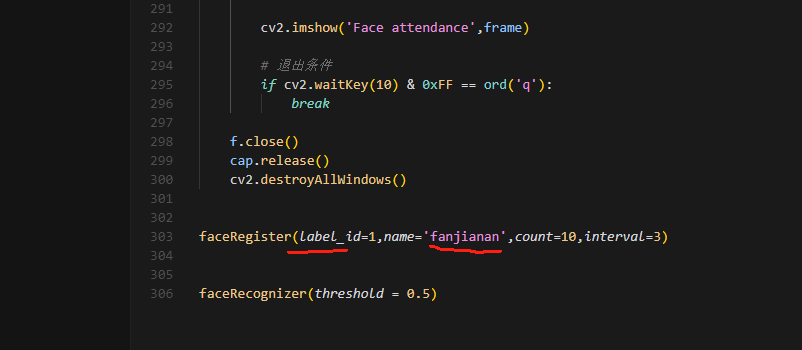
修改这个两个信息,第一个是人脸的id号,然后这个id号叫什么名字。
我们在识别的时候会匹配id号特征,如果匹配上了就输出id号的名称。
所以你需要清空原先的data\feature.csv和data\attendance.csv,否则我人脸id号是1,你的人脸id号也是1就会出错。不同人脸需要有不同id号,同一个人可以用同一个id号。
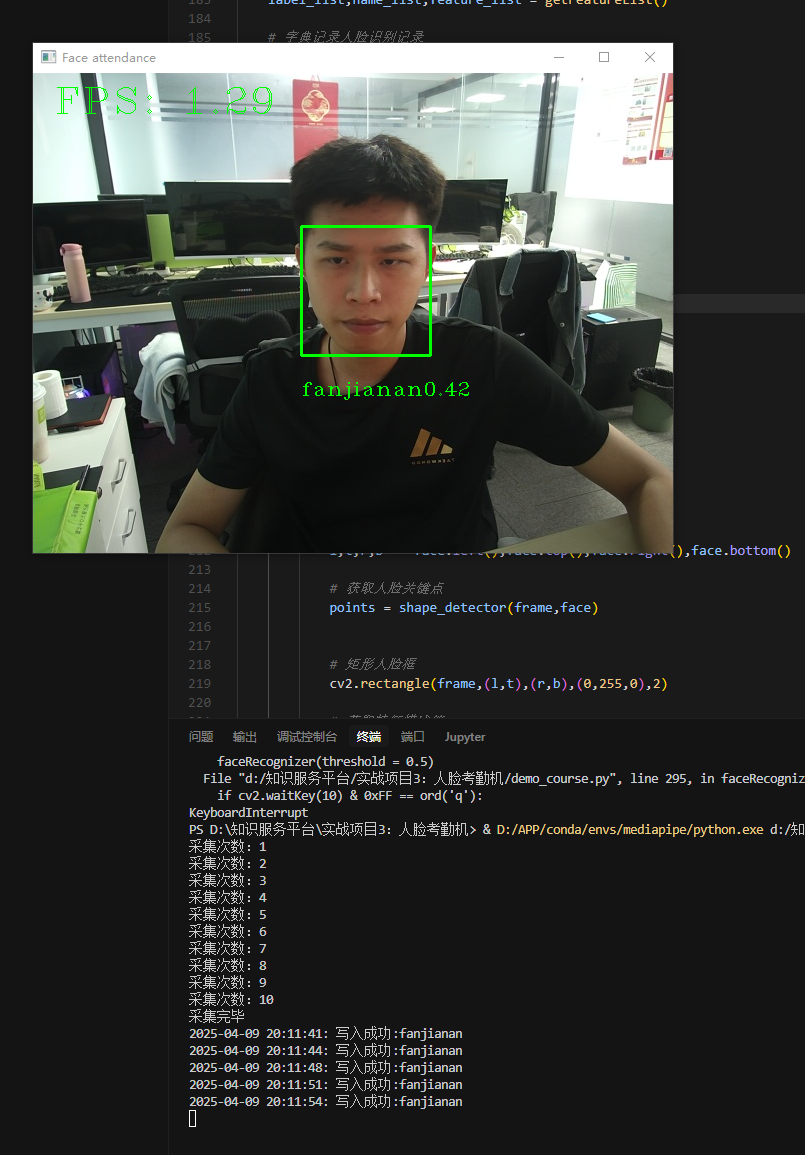
人脸打卡
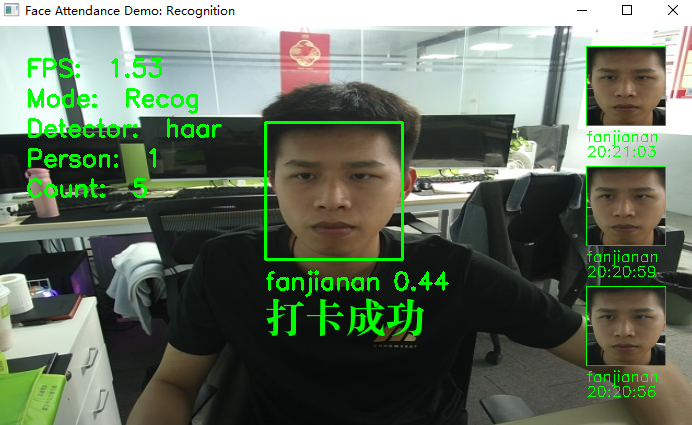
代码在demo_full.py
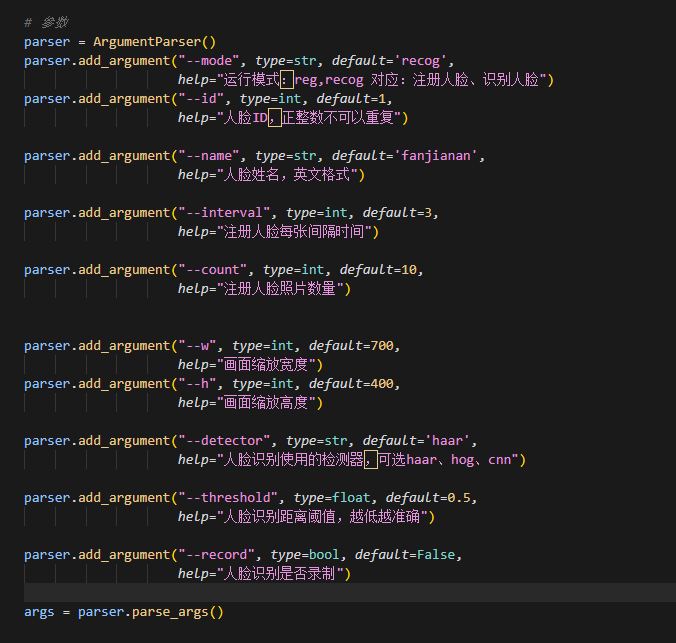
可以修改这些参数,比如mode选择是注册还是识别
name是名称

















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}