






概念
Selenium框架是用于web应用程序的测试工具
特点
- List item开源软件:源代码开放可以根据需要来增加工具的某些功能;
- 跨平台:支持多个平台;
- 核心功能:可以在多个浏览器上进行自动化测试;
- 多语言:支持多种语言(如Java、python、c#等);
- 成熟稳定:被多个互联网大厂广泛使用;
- 功能强大:能够实现满足商业工作的大部分功能,且因开源性可实现定制化功能;
1.selenium原理
-
List itemSelenium Client Library:selenium自动化测试人员可以使用Java、python等语言,利用他们提供的库来编写脚本;
-
JSON Wire Protocol Over HTTP Client:JSON Wire Protocol是在HTTP服务器之间传输信息的REST风格的API,每个浏览器驱动程序(如FirefoxDriver、ChromeDirver等)都有它们各自的HTTP服务器;
-
Browser Driver:不同的浏览器都包含一个单独的浏览器驱动程序,浏览器驱动程序与相应的浏览器通信,当浏览器驱动程序收到指令时,则将在相应的浏览器中执行,响应信息将以HTTP形式返回;
-
Browsers:Selenium支持多种浏览器,如Firefox、Chrome、IE、Safari、Edg等;
先是测试人员通过Selenium Client Library编写脚本,再通过JSON Wire Protocol Over HTTP Client 协议将脚本内容传入Browser Drivers(浏览器驱动),再由Browser Drivers(浏览器驱动)执行脚本将指令传入浏览器执行,等待浏览器返回执行结果再逐步返回;
2.selenium基础使用
首先下载安装selenium第三方库
pip install selenium
再下载对应浏览器的Dirver(可自行搜索下载对应当前浏览器版本的驱动,如果没有对应浏览器版本的驱动则选择版本号最近的驱动下载,记住驱动文件下载解压后的位置)
Chrome浏览器Dirver下载地址:http://npm.taobao.org/mirrors/chromedriver/
再导入selenium库
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
使用Dirver驱动
driver_path = r'../chromedriver.exe' #驱动文件位置
browser = webdriver.Chrome(service=Service(driver_path))#获取一个浏览器操作对象
启动浏览器进入web网页
url="http:/www.baidu.com"
browser.get(url)#进入网页
time.sleep(2)#等待2秒查看效果
browser.quit()#关闭网页,回收资源
3.元素抓取
web网页所有内容几乎都由元素组成,即我们想要使用selenium自动化操作测试web网页,也就是要先定位页面元素,再调用方法进行相应操作;
定位元素可在浏览器中按f12或设置中进入开发者模式查看网页源码,使用浏览器提供的工具进行元素定位
例如:
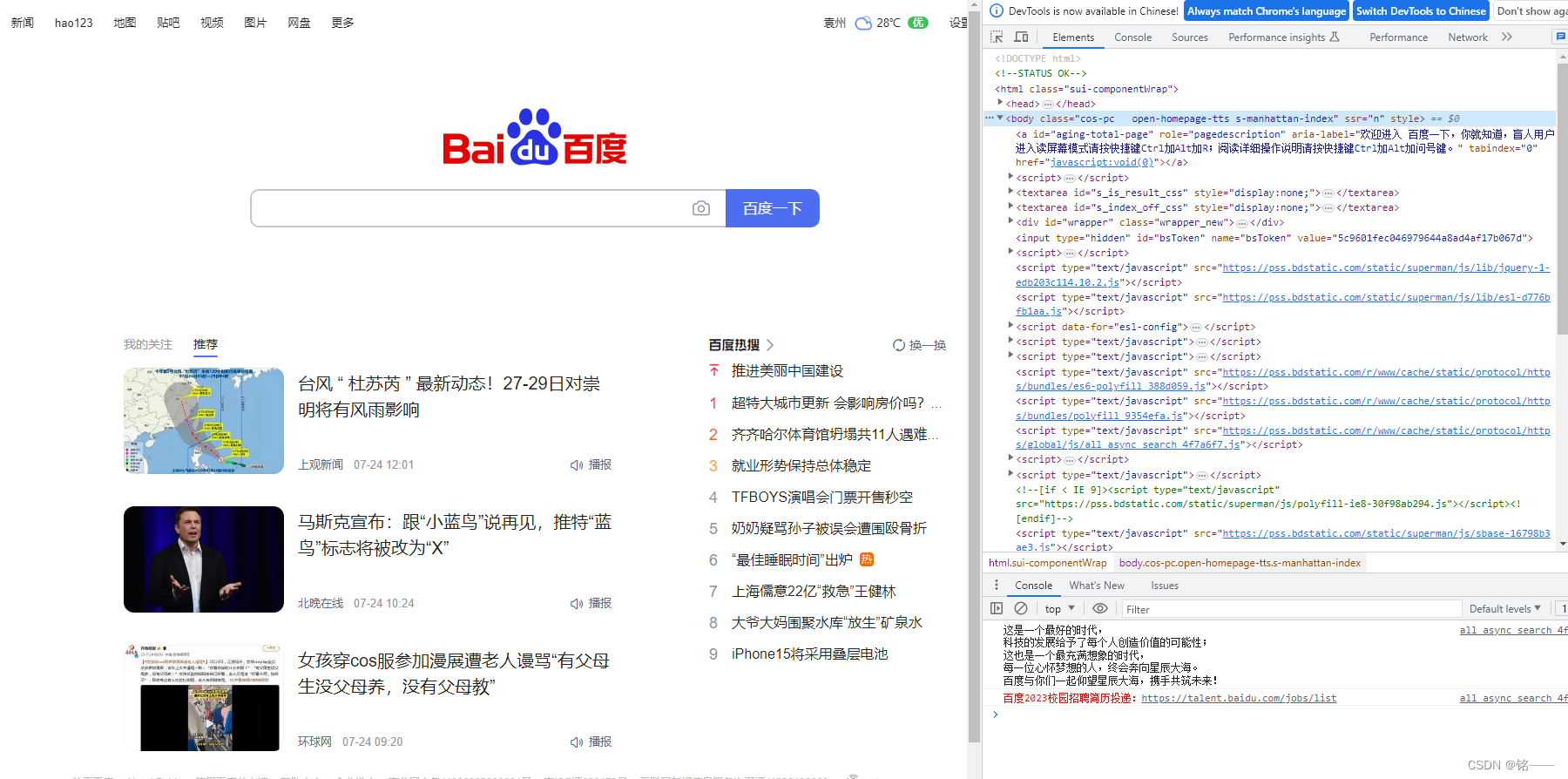
可以点击右上角箭头,再点击相应页面想要操作的位置来进行页面内容源码位置的定位
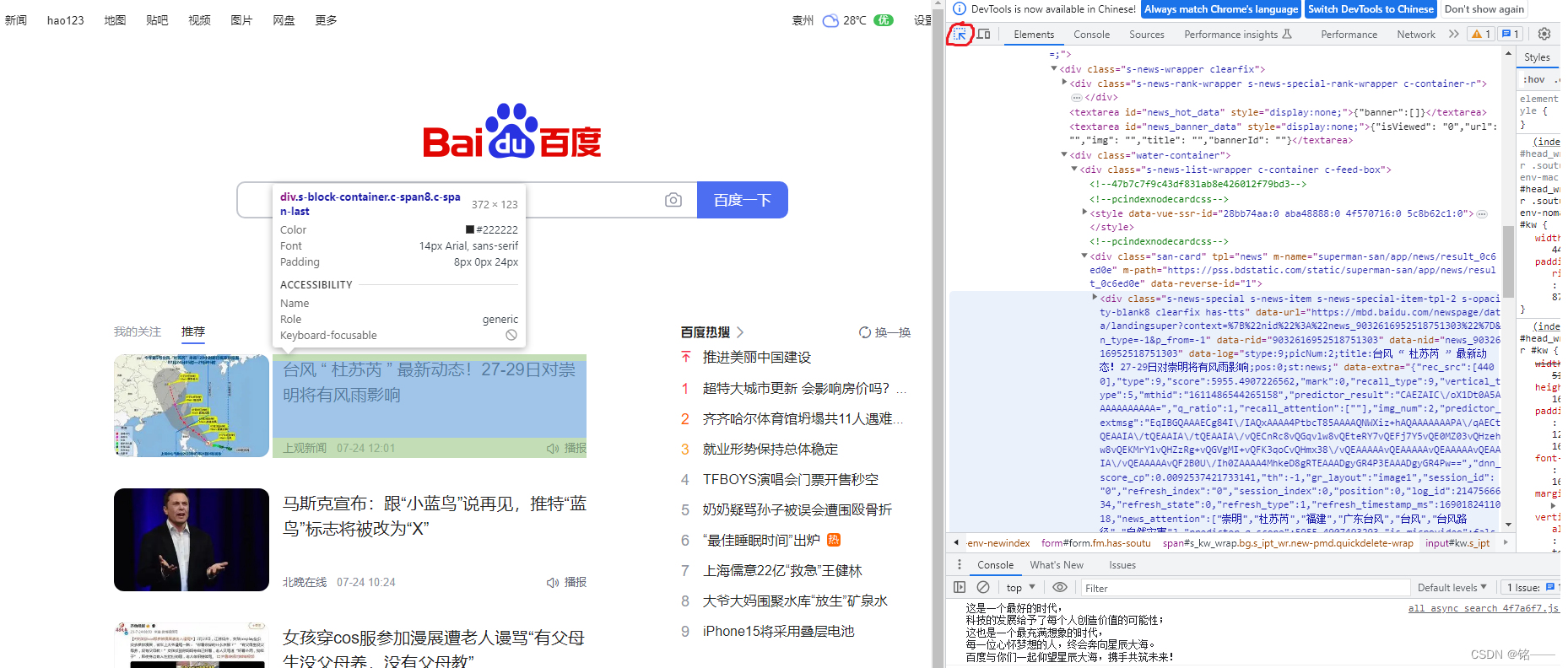
再根据定位到的源码位置选取合适的元素来进行操作
4.selenium元素定位操作
元素定位:可以使用.find_element、.find_elements方法
find_element方法:find_element在找到网页源码中第一个符合条件的属性值之后停止查找返回操作句柄
find_element方法示例:
browser.find_element('css selector',"[class='s-news-item-title c-link c-font-big c-gap-bottom-small title-clamp-3 has-tts ']").click()#根据class属性定位到指定页面位置进行点击操作,也可选取其他属性定位,但要注意选取的属性对应的值要是唯一的或者是源码中的第一个,因为find_element在找到第一个符合条件的元素之后就会停止查找
find_elements方法:find_elements会查找网页源码中所有符合条件的属性,并返回一个包含所有符合条件元素的句柄的列表
temp=browser.find_elements('css selector',"[class='s-news-item-title c-link c-font-big c-gap-bottom-small title-clamp-3 has-tts ']")#获取所有符合条件的元素句柄
for i in range(temp):#循环对所有符合条件的句柄进行点击操作
temp[i].click
元素的操作:
- clear() 清除文本
- send_keys() 模拟输入
- click() 单击元素
元素属性获取:
- size 返回元素大小
- text 返回元素的文本
- get_attribute() 获取属性值
- is_display() 判断元素是否可见
- is_enabled() 判断元素是否可以
例:
title=browser.find_elements('css selector',"[class='s-news-item-title c-link c-font-big c-gap-bottom-small title-clamp-3 has-tts ']").get_attribute('title')#获取目标元素中的title的值
print(title)
5.鼠标操作
selenium提供了专门的模拟鼠标操作的方法以供自动化测试时模拟人点击鼠标的操作
使用方法:
使用之前首先要导入鼠标操作所需的包
from selenium.webdriver.common.action_chains import ActionChains #导入鼠标操作所需要的包
再创建一个鼠标事件对象
mouse=ActionChains(browser) #创建鼠标事件对象
再对鼠标事件对象做相应的操作
常用的鼠标事件对象操作方法:
- context_click() #模拟鼠标右击操作
- double_click() #模拟鼠标双击效果
- drag_and_drop() #模拟鼠标拖动效果
- move_to_element() #模拟鼠标悬停效果
- perform() #执行此方法以上的所有鼠标操作方法,若没有使用此方法则所有鼠标操作将不被执行
- 其他操作方法具体可参见ActionChains的源码
例子:
from selenium.webdriver.common.action_chains import ActionChains #导入鼠标操作所需要的包
mouse=ActionChains(browser) #创建鼠标事件对象
browser.implicitly_wait(5)
action=browser.find_element('css selector','[class="channel-link"]') #定位鼠标要悬停位置的元素
mouse.move_to_element(action) #鼠标悬停
time.sleep(2)
mouse.context_click() #鼠标在悬停位置点击
mouse.perform() #开始执行鼠标操作
6.键盘操作
selenium除了提供了鼠标操作的方法也提供了键盘操作的方法—element.send_keys();
该方法可以写入两种参数:一种是普通字符串用于直接输入,一种是“键盘按键”用于模拟键盘上诸如“删除”、“全选”等功能键
例:
from selenium.webdriver.common.keys import Keys #导入包
user='123456abc'
user_box.send_keys(user) #输入账号
user_box.send_keys(Keys.CONTROL,'a') #模拟键盘输入快捷键ctrl+a进行全选
user_box.send_keys(Keys.BACKSPACE) #模拟键盘删除
user_box.send_keys(user) #重新输入
7.下拉框
下拉框其实就是HTML中的< select >元素,主要的操作就是选中某个选项< option >
操作步骤:
- 通过select元素创建Select对象
- 通过Select对象的方法选中选项
select_by_index() #根据option索引来定位,索引从0开始
select_by_value() #根据option属性value的值来定位
select_by_visible_text() #根据option显示的文本来定位
例:
from selenium.webdriver.support.select import Select
action=browser.find_element('css selector','[class="channel-link"]')#将找到的元素句柄强转为select才能选择下拉框的隐藏元素
select=Select(action)
select.select_by_visible_text('连载动画') #根据文本来选择
select.select_by_value('') #根据value的值来选择
select.select_by_index(2) #根据index序号来选择,序号从0开始
8.滚动条
虽然WebDriver类库中并没有直接提供对滚动条进行操作的方法,但是他提供了一个可调用JavaScript脚本的方法(且不需要额外导包),因此我们可以提供JavaScript脚本来达到操作滚动条的目的;
使用方法:
driver.execute_script(js代码)
控制滚动条滚动的js代码:
- 绝对滚动
window.scrollTo(x,y) #x是指页面的x轴坐标,y同理是指y轴坐标 - 相对滚动
window.scrollBy(x,y)
例:
js_str='window.scrollTo(0,10000)' #将js代码存入字符串中,页面x轴不变,y轴移动到10000的位置,但是如果没有10000这么多也不会报错,只是会移动到最下方
browser.execute_script(js_str) #利用webdriver库执行js代码
9.警告框
警告框是指通过js中的alert、confirm、prompt方法弹出来的弹框,它会阻挡我们对网页的继续操作;
对应方法:
- 获得警告框:alert=driver.switch_to.alert
- 关闭警告框:适用于以上介绍的三种类型警告框alert.dismiss()
- 确认(也会自动关闭):适用于confirm和prompt–alert.accept()
- 输入文字:适用于prompt–alert.send_keys()
- 获取警告框中的文字:alert.text
例:
alert=browser.switch_to.alert #切换至警告框框架
print(alert.text) #打印警告框的文本
10. frame框架切换
在一些网页中会使用frame框架(此框架含义为“矩形区域”)嵌套即在一个网页中嵌套上另一个网页,相关的HTML标签一般有:< iframe >、< frameset >、< frame >;
虽然有三种标签但是对于selenium来说定位切换的方法都是一样的;
切换到下级子Frame方法:
driver.switch_to.frame() #通过参数来定位切换,参数可以是index、id、name、元素
driver.switch_to.frame('frame_name')#通过frame_name切换
driver.switch_to.frame(1)#通过index切换,序列从0开始
driver.switch_to.frame('frame_id')#通过frame_id切换
driver.switch_to.frame(driver.find_elements(By.TAG_NAME, "iframe")[0])#通过定位元素方法定位到目标frame框架切换
切换回根页面(即最外层的页面)
driver.switch_to.default_content()
例:
browser.switch_to.frame("i_cecream") #通过id来切换至目标框架
browser.switch_to.default_content() #切换为原始框架
11.窗口切换
概念:
在selenium中通过一个随机生成的字符串(uuid)作为某个窗口的唯一标识;
多窗口:
一个浏览器程序通常是可以打开多个网页,每一个网页都构成了浏览器的一个“标签”,而有些超链接是_target='blank’则会在新的窗口打开,发生窗口的切换,虽然窗口发生了切换但是在selenium中其实并不会自动切换窗口对象,需要我们手动去切换;
handler的获取和切换:
- 获取所有handle,返回一个窗口句柄列表
driver.window_handles
- 获取单个handle,返回一个窗口句柄
driver.current_window_handle
- 切换页面
driver.switch_to.window(handle)
例:
d = browser.window_handles #获取所有打开页面的句柄返回列表,最新打开的在最后
browser.switch_to.window(d[-1]) #切换页面
12.登录验证码处理
有些登录功能会为了防止有机器操作而添加验证码功能来区分人和机器,验证码有多种形式,常见的有字母数字、旋转图形、拖动滑块等,对于这些验证码我们可以使用以下几种方式应对处理:
- 去掉验证码
在测试环境下采用; - 设置万能验证码
在生产环境下采用; - 验证码识别技术
通过python-tesseract来识别图片类型的验证码,但是识别率很难达到100%; - 使用打码平台
测试其他外部网站需要,此项服务需要付费; - 记录cookie
通过记录cookie来跳过登录(较为推荐);
13.cookie的处理
概念:
浏览器和服务器之间通过cookie头机制可以形成状态的保持,也就是说浏览器和服务器之间通过一个唯一标识cookie来记录保存用户状态信息,可以理解为在服务器中为浏览器用户生成一个文件来保存用户各项信息,浏览器则在向服务器发送操作时加上文件夹名称(cookie)来告诉服务器要操作的具体是那个文件;
相关方法:
- 获取本网站所有的本地cookie
get_cookies() #返回一个列表字典,字典的键有:domain、expiry、httpOnly、name、path、secure、value
- 获取指定cookie
get_cookie(name)#返回一个字典,字典的键有:domain、expiry、httpOnly、name、path、secure、value
- 添加cookie
add_cookie() #参数为字典,主要的键为:name value
14.页面等待
由于网页加载一些资源需要一些时间,而为了防止自动化代码响应时间快于网页加载时间导致代码元素定位错误,所有我们需要添加使自动化代码等待的代码;
- 强制等待
使用time库的sleep使代码进行强制等待,但是由于不知道网页具体要加载多久,所有强制等待可能会造成时间资源的浪费或者代码等待时间不够导致元素定位依旧失败;
例:
import time
time.sleep(2)#强制页面等待2秒再执行其他操作
- 显示等待
原理:
在未超过指定最大等待时间的前提下每隔一定的时间就不断尝试查找元素,若找到指定元素则直接返回结束等待,超过最大等待时间依旧未找到的话则报错
使用方法:
先通过WebDriverWait包装webDriver对象,再使用WebDriverWait的util方法,传入可调用对象(通常为presence_of_element_located函数的返回值)
例:
#导入显示等待所需要的包
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(browser,5).until(EC.presence_of_element_located(("css selector","[class='bili-mini-mask']")))#设置最大等待时间为5秒,在等待时间内不断尝试查找是否出现元素class='bili-mini-mask'
#显示等待的缺点:需要导入的包太多,不易记忆
- 隐式等待
隐式等待可以良好的将显示等待的缺点摒弃,即不需要额外导包,虽然不能等待指定元素出现,但是也是可以动态的等待页面资源加载;
例:
#隐式等待
browser.implicitly_wait(5) # 不指定等待什么元素出现,最大等待5秒
15.浏览器的其他操作
- 浏览器操作(方法)
1.maximize_window() #浏览器最大化
2.set_window_size(width,height) #设置浏览器宽、高单位为像素点
3.set_window_position(x,y) #设置浏览器窗口位置,即浏览器窗口左上角相对于屏幕左上角的位置
4.back() #浏览器页面后退操作
5.forward() #浏览器页面前进操作
6.refresh() #浏览器刷新操作
7.close() #关闭当前页面
8.quit() #关闭浏览器回收资源
9.get_screenshot_as_file(保存路径) #当出现问题时可以使用该方法进行截图保存
例:
browser.quit()
- 浏览器信息(属性)
1.title获取页面title
2.current_url 获取当前页面URL
例:
print(browser.title)















 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









