







selenium模块
一、selenium模块简介
- 作用:直接调用浏览器(支持所有主流的浏览器,包括PhantomJS无界面浏览器),可以接收指令,让浏览器自动加载页面,获取需要的数据
- 工作原理:利用浏览器原生的API,封装成一套更加面向对象的Selenium WebDriver API,直接操作浏览器页面里的元素,以及操作浏览器自身
- 不同浏览器使用不同的webdriver
- webdriver本质是一个web-server,对外提供web API,其中封装了浏览器的各种功能API
- 优点:操作简单
- 缺点:爬取速度会大幅降低
- 运行环境:下载要操作浏览器对应版本的webdriver
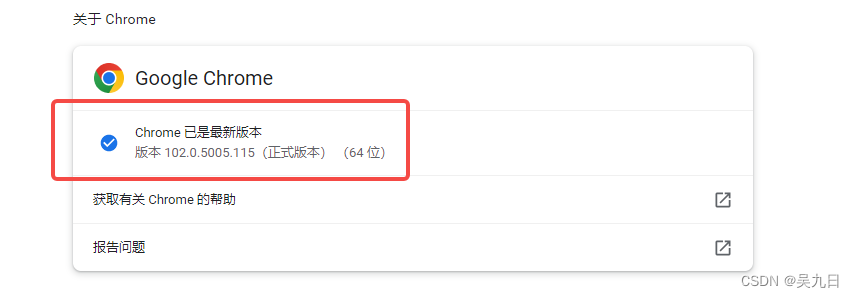
例:chrome浏览器
- 查看浏览器版本
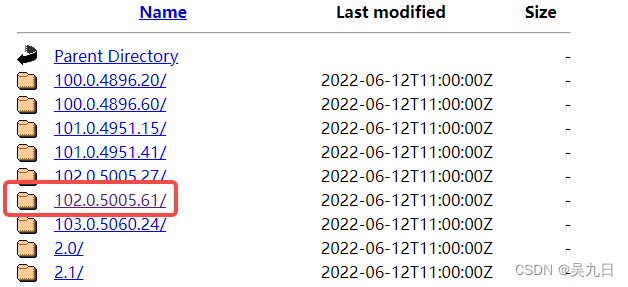
- 下载对应版本的webdriver,可以点击notes.txt进入版本说明页面,查看chrome和chromedriver匹配的版本
- 解压压缩包,获取可调用浏览器的webdriver可执行文件
- 将 chromedriver.exe 所在路径设置为环境变量
- 调用浏览器方法(返回driver对象):
driver = webdriver.Chrome('chromedriver路径'),如果已经设置好环境变量,则路径可以不填
6、实例化配置对象方法:options = webdriver.ChromeOptions()
二、配置对象常用方法
1、开启无界面模式方法
方式一:
options.add_argument("--headless")添加开启无界面模式的命令options.add_argument("--disable-gpu")添加禁用gpu的命令
方式二:
options.set_headles()
macos中chrome浏览器59+版本,Linux中57+版本才能使用无界面模式
2、使用代理ip方法
options.add_argument('--proxy-server="代理ip类型:代理ip地址')添加使用代理ip的命令
3、替换user-agent方法
options.add_argument('--user-agent=浏览器名称')添加替换UA的命令
三、页面等待常用方法
1、强制等待
方法:time.sleep()
特点:达到等待时间后再执行操作(设置时间太短元素可能还未加载出来,设置时间太长会浪费时间)
2、隐式等待
方法:driver.implicitly_wait('时间(s)')
特点:在一段时间(最长等待20秒) 内判断元素是否定位成功,如果完成了,则进行下一步
3、显示等待
方法:WebDriverWait(driver, 设置的最长等待时间, 间隔时间).until(EC.presence_of_element_located((By.LINK_TEXT, '文本')))
特点:每一段间隔时间检查一次规定的标签是否存在,如果达成就停止等待,继续执行后续代码;如果未达成就继续等待,直到超过设置的最长等待时间(最长等待20秒) ,报超时异常
手动实现页面等待原理:利用强制等待和显式等待的思路来手动实现,有次数限制的判断某一个标签对象是否加载完毕/是否存在
四、driver对象常用属性和方法
1、常用属性
driver.page_source当前标签页浏览器渲染之后的网页源代码driver.current_url当前标签页的urldriver.window_handles获取当前所有标签页的句柄列表
2、常用方法
(1)基本方法
driver = webdriver.Chrome(chrome_options=options)实例化带有配置对象的driver对象dirver.get('url')获取标签页driver.close()关闭当前标签页(如果只有一个标签页则关闭整个浏览器)driver.quit()关闭浏览器driver.forward()页面前进driver.back()页面后退driver.screen_shot('图片名称')页面截图
(2)获取标签对象方法
element = driver.find_element_by_id('id名')根据id名返回一个元素element = driver.find_element(s)_by_class_name('类名')根据类名获取元素列表element = driver.find_element(s)_by_name('name属性值')根据name属性值返回包含标签对象元素的列表element = driver.find_element(s)_by_xpath('xpath语法')根据xpath语法返回元素列表element = driver.find_element(s)_by_link_text('文本')根据链接文本获取元素列表element = driver.find_element(s)_by_partial_link_text('文本')根据链接包含的文本获取元素列表element = driver.find_element(s)_by_tag_name('标签名')根据标签名获取元素列表element = driver.find_element(s)_by_css_selector('css选择器')根据css选择器获取元素列表
find_element和find_elements的区别:
- find_element返回匹配到的第一个标签对象,find_elements返回列表
- find_element匹配不到就抛出异常,find_elements匹配不到就返回空列表
by_link_text和by_partial_link_tex的区别:
by_link_text代表全部文本,by_partial_link_tex代表包含某个文本
(3)标签页的切换方法
driver.switch_to.window(current_windows['索引'])根据标签页句柄列表索引下标进行切换
(4)切换frame标签方法
driver.switch_to.frame('frame/iframe标签对象')切换到frame标签嵌套的页面
(5)cookie的处理方法
driver.get_cookies()获取当前标签页的全部cookie信息driver.delete_cookie("Cookie Name")删除一条cookiedriver.delete_all_cookies()删除所有cookie
driver.get_cookies()可配合requests模块使用,将cookie转化为字典:
cookies_dict = {cookie[‘name’]: cookie[‘value’] for cookie in driver.get_cookies()}
(6)执行js代码方法
driver.execute_script('js')执行js
五、element标签对象常用数据提取方法
1、常用属性
element.text获取标签对象文本
2、常用方法
element.get_attribute("属性名")获取属性值element.click()对标签对象进行点击操作element.send_keys ('数据')对标签对象输入数据
六、实战演练
selenium框架应用
- 代码功能:获取每页基本信息
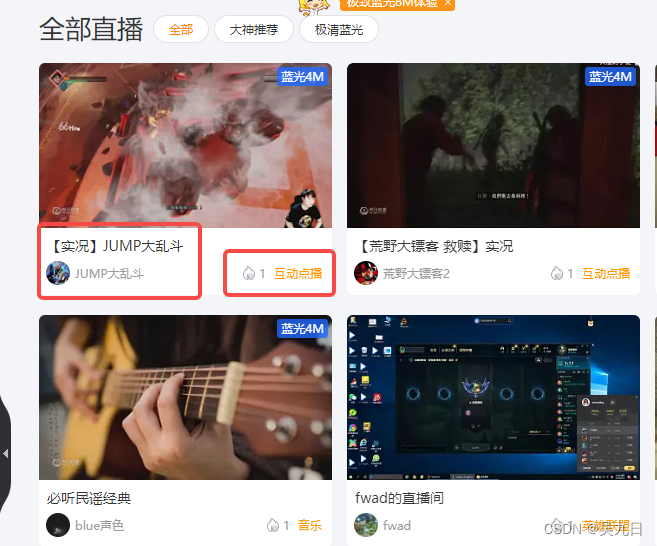
- 代码
from selenium import webdriver
class Huya(object):
def __init__(self):
self.url = ' '# 这里填对应url
self.driver = webdriver.Chrome()
def parse_data(self):
time.sleep(5)
el_list = self.driver.find_elements_by_xpath('//*[@id="js-live-list"]/li')
data_list = []
for el in el_list:
temp = {}
temp['title'] = el.find_element_by_xpath('./a[2]').text
temp['owner'] = el.find_element_by_xpath('./span/span[1]').text
temp['type'] = el.find_element_by_xpath('./span/span[2]').text
temp['num'] = el.find_element_by_xpath('./span/span[3]').text
temp['img'] = el.find_element_by_xpath('./a[1]/img[1]').get_attribute('src')
data_list.append(temp)
return data_list
def save_data(self,data_list):
for data in data_list:
print(data)
def run(self):
self.driver.get(self.url)
while True:
data_list = self.parse_data()
self.save_data(data_list)
try:
el_next = self.driver.find_element_by_xpath('//*[@class="laypage_next"]')
el_next.click()
except:
break
if __name__ == '__main__':
huya = Huya()
huya.run()
















 2090
2090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









