







节前略闲,看了java8并行流,写个了wordCount。本以为易如反掌,结果却折腾了一下午!
在本文中wordcount是指 以空格作为词的分割符号,统计一个语句中出现的词数
如何用java8并行流写WordCount,我开始的想法是先写个串行流的workcount,之后stream.parallel()将流并行化。
串行流的wordCout,也就是如下3步:
- 将String转换为Character流,
- 针对每一个char进行判断,如果上一个字符是空格并且当前字符不是空格,则词数加1
- 将对每一个流进行汇总, 将所有流中统计的数量进行累加。
有了想法后,就开始写串行流的wordcount了。
定义存储流中间结果的实体。counter用于记录当前流处理过的词数量,lastSpace表示上一个字符是否是空格。
/**
* 用于存储流的中间数据
*/
public class WordCounterTuple {
private int counter; //用于记录当前词数量
private boolean lastSpace;//标记上一个词是否是空格
public WordCounterTuple( boolean lastSpace,int counter) {
super();
this.counter = counter;
this.lastSpace = lastSpace;
}
// 省略getter,setter
}将String转换为Character流,利用IntStream.range(易于拆分)结合String::charAt。而核心的wordcount逻辑使用stream的reduce方法。
stream.reduce的基本逻辑如下:
reduce方法类似:
//子流1:
U result1 = identity;
* for (T element : this stream)
* result1 = accumulator.apply(result, element)
* return result1;
//子流2:
U result2 = identity;
* for (T element : this stream)
* result2 = accumulator.apply(result, element)
* return result2;
//合并:
U finalResult=combiner.apply(result1 ,result2 )
具体到wordcount就是:
accumulator对每个字符进行判断,如果上一个字符是空格并且当前字符不是空格,则词数加1。
import java.util.function.BiFunction;
/**
* 针对每个char,进行处理
* 只有,当前char不是空格,上一个char是空格,计数才加1;
* 之后以当前字符,作为上一个字符,
* 注这里仅仅标记是否是空格
*/
public class WordCountAccumulator
implements BiFunction<WordCounterTuple,Character,WordCounterTuple>{
@Override
public WordCounterTuple apply(
WordCounterTuple lastWordCounterTuple,
Character currentChar) {
if(Character.isWhitespace(currentChar)){
return new WordCounterTuple(true,lastWordCounterTuple.getCounter());
}else{
return lastWordCounterTuple.isLastSpace()
?new WordCounterTuple(false,lastWordCounterTuple.getCounter()+1)
:new WordCounterTuple(false,lastWordCounterTuple.getCounter());
}
}
}combiner对每个子流的结果进行累加,也就是finalResult=result1.getCounter()+result2.getCounter();
import java.util.function.BinaryOperator;
/**
*合并器,将多个流的的结果进行累加
*/
public class WordCountCombiner implements BinaryOperator<WordCounterTuple>{
@Override
public WordCounterTuple apply(WordCounterTuple t, WordCounterTuple u) {
return new WordCounterTuple(t.isLastSpace(),t.getCounter()+u.getCounter());
}
}整合后coutWords方法如下:
/**
* 使用流的reduce方法执行
*/
public static int countWords(Stream<Character> stream) {
WordCounterTuple wordCounter = stream.reduce(
new WordCounterTuple( true,0),
new WordCountAccumulator(),
new WordCountCombiner());
System.out.println(wordCounter.getCounter());
return wordCounter.getCounter();
}之后测试下,这里我们使用的测试语句是Taylor Swift《...Ready For It?》的小部分歌词
public class WordCount {
//Taylor Swift《...Ready For It?》
static final String SENTENCE_36 = "Knew he was a killer first time that I saw him "+//11
" Wonder how many girls he had loved and left haunted "+//10
" But if he's a ghost then I can be a phantom "+//11
" Holdin' him for ransom ";//4
public static void main(String[] args) {
// //串行流
// //将String,映射为Character流
Stream<Character> charStream=IntStream.range(0,SENTENCE_36.length())
.mapToObj(SENTENCE_36::charAt);
WordCount.countWords(charStream);
}
}运行结果为:

运行结果与预期的一致。
理论上,只要将countWords中的stream.reduce变为 stream.parallel().reduce(...),并行流就写好了。而实际上并没有!
按照预期写的并且wordcount方法。
/**
* 统计字符的并行方法。
*/
public static int countWordsParallel(Stream<Character> stream) {
WordCounterTuple wordCounter = stream.parallel().reduce(
new WordCounterTuple( true,0),
new WordCountAccumulator(),
new WordCountCombiner());
System.out.println(wordCounter.getCounter());
return wordCounter.getCounter();
}运行下看看结果,没有报错,但是运行结果竟然不是36 而是41!
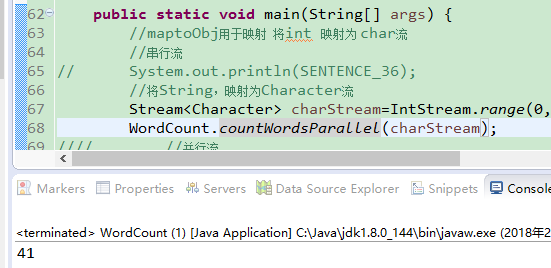
到底是哪里错了呢??? 我抓耳挠腮,也没有什么想法,仅能根据多年经验
当一个bug出现,而你有没有可行办法,不妨了解原理,进一步分析。
---温安适20180207
为了了解原理,我查看了大量网上文章,并行流的底层,fork/join框架,这个框架简单说就是:
一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
---温安适20180207
了解了原理后我怀疑到是拆分出来问题,但需要进一步获取细节,查看IntStream.range的源码,发现一个RangeIntSpliterator类,从名称上分析是Int类型范围分割器。
//IntStream 的range方法,也是生成流的入口
public static IntStream range(int startInclusive, int endExclusive) {
if (startInclusive >= endExclusive) {
return empty();
} else {
return StreamSupport.intStream(
new Streams.RangeIntSpliterator(startInclusive, endExclusive, false), false);
}
}
一路追溯 RangeIntSpliterator的父接口到java.util. Spliterator<T> ,这个接口的注释有如下:
An object for traversing and partitioning elements of a source. The source of elements covered by a Spliterator could be, for example, an array, a{@link Collection}, an IO channel, or a generator function.
A Spliterator may also partition off some of its elements (using {@link #trySplit}) as another Spliterator, to be used in possibly-parallel operations
这段注释的大概意思是:
Spliterator将源中元素进行转换和分区,源可以是数组,集合,IO channel,生成器等。
一个Spliterator 可以使用trySplit方法生成一个新的Spliterator,用于支持的并行操作。
看来,RangeIntSpliterator.trySplit就是我要找的分割任务的实现了,参阅其源码如下:
public Spliterator.OfInt trySplit() {
long size = estimateSize();
return size <= 1? null
// Left split always has a half-open range
: new RangeIntSpliterator(from, from = from + splitPoint(size), 0);
}
private int splitPoint(long size) {
int d = (size < BALANCED_SPLIT_THRESHOLD) ? 2 :
RIGHT_BALANCED_SPLIT_RATIO;
// Cast to int is safe since:
// 2 <= size < 2^32
// 2 <= d <= 8
return (int) (size / d);
}
简单说:
RangeIntSpliterator对拆分的数进行判断,小于2^24,进行折半查分,否则按1/8进行查分。
我们的SENTENCE_36.length 远小于2^24,进行了折半拆分。
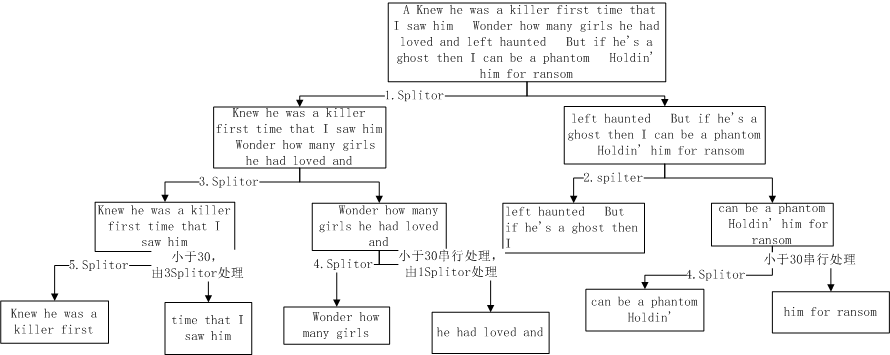
尝试模拟折半拆分的第一步,如下图,and拆分了成了2个词!即一个词被拆分为多个词了!

看来只能自己定义一个按空格拆分的Spliterator了。再写Spliterator之前,我对这个接口进行了进一步的了解。
Spliterator接口包含如下:4个核心方法
public interface Spliterator<T> {
//T 遍历的元素的类型
boolean tryAdvance(Consumer<? super T> action);
//类似Iterator ,如果还有元素返回true
Spliterator<T> trySplit();//因为它可以把一些元素划出去分给第二个 Spliterator
long estimateSize();//估计还剩下多少元素要遍历,约准确划分越均匀
int characteristics();//对接口的特性描述,详见表格1
}
表1characteristics说明
| 特性 | 含义 |
|---|---|
| ORDERED | 元素有既定的顺序(例如 List ), 因此 Spliterator 在遍历和划分时也会遵循这一顺序 |
| DISTINCT | 遍历的元素是去重的 |
| SORTED | 遍历的元素按照一个预定义的顺序排序 |
| SIZED | 该 Spliterator 由一个已知大小的源建立(例如 Set ), 因此 estimatedSize() 返回的是准确值 |
| NONNULL | 遍历的元素不能为null |
| IMMUTABLE | Spliterator 的数据源不能修改。 即遍历时不能添加、删除或修改任何元素 |
| CONCURRENT | 该 Spliterator 的数据源可以被其他线程同时 修改而无需同步 |
| SUBSIZED | 该 Spliterator 和所有从它拆分出来的 Spliterator 都是 SIZED |
也就是我需要,关注trySplit方法,我准备依据折半拆分,但是只有遇到空格才拆分,并且30个字符就不进行拆分了。trySplit方法中返回null,即代表不再拆分了。自定义的拆分器如下:
import java.util.Spliterator;
import java.util.function.Consumer;
/**
* 对字符进行分割的方式
*/
public class WorkCountSpliterator implements Spliterator<Character>{
private String needSpliterator;
private int currentCharAt;
public WorkCountSpliterator(String needSpliterator) {
super();
this.needSpliterator = needSpliterator;
}
@Override
public boolean tryAdvance(Consumer<? super Character> action) {
action.accept(needSpliterator.charAt(currentCharAt++));
return currentCharAt<needSpliterator.length();
}
@Override
public Spliterator<Character> trySplit() {
int remainSize=needSpliterator.length()-currentCharAt;
if(remainSize<30){//剩余字符串小于30,进行串行处理,不再生产子拆分器
return null;
}
for(int splitpos=currentCharAt+remainSize/2
;splitpos<needSpliterator.length()
;splitpos++){//采用折半搜索
if(Character.isWhitespace(needSpliterator.charAt(splitpos))){//如果是空格进行拆分
Spliterator<Character> subCountSpliterator=
new WorkCountSpliterator(needSpliterator.substring(currentCharAt,splitpos));
currentCharAt=splitpos;//向前推进缩小范围
System.out.println("拆分了:"+subCountSpliterator);
return subCountSpliterator;
}
}
return null;
}
@Override
public String toString() {
return "WorkCountSpliterator [needSpliterator="
+ needSpliterator + ", currentCharAt=" + currentCharAt + "]";
}
@Override
public long estimateSize() {
return needSpliterator.length()-currentCharAt;
}
@Override
public int characteristics() {
return ORDERED | SIZED | SUBSIZED | NONNULL | IMMUTABLE;
}
}按照上述代码,其拆分过程应该如下图
之后就是调用新写好的拆分器了,StreamSupport可以用自定义拆分器生成流,修改后的调用代码如下:
public static void main(String[] args) {
//并行流
WorkCountSpliterator spliter=new WorkCountSpliterator(SENTENCE_36);
Stream<Character> stream = StreamSupport.stream(spliter, true);
WordCount.countWordsParallel(stream);
}运行结果为36终于对了。不容易啊,又是看原理,又是看源码,还自己写了一个拆分器,终于搞定java8并行流的WordCount了,并不简单啊!

划重点:
- 内部迭代让你可以并行处理一个流,而无需在代码中显式使用和协调不同的线程
- 分支/合并框架让你得以用递归方式将可以并行的任务拆分成更小的任务,在不同的线程上执行,然后将各个子任务的结果合并起来生成整体结果。
- Spliterator 定义了并行流如何拆分它要遍历的数据
public interface Spliterator<T> {
//T 遍历的元素的类型
boolean tryAdvance(Consumer<? super T> action);
//类似Iterator ,如果还有元素返回true
Spliterator<T> trySplit();//因为它可以把一些元素划出去分给第二个 Spliterator
long estimateSize();//估计还剩下多少元素要遍历,约准确划分越均匀
int characteristics();//对接口的特性描述,详见表格1
}参考文献:
《java 8 in action》















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









