







Redis学习十一
Redis的主从同步和故障切换
Redis
的主从同步机制不仅可以让从库服务更多的读请求,分担主库的压力,而且还能在主库发生故障时,进行主从库切换,提供高可靠服务。不过,在实际使用主从机制的时候,我们很容易踩到一些坑。这节课,我就向你介绍
3 个坑,分别是主从数据不一致、读到过期数据,以及配置项设置得不合理从而导致服务挂掉。
主从数据不一致
主从一开始是进行的全员复制后面进行的是增量复制而且是异步进行的。,在主从库命令传播阶段,主库收到新的写命令后,会发送给从库。但是,主库并不会等到从库实际执行完命令后,再把结果返回给客户端,而是主库自己在本地执行完命令后,就会向客户端返回结果了。造成不一致的原因:一是主从库间的网络可能会有传输延迟,二是从库进行复杂的运算(集合操作)
解决方法
- 硬件环境配置方面,我们要尽量保证主从库间的网络连接状况良好。要避免把主从库部署在不同的机房,或者是避免把网络通信密集的应用(例如数据分析应用)和 Redis 主从库部署在一起。
- 开发一个外部程序来监控主从库间的复制进度。因为 Redis 的 INFO replication 命令可以查看主库接收写命令的进度信息(master_repl_offset)和从库复制写命令的进度信息(slave_repl_offset),所以,我们就可以开发一个监控程序,先用 INFO replication 命令查到主、从库的进度,然后,我们用 master_repl_offset 减去 slave_repl_offset,这样就能得到从库和主库间的复制进度差值了。超过进度差值不允许客服端在这个从库读取数据,如果从库的复制进度又赶上主库时,允许客户端再次跟这些从库连接。
读取过期数据
Redis 同时使用了两种策略来删除过期的数据,分别是惰性删除策略和定期删除策略。
惰性删除策略。当一个数据的过期时间到了以后,并不会立即删除数据,而是等到再有请求来读写这个数据时,对数据进行检查,如果发现数据已经过期了,再删除这个数据。
定期删除策略是指,Redis 每隔一段时间(默认 100ms),就会随机选出一定数量的数据,检查它们是否过期,并把其中过期的数据删除,这样就可以及时释放一些内存。
惰性删除实现后客服端从主库中读取过期的数据,此时数据才会被删除,但是,从库本身不会执行删除操作,如果客户端在从库中访问留存的过期数据,从库并不会触发数据删除。3.2版本后从库虽然不会删除数据但是过期了会直接返回空值但是如果主从设置的时间开始计算的节点不一样 还是会读到过期的数据。例如在主库设置60s过期但是由于网络延迟从库接受消息会进行延迟,导致了开始计算的时间节点不一样。
解决办法
将过期的时间设置为一个具体的时间
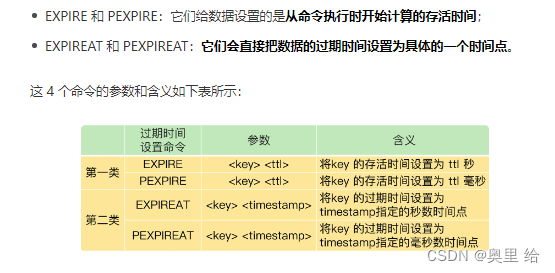
不合理从而导致服务挂掉
- protected-mode 配置项
这个配置项的作用是限定哨兵实例能否被其他服务器访问。
我们在应用主从集群时,要注意将 protected-mode 配置项设置为 no,并且将 bind 配置项设置为其它哨兵实例的 IP 地址。这样一来,只有在 bind 中设置了 IP 地址的哨兵,才可以访问当前实例,既保证了实例间能够通信进行主从切换,也保证了哨兵的安全性。
protected-mode no
bind 192.168.10.3 192.168.10.4 192.168.10.5
- cluster-node-timeout 配置项
这个配置项设置了 Redis Cluster 中实例响应心跳消息的超时时间。
当我们在 Redis Cluster 集群中为每个实例配置了“一主一从”模式时,如果主实例发生故障,从实例会切换为主实例,受网络延迟和切换操作执行的影响,切换时间可能较长,就会导致实例的心跳超时(超出 cluster-node-timeout)。实例超时后,就会被 Redis Cluster 判断为异常。而 Redis Cluster 正常运行的条件就是,有半数以上的实例都能正常运行。
避免脑裂
所谓的脑裂,就是指在主从集群中,同时有两个主节点,它们都能接收写请求。而脑裂最直接的影响,就是客户端不知道应该往哪个主节点写入数据,结果就是不同的客户端会往不同的主节点上写入数据。而且,严重的话,脑裂会进一步导致数据丢失。
为什么会发生脑裂?
在主从切换后的一段时间内,有一个客户端仍然在和原主库通信,并没有和升级的新主库进行交互。这就相当于主从集群中同时有了两个主库。
我们是采用哨兵机制进行主从切换的,当主从切换发生时,一定是有超过预设数量(quorum 配置项)的哨兵实例和主库的心跳都超时了,才会把主库判断为客观下线,然后,哨兵开始执行切换操作。哨兵切换完成后,客户端会和新主库进行通信,发送请求操作。但是,在切换过程中,既然客户端仍然和原主库通信,这就表明,原主库并没有真的发生故障(例如主库进程挂掉)。我们猜测,主库是由于某些原因无法处理请求,也没有响应哨兵的心跳,才被哨兵错误地判断为客观下线的。结果,在被判断下线之后,原主库又重新开始处理请求了,而此时,哨兵还没有完成主从切换,客户端仍然可以和原主库通信,客户端发送的写操作就会在原主库上写入数据了。
在主从切换的过程中,如果原主库只是“假故障”,它会触发哨兵启动主从切换,一旦等它从假故障中恢复后,又开始处理请求,这样一来,就会和新主库同时存在,形成脑裂。等到哨兵让原主库和新主库做全量同步后,原主库在切换期间保存的数据就丢失了。
解决办法
,Redis 已经提供了两个配置项来限制主库的请求处理,分别是 min-slaves-to-write 和 min-slaves-max-lag。
- min-slaves-to-write:这个配置项设置了主库能进行数据同步的最少从库数量;
- min-slaves-max-lag:这个配置项设置了主从库间进行数据复制时,从库给主库发送 ACK 消息的最大延迟(以秒为单位)。
我们可以把 min-slaves-to-write 和 min-slaves-max-lag 这两个配置项搭配起来使用,分别给它们设置一定的阈值,假设为 N 和 T。这两个配置项组合后的要求是,主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的请求了。即使原主库是假故障,它在假故障期间也无法响应哨兵心跳,也不能和从库进行同步,自然也就无法和从库进行 ACK 确认了。这样一来,min-slaves-to-write 和 min-slaves-max-lag 的组合要求就无法得到满足,原主库就会被限制接收客户端请求,客户端也就不能在原主库中写入新数据了。等到新主库上线时,就只有新主库能接收和处理客户端请求,此时,新写的数据会被直接写到新主库中。而原主库会被哨兵降为从库,即使它的数据被清空了,也不会有新数据丢失。
















 751
751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









