







强化学习原理入门-Day1
1、强化学习概念
强化学习是智能体(Agent)以“试错”的方式进行学习,通过与环境进行交互获得的奖励指导行为,目标是使智能体获得最大的奖励。学习者不被高数采取哪一个行动,而是必须通过尝试找出哪些行为能带来最大的回报。action不仅影响立即回报,而且还会影响下一个状态,以及所有后来的回报,这是强化学习两个最重要的区分特征。强化学习的基本思想是简单地捕捉agent所面临的真实问题的最重要方面,并随着时间的推移与环境交互以实现目标。agent必须能够在一定程度上感知其环境的状态,并且必须能够采取影响该状态的行动。

上图中,agent在进行某个任务时,首先与environment进行交互,产生新的state,同时给出reword,这样循环下去,agent和environment不断进行交互,产生新的数据,再利用新的数据去修改自身的action,经过多次迭代之后,agent会学习到完成任务的最优策略。
2、特点
没有教师信号,也没有label,只有reword。
反馈有延时,不是立即返回。
数据是序列化的,数据与数据之间是有关的。
agent执行的动作会影响之后的数据
3、马尔科夫决策过程
3.1、马尔科夫性
概念: 系统的下一个状态
s
t
+
1
s_{t+1}
st+1仅与当前状态
s
t
s_t
st有关,而与以前的状态无关。
定义: 状态
s
t
s_t
st是马尔科夫的,当且仅当
P
[
s
t
+
1
∣
s
t
]
=
P
[
s
t
+
1
∣
s
1
,
.
.
.
,
s
t
]
P[s_{t+1}|s_t] = P[s_{t+1}|s_1,...,s_t]
P[st+1∣st]=P[st+1∣s1,...,st]。
特点: 1)当前状态蕴含所有相关的历史信息。
2)一旦当前状态已知,历史信息将会被抛弃。
3.2、马尔科夫过程
马尔科夫过程就是一个二元组(S, P),且满足:S是有限状态集,P是状态转移概率。状态转移概率矩阵为: (3) P = [ P 11 . . . P 1 n . . . . . . . . . . P n 1 . . . P n n ] P = \left[ \begin{matrix} P_{11} & ... & P_{1n} \\ .... & ... & ... \\ P_{n1} & ... & P_{nn} \end{matrix} \right] \tag{3} P=⎣⎡P11....Pn1.........P1n...Pnn⎦⎤(3)
3.3、马尔科夫决策过程
马尔科夫决策过程由五元组
(
S
,
A
,
P
,
R
,
γ
)
(S,A,P,R,{\gamma})
(S,A,P,R,γ)描述,其中: S:States的集合,A:Action的聚合,
P
S
S
′
a
P_{SS^{'}}^{a}
PSS′a:状态转移概率,表示在状态s的情况下,执行动作a,然后转移到状态
s
′
s^{'}
s′的概率(马尔科夫决策过程是包含动作的),其中
P
S
S
′
a
=
P
[
S
t
+
1
=
s
′
∣
S
t
=
s
,
A
t
=
a
]
P_{SS^{'}}^{a} =P[S_{t+1} = s^{'}|S_t=s, A_t=a]
PSS′a=P[St+1=s′∣St=s,At=a],R:状态和动作到实数的映射,回报函数,
γ
{\gamma}
γ:折扣因子,可用来计算累计回报。
1)马尔科夫奖励过程:
与马尔科夫过程相比,马尔科夫奖励过程(MRP)多了一个奖励函数以及一个折扣因子。

马尔科夫奖励过程(MRP)状态转移图:

考虑到Class2这一状态时的状态转移概率矩阵:
| State | C 1 C_1 C1 | C 2 C_2 C2 | C 3 C_3 C3 | P a s s Pass Pass | P u b Pub Pub | F B FB FB | S l e e p Sleep Sleep |
|---|---|---|---|---|---|---|---|
| R e w a r d Reward Reward | -2 | -2 | -2 | 10 | 1 | -1 | 0 |
| C 1 C_1 C1 | 0.5 | 0.5 | |||||
| C 2 C_2 C2 | 0.8 | 0.2 | |||||
| C 3 C_3 C3 | 0.6 | 0.4 | |||||
| P a s s Pass Pass | 1 | ||||||
| P u b Pub Pub | 0.2 | 0.4 | 0.4 | ||||
| F B FB FB | 0.1 | 0.9 | |||||
| S l e e p Sleep Sleep | 1 |
马尔科夫决策过程(MDP):
用于描述强化学习的马尔科夫过程是五元组
M
=
<
S
,
A
,
P
,
R
,
γ
>
M=<S,A,P,R,{\gamma}>
M=<S,A,P,R,γ>,强化学习的目标是给定一个马尔科夫决策过程,寻找最优策略。策略是状态到动作的映射,其表达式为:
π
(
a
∣
s
)
=
p
[
A
t
=
a
∣
S
t
=
s
]
\pi(a|s)=p[A_t=a|S_t=s]
π(a∣s)=p[At=a∣St=s],策略
π
\pi
π在每个状态s指定一个确定的动作。
当给定一个策略
π
\pi
π时,即可计算长期回报:
G
t
=
R
t
+
1
+
γ
R
t
+
2
+
.
.
.
=
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
G_t=R_{t+1} + \gamma R_{t+2}+...=\sum_{k=0}^{\infty}\gamma^kR_{t+k+1}
Gt=Rt+1+γRt+2+...=∑k=0∞γkRt+k+1(各个step的即时奖励的折后和),由于策略
π
\pi
π是随机的,因此长期回报也是随机的。为了评价状态
s
1
s_1
s1的价值,很自然的想到用长期回报来衡量,但是长期回报是一个随机值,无法描述,所以通过其期望作为状态值函数的定义。
计算一下长期回报,
S
1
S_1
S1从
C
1
C_1
C1开始,到Sleep结束,折扣因子
γ
=
1
2
\gamma=\frac{1}{2}
γ=21。
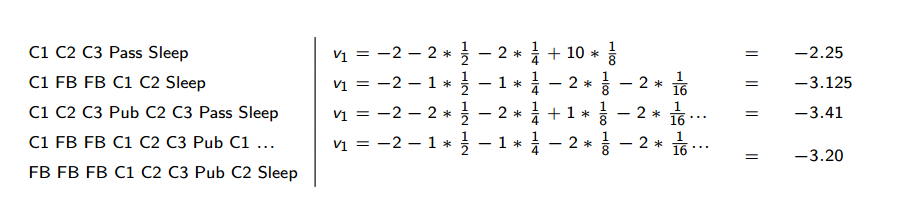
1)状态值函数: 状态值函数就是累计回报
G
t
G_t
Gt的期望:
v
π
(
s
)
=
E
π
[
G
t
∣
S
t
=
s
]
v_\pi(s)=E_\pi[G_t|S_t=s]
vπ(s)=Eπ[Gt∣St=s](状态值函数是与策略向对应的,策略
π
\pi
π决定了累计回报G的状态分布)
2)状态行为值函数: Agent从状态s出发,采取a行动之后,获得的长期回报的期望。(这个action不一定是依据
π
\pi
π产生的。)
q
π
(
s
,
a
)
=
E
π
[
∑
k
=
0
∞
γ
k
R
t
+
k
+
1
∣
S
t
=
s
,
A
t
=
a
]
q_\pi(s,a)=E_\pi[\sum_{k=0}^{\infty}\gamma^kR_{t+k+1|S_t=s,A_t=a}]
qπ(s,a)=Eπ[∑k=0∞γkRt+k+1∣St=s,At=a](仍然是累计回报的期望,但但是已知条件是s和a)
3)Bellman方程: 基本思想是对值函数进行递归分解。
状态值函数与状态行为值函数的贝尔曼方程:

状态值函数与状态动作值函数的贝尔曼方程:
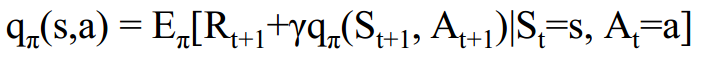














 4235
4235











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









