










提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文
前言
离线数仓一般情况下都是通过写hive sql方式,利用调度系统再hive sql脚本,进行数仓分层,而调度系统是针对任务粒度的,而且一般都不支持发送到企业微信,针对这一痛点,本文利用hivehook 监听hive sql,将hive sql 的错误信息发送到kafka,另外python 程序实时kafka的数据,并发送到企业微信。
流程图如下:
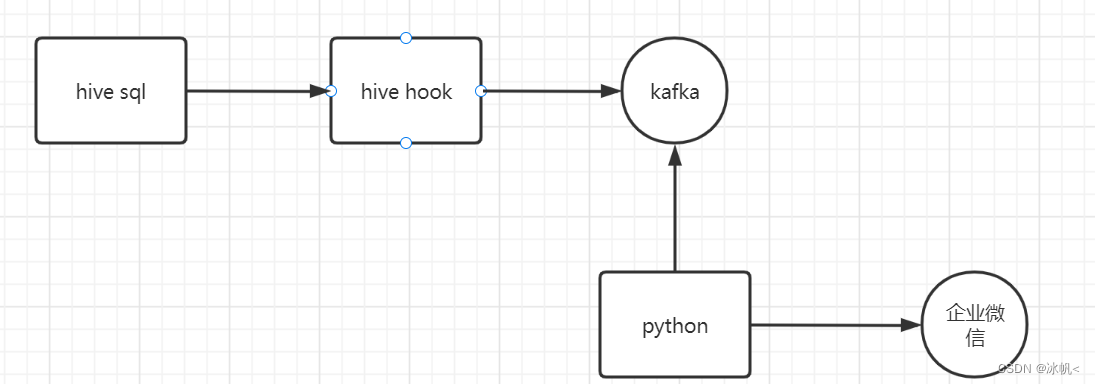
一、环境准备
本文需要的环境hadoop:2.5.0-cdh5.3.0部署详见:hadoop集群搭建教程_冰帆<的博客-CSDN博客_api.twitter.com
apache hive: 1.2.2
apache kafka:2.7.0
二、hive hooks介绍
Hook是一种在处理过程中拦截事件,消息或函数调用的机制。 Hive hooks是绑定到了Hive内部的工作机制,提供了使用hive扩展和集成外部功能的能力。可用于在hive查询处理的各个步骤中运行/注入一些代码。
1.钩子函数的类型
根据钩子函数的类型,在查询处理期间的不同节点调用:
- Pre-execution hooks--在执行引擎执行查询之前,将调用Pre-execution hooks。这个目的是此时已经为Hive准备了一个优化的查询计划。
- Post-execution hooks --在查询执行完成之后以及将结果返回给用户之前,将调用Post-execution hooks 。
- Failure-execution hooks --当查询执行失败时,将调用Failure-execution hooks ,本文主要针对该钩子函数介绍,其他钩子函数的使用类似。
- Pre-driver-run 和post-driver-run hooks--在driver执行查询之前和之后调用Pre-driver-run 和post-driver-run hooks。
- Pre-semantic-analyzer 和 Post-semantic-analyzer hooks--在Hive在查询字符串上运行语义分析器之前和之后调用Pre-semantic-analyzer 和Post-semantic-analyzer hooks。
2. Hive Hook API
Hook接口是Hive中所有Hook的父接口。它是一个空接口,并通过以下特定hook的接口进行了扩展:
- PreExecute和PostExecute将Hook接口扩展到Pre和Post执行hook。
- ExecuteWithHookContext扩展Hook接口以将HookContext传递给hook。HookContext包含了hook可以使用的所有信息。 HookContext被传递给名称中包含“WithContext”的所有钩子。
- HiveDriverRunHook扩展了Hook接口,在driver阶段运行,允许在Hive中自定义逻辑处理命令。
- HiveSemanticAnalyzerHook扩展了Hook接口,允许插入自定义逻辑以进行查询的语义分析。它具有preAnalyze()和postAnalyze()方法,这些方法在Hive执行自己的语义分析之前和之后执行。
- HiveSessionHook扩展了Hook接口以提供会话级hook。在启动新会话时调用hook。用hive.server2.session.hook配置它。
- Hive 1.1添加了Query Redactor Hooks。它是一个抽象类,它实现了Hook接口,可以在将查询放入job.xml之前删除有关查询的敏感信息。可以通过设置hive.exec.query.redactor.hooks属性来配置此hook。
三、使用hooks
1.引入hive-exec库
代码如下(示例):
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hive.version>1.2.2</hive.version>
<java.version>1.8</java.version>
<hadoop.version>2.5.0</hadoop.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<log4j.version>2.12.1</log4j.version>
<kafka.version>2.7.0</kafka.version>
</properties>
<dependencies>
<!--添加Hadoop的依赖-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>javax.servlet</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
</dependencies>2.封装kafka生成者
封装kafka生产者,方便在hivehook中使用。
代码如下(示例):
package com.hive.util;
/**
* @ClassName: HiveKafkaUtils
* @projectName hiveHook
* @description: TODO
* @author ice_boat
* @date 2022/8/117:15
* @version 1.0
*/
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.*;
import java.sql.SQLException;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
*@ClassName com.hive.util.HiveKafkaUtils
*@Description TODO
*@Author ice_boat
*@Date 2022/8/1 17:15
*@version 1.0
*/
public class HiveKafkaUtils {
private static final Log LOG = LogFactory.getLog(HiveKafkaUtils.class);
public static void main(String[] args) {
kafkaProducer("HIVE_HOOK", "hello");
}
public static void kafkaProducer(String topicName,String value) {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka1:9092,kafka2:9092,kafka3:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
properties.put(ProducerConfig.RETRIES_CONFIG, 0);
properties.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// KafkaProducer 是线程安全的,可以多个线程使用用一个 KafkaProducer
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);
ProducerRecord<String, String> record = new ProducerRecord<>(topicName, value);
kafkaProducer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null) {
LOG.error(String.format("发送数据到kafka发生异常: %s",e));
return;
}
LOG.info("发送数据到kafka成功, topic: " + metadata.topic() + " offset: " + metadata.offset() + " partition: "
+ metadata.partition());
LOG.info("从kafka获取数据topic数据: " + metadata.topic());
kafkaConsumer(metadata.topic());
}
});
kafkaProducer.close();
}
public static void kafkaConsumer(String topicName) {
Properties props = new Properties();
// 必须指定
props.put("bootstrap.servers", "kafka1:9092,kafka2:9092,kafka3:9092");
// 必须指定
props.put("group.id", "hivehook");
// 必须指定
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 必须指定
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 从最早的消息开始读取
props.put("auto.offset.reset", "earliest");
props.put("enable.auto.commit", "true");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topicName));
try {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(2));
for (ConsumerRecord<String, String> record : records) {
LOG.info("KafkaConsumer获取"+topicName+"信息value=" +record.value());
if(!DBMySqlUtils.testColletHiveMeta(record.value())) {
LOG.info("KafkaConsumer获取"+topicName+"信息,插入mysql库失败");
}
}
} catch (ClassNotFoundException e) {
LOG.error(String.format("kafkaConsumer调用DbUtil报错: %s", e));
} catch (SQLException e) {
LOG.error(String.format("kafkaConsumer调用DbUtil报错: %s", e));
} finally {
consumer.close();
}
}
}
3.封装HookUtils
封装hookUtils便于计算空间容量。
代码如下(示例):
package com.hive.util;
/**
* @ClassName: HookUtils
* @projectName hiveHook
* @description: TODO
* @author ice_boat
* @date 2022/8/113:42
* @version 1.0
*/
import org.apache.hadoop.hive.metastore.api.MetaException;
import java.util.*;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hive.common.FileUtils;
import java.io.IOException;
/**
*@ClassName com.hive.util.HookUtils
*@Description TODO
*@Author ice_boat
*@Date 2022/8/1 13:42
*@version 1.0
*/
public class HookUtils {
public static Configuration getHdfsConfig(int flag){
Configuration conf = new Configuration();
conf.set("hbase.zookeeper.quorum", "zk1:2181,zk2:2181,zk3:2181");
conf.set("fs.defaultFS", "hdfs://hdfs-nn/");
return conf;
}
public static long getTotalSize(String pathString) throws IOException {
FileSystem hdfs = FileSystem.get(HookUtils.getHdfsConfig(0));
Path fpath = new Path(pathString);
FileStatus[] fileStatuses = hdfs.listStatus(fpath);
Path[] listPath = FileUtil.stat2Paths(fileStatuses);
long totalSize=0L;
for (Path eachpath:listPath) {
totalSize = totalSize+hdfs.getContentSummary(eachpath).getLength();
}
return totalSize;
}
public static long getListPathSize(ArrayList<String> inputList){
long totalSize=0L;
for (String eachPath:inputList) {
try {
totalSize = totalSize+getTotalSize(eachPath);
} catch (IOException e) {
e.printStackTrace();
}
}
return totalSize;
}
public static String getValueName(Map<String, String> spec, boolean addTrailingSeperator) throws MetaException {
StringBuilder suffixBuf = new StringBuilder();
int i = 0;
Map<String, String> resultMap = new HashMap<>();
if (spec == null || spec.isEmpty()) {
}
Set<String> keySet = spec.keySet();
for (String key : keySet) {
String newKey = key;
System.out.println("key:"+newKey);
System.out.println("value:"+spec.get(key));
}
for(Iterator var4 = spec.entrySet().iterator(); var4.hasNext(); ++i) {
Map.Entry<String, String> e = (Map.Entry)var4.next();
if (e.getValue() == null || ((String)e.getValue()).length() == 0) {
throw new MetaException("Partition spec is incorrect. " + spec);
}
System.out.println(suffixBuf);
if (i > 0) {
suffixBuf.append("/");
}
suffixBuf.append(escapePathName((String) e.getKey()));
suffixBuf.append("=");
suffixBuf.append(escapePathName((String)e.getValue()));
}
if (addTrailingSeperator) {
suffixBuf.append("/");
}
return suffixBuf.toString();
}
static String escapePathName(String path) {
return FileUtils.escapePathName(path);
}
public static void main(String[] args) throws MetaException {
Map<String,String> map = new HashMap<>();
map.put("","{date=2022-07-31}");
getValueName(map,false);
}
}
4.实现ExecuteWithHookContext钩子函数
实现钩子函数,并封装异常信息,发送到kafka。该钩子函数在hive-site.xml中注册。
代码如下(示例):
package com.hive.hooks;
/**
* @ClassName: getQueryHook
* @projectName hiveHook
* @description: TODO
* @author ice_boat
* @date 2022/8/111:58
* @version 1.0
*/
import com.hive.util.HiveKafkaUtils;
import com.hive.util.HookUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hive.metastore.api.StorageDescriptor;
import org.apache.hadoop.hive.ql.QueryPlan;
import org.apache.hadoop.hive.ql.hooks.*;
import org.apache.hadoop.hive.ql.plan.HiveOperation;
import org.codehaus.jackson.map.ObjectMapper;
import java.text.SimpleDateFormat;
import java.util.*;
/**
*@ClassName com.hive.hooks.HiveGetQueryHook
*@Description TODO
*@Author ice_boat
*@Date 2022/8/1 11:58
*@version 1.0
*/
public class HiveGetQueryHook implements ExecuteWithHookContext {
private static final Log LOG = LogFactory.getLog(HiveGetQueryHook.class);
private static final HashSet<String> OPERATION_NAMES = new HashSet<>();
static {
// 建表
OPERATION_NAMES.add(HiveOperation.CREATETABLE.getOperationName());
// 修改数据库属性
OPERATION_NAMES.add(HiveOperation.ALTERDATABASE.getOperationName());
// 修改数据库属主
OPERATION_NAMES.add(HiveOperation.ALTERDATABASE_OWNER.getOperationName());
// 修改表属性,添加列
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_ADDCOLS.getOperationName());
// 修改表属性,表存储路径
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_LOCATION.getOperationName());
// 修改表属性
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_PROPERTIES.getOperationName());
// 表重命名
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_RENAME.getOperationName());
// 列重命名
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_RENAMECOL.getOperationName());
// 更新列,先删除当前的列,然后加入新的列
OPERATION_NAMES.add(HiveOperation.ALTERTABLE_REPLACECOLS.getOperationName());
// 创建数据库
OPERATION_NAMES.add(HiveOperation.CREATEDATABASE.getOperationName());
// 删除数据库
OPERATION_NAMES.add(HiveOperation.DROPDATABASE.getOperationName());
// 删除表
OPERATION_NAMES.add(HiveOperation.DROPTABLE.getOperationName());
//查询
OPERATION_NAMES.add(HiveOperation.QUERY.getOperationName());
}
@Override
public void run(HookContext hookContext) throws Exception {
HashMap<String, Object> hiveSqlParseValue = new HashMap<>();
QueryPlan plan = hookContext.getQueryPlan();
ObjectMapper mapper = new ObjectMapper();
String operationName = plan.getOperationName();
//System.out.println("Query executed: " + plan.getQueryString());
hiveSqlParseValue.put("operation",operationName);//获取当前操作
hiveSqlParseValue.put("user",hookContext.getUserName());
Long timeStamp = System.currentTimeMillis(); //获取当前时间戳
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String sd = sdf.format(new Date(Long.parseLong(String.valueOf(timeStamp))));
hiveSqlParseValue.put("time",sd);
hiveSqlParseValue.put("sql",plan.getQueryString());//当前查询sql
hiveSqlParseValue.put("hookType",hookContext.getHookType());
hiveSqlParseValue.put("queryId",plan.getQueryId());
hiveSqlParseValue.put("userName",hookContext.getUserName());
hiveSqlParseValue.put("ipAddress",hookContext.getIpAddress());
ArrayList<String> inputTableList = new ArrayList<>();
ArrayList<String> outputTableList = new ArrayList<>();
ArrayList<String> inputPutList = new ArrayList<>();
ArrayList<String> inputPutPartitionList = new ArrayList<>();
ArrayList<String> outputPutList = new ArrayList<>();
ArrayList<String> outputPartitionList = new ArrayList<>();
HashSet<String> ownerSet = new HashSet<>();
int isInputPartition=-1;
int isOutputPartition=-1;
if (OPERATION_NAMES.contains(operationName) && !plan.isExplain()) {
LOG.info("监控sql操作");
Set<ReadEntity> inputs = hookContext.getInputs();
if (inputs != null) {
for (Entity entity : inputs) {
switch (entity.getType()) {
//无分区
case TABLE:
isInputPartition =0;
inputTableList.add(entity.getTable().getTTable().getTableName());
inputPutList.add(mapper.writeValueAsString(entity.getTable().getTTable().getSd().getFieldValue(StorageDescriptor._Fields.LOCATION)).replace("\"",""));
ownerSet.add(entity.getTable().getTTable().getOwner());
LOG.info(entity.getTable().getTTable());
break;
//有分区
case PARTITION:
if (null != entity.getP()){
isInputPartition=1;
String partitionName = HookUtils.getValueName(entity.getP().getSpec(), false);
String influxPath = mapper.writeValueAsString(entity.getTable().getTTable().getSd().getFieldValue(StorageDescriptor._Fields.LOCATION)).replace("\"","");
LOG.info(entity.getTable().getTTable());
inputPutPartitionList.add(influxPath+"/"+partitionName);
}
break;
default :
break;
}
}
}
Set<WriteEntity> outputs = hookContext.getOutputs();
if (outputs != null) {
for (Entity entity : outputs) {
switch (entity.getType()) {
case TABLE:
isOutputPartition =0;
outputTableList.add(entity.getTable().getTTable().getTableName());
outputPutList.add(mapper.writeValueAsString(entity.getTable().getTTable().getSd().getFieldValue(StorageDescriptor._Fields.LOCATION)).replace("\"", ""));
ownerSet.add(entity.getTable().getTTable().getOwner());
LOG.info(entity.getTable().getTTable());
break;
case PARTITION:
if (null != entity.getP()) {
isOutputPartition = 1;
String partitionName = HookUtils.getValueName(entity.getP().getSpec(), false);
String influxPath = mapper.writeValueAsString(entity.getTable().getTTable().getSd().getFieldValue(StorageDescriptor._Fields.LOCATION)).replace("\"", "");
outputPartitionList.add(influxPath + "/" + partitionName);
LOG.info(entity.getTable().getTTable());
}
break;
default:
break;
}
}
}
}
hiveSqlParseValue.put("inputTableList",inputTableList);
hiveSqlParseValue.put("outputTableList",outputTableList);
if (isInputPartition==0){
hiveSqlParseValue.put("inputPaths",inputPutList);
hiveSqlParseValue.put("totalInputSize",HookUtils.getListPathSize(inputPutList));
}else{
hiveSqlParseValue.put("inputPaths",inputPutPartitionList);
hiveSqlParseValue.put("totalInputSize",HookUtils.getListPathSize(inputPutPartitionList));
}
if (isOutputPartition==0){
hiveSqlParseValue.put("outputPaths",outputPutList);
hiveSqlParseValue.put("totalOutputSize",HookUtils.getListPathSize(outputPutList));
}else{
hiveSqlParseValue.put("outputPaths",outputPartitionList);
hiveSqlParseValue.put("totalOutputSize",HookUtils.getListPathSize(outputPartitionList));
}
hiveSqlParseValue.put("app.owner",ownerSet);
String resultJson = mapper.writeValueAsString(hiveSqlParseValue);
HiveKafkaUtils.kafkaProducer("HIVE_HOOK", resultJson);
System.out.println(resultJson);
LOG.info(resultJson);
}
}
4.打包jar
使用maven 打包jar,项目与jar 都可以自定义,比如:hive_hook。
5.hive配置
- copy hive_hook.jar 到hive 的安装目录的lib下
- hive-site.xml 添加
<property>
<name>hive.exec.failure.hooks</name>
<value>com.hive.hooks.HiveGetQueryHook</value>
</property>- 重启hiveserver2
-
nohup hive --service hiveserver2 >> ~/hiveserver2.log 2>&1 &
四、企业微信申请webhook
在此不做详述,详见:监控RocketMQ消费数据延迟告警发送企业微信_冰帆<的博客-CSDN博客
五、python 程序消费kafka 并发送到企业微信
数据已经发送到kafka,写一个python程序循环消费kafka并发送到企业微信webhook地址
代码如下(示例):
# -*- coding: utf-8 -*-
from kafka import KafkaProducer, KafkaConsumer
import requests
import time
import json
class KafkaClient():
topic = "HIVE_HOOK" # 使用的kafka的topic
client = ["kafka1:9092", "kafka2:9092", "kafka3:9092"] # kafka所在的服务地址
group_id = "consumer_group_test" # kafka组信息
@staticmethod
def log(log_str):
t = time.strftime(r"%Y-%m-%d_%H:%M:%S", time.localtime())
print("[%s]%s" % (t, log_str))
def get_now_time(self):
"""
获取当前日期时间
:return:当前日期时间
"""
now = time.localtime()
now_time = time.strftime("%Y-%m-%d %H:%M:%S", now)
# now_time = time.strftime("%Y-%m-%d ", now)
return now_time
def info_send(self, key, info_str):
"""key: 发送信息的key;info_str:要发送的信息内容"""
producer = KafkaProducer(bootstrap_servers=self.client)
producer.send(self.topic, key=key.encode("utf-8"), value=info_str.encode("utf-8"))
# 批量提交可以使用 producer.flush()
producer.close()
def consume_msg(self, consumer_obj):
"""
逐条消费,返回反序列化后的内容
:param consumer_obj:
:return:
"""
try:
while True:
msg = next(consumer_obj, None)
if not msg:
continue
content = msg.value
return content
except Exception as ex:
print("消费kafka错误,退出测试")
return None
def message_consumer(self):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'cache-control': 'no-cache',
'content-type': 'application/json',
}
# consumer_timeout_ms:超时时间(毫秒),超过指定时间没有获取到消息关闭kafka
try:
consumer = KafkaConsumer(self.topic,
group_id=self.group_id,
bootstrap_servers=self.client,
auto_offset_reset="earliest",
consumer_timeout_ms=3000)
except Exception as ex:
print("连接kafka失败!")
while 1 == 1:
# print("开始消费第%s条数据..." % str(i + 1))
content = next(consumer, None)
'''
print("message:"+str(content))
'''
# content= {"totalOutputSize":0,"totalInputSize":11713006388,"outputTableList":[],"ipAddress":null,"userName":null,"outputPaths":[],"sql":"select * from machine_log where date = '2022-08-01' and machine_no ='7090937250498117426' limit 10","queryId":"hadoop_20220802175439_db170880-f66b-421f-8483-24b21f26281c","inputPaths":["hdfs://hdfs-nn/hive/warehouse/machine_log/date=2022-08-01"],"inputTableList":["machine_log"],"app.owner":["hadoop"],"time":"2022-08-02 17:54:39","operation":"QUERY","user":null,"hookType":"PRE_EXEC_HOOK"}
# dict转json保存数据内容
if not content:
print("message:" + str(content))
time.sleep(3)
else:
# print("message:"+str(content))
print(type(content))
print(content.topic)
print(bytes.decode(content.value))
jobj = json.loads(bytes.decode(content.value))
jAlert = "**告警通知:[" + str(1) + "]** \n"
upload_time = self.get_now_time()
jAlert = jAlert + ">问题名称:**<font color=\"warning\">" + "Hive脚本失败" + "</font>**\n" \
+ ">告警来源:<font color=\"comment\">" + "hive" + "</font>\n" \
+ ">告警时间:<font color=\"comment\">" + str(upload_time) + "</font>\n" \
+ ">问题详情:<font color=\"comment\">" + str(jobj['sql']) + ",失败" + "</font>\n" \
+ ">问题描述:<font color=\"comment\">" + str(jobj['queryId']) + "</font>\n" \
+ ">目前状态:<font color=\"comment\">" + "firing" + "</font>\n" \
+ ">告警级别:<font color=\"comment\">" + "critical" + "</font>\n" \
+ "————————————————\n"
if len(jAlert) > 0:
data = {}
markdown = {}
markdown['content'] = jAlert
data['msgtype'] = 'markdown'
data['markdown'] = markdown
jdata = json.dumps(data, sort_keys=False, indent=4, separators=(',', ': '))
response = requests.post(
'https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=*****',
headers=headers, data=jdata)
print('response:' + response.text)
response.close()
if __name__ == '__main__':
kafka = KafkaClient()
kafka.message_consumer()
启动python程序,如果有hive sql 执行失败的错误信息,则企业微信就会收到。
我们看下结果:

总结
本文利用hivehooks机制,通过实现钩子函数,将错误信息发送到kafka,并实现自动告警,本文只是抱砖引玉,通过该方案可以实现很多有趣的告警功能。更多精彩,待你发掘:

















 1492
1492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











