







Note:本篇博文1,2部分主要是对书籍Pattern Recognition and Mechine Learning 第九章9.2节的翻译
高斯混合模型
高斯混合模型是几个高斯成分的简单线性叠加,可以提供比单高斯更加丰富的密度模型。
高斯模型的形式:
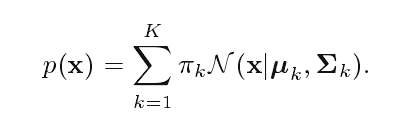
这就表示此模型是由K个高斯分布线性叠加而成。
高斯混合模型公式的推导
引入一个K维的二进制随机变量z,其中只有一个元素 zk 为1,其他元素都为0。因此 zk 的值满足 zk∈0,1 并且 ∑kzk=1 。通过哪个元素不为0,可以看出向量z有K种可能的状态。
πk 必须满足
因为z是1-K维的表示,所以其分布可以写为
同样的,在确定了z后x的条件概率是一个高斯分布
也可以写成:
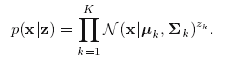
由此得
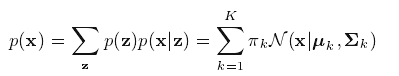
后验概率
另外一个具有重要作用的度量是x确定时z的条件概率。我们可以使用
γ(zk)
来表示
p(zk=1|x)
,其值可以用贝叶斯公式求得
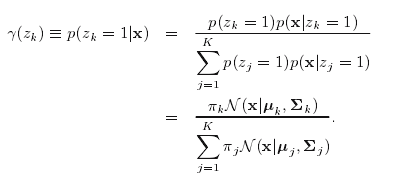
我们可以把
π
看作
zk=1
的先验概率,
γ(zk)
看作已知x时的后验概率。
最大似然
假定一观测样本集
x1,...,xN
,我们希望用一个高斯混合模型来描述。我们用一个N*D的矩阵X来表示这个数据集,X的第n行为
xTn
。同样地,相应的隐含变量可以用N*K的矩阵Z表示,每一行是
zTn
。假定每个样本点是从概率分布中独立地抽取出来的,那么对数似然函数可以表示为
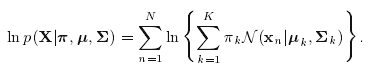
高斯分布的EM算法
更新参数
对上面的对数似然函数关于
μk
求偏导使之等于0,我们得到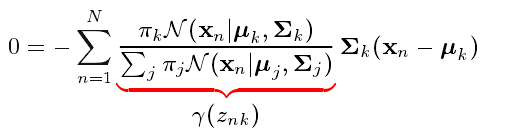
两侧乘
∑k
得到
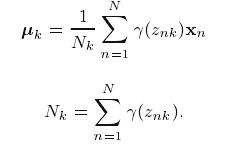
对数似然函数关于
∑k
求导可得
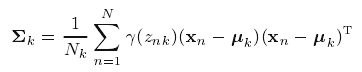
最后,我们关于混合系数
πk
来最大化
lnp(X|π,μ,∑)
。考虑到约束条件
∑z=1
引入一个拉格朗日乘子:
对
πk
求导得到
最终得到(这里我推导不出来)
算法步骤
给一个高斯混合模型,我们的目标是最大化与参数(高斯成分的均值,协方差和混合系数)相关的对数似然函数。
1 Initialization
舒适化均值 μk ,协方差矩阵 ∑k 和混合系数 πk ,并且估计对数似然函数(log likelihood)的初始值。
2 E step
利用当前参数计算
3 M step
重新估计参数
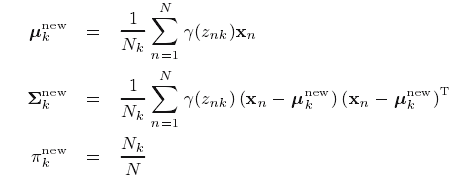
其中:
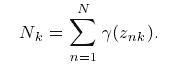
4 计算log likelihood
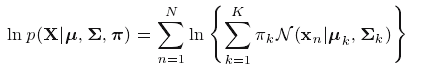
检查参数或者对数似然函数的收敛性。如果不满足收敛准则,返回第二步。














 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









