






大家好,我是阿潘,今年堪称视频生成的爆发的一年,sora 2024年2月15日发布,让全世界都震惊了。openai 有一次成为了行业标杆。从生成的效果来看,比起以往抽象的生成结果,有了巨大的提升。
今天和大家分享中科大和字节跳动的工作 CamTrol 。这是一种train-free,可以在大多数预训练的视频扩散模型中即插即用的方案。支持单张图片或文本prompt作为输入生成视频。
论文:https://arxiv.org/pdf/2406.10126
主页:https://lifedecoder.github.io/CamTrol/
1、原理介绍
虽然视频生成模型在生成具有高度动态对象和背景的视频方面取得了进展,但大多数模型无法为生成的视频提供相机控制。
视频中摄像机轨迹控制的难度主要来自两个方面
1、大多数视频标注缺乏描述,尤其是对视频摄像机运动的精确描述。无法将prompt与相机运动相关的并生成正确的输出。缓解数据不足问题的一种解决方案是通过简单的数据增强来模仿带有摄像机移动的视频,然而只能处理简单的相机运动,例如缩放和移动,无法处理复杂的情况。
2、控制相机运动所需的额外微调。由于相机轨迹可能很复杂,因此有时无法仅使用简单的文本提示来准确地阐述它们。常见的解决方案提出通过可学习编码器将相机参数嵌入到扩散模型中,并对具有详细相机轨迹的大规模数据集进行广泛的微调。
作者两个核心观察:
1、通过将特定的与相机相关的文本集成到输入prompt中,例如相机放大或相机向右平移,基本视频模型可以通过粗略的相机移动产生结果。这种简单的实现虽然不是很准确并且总是导致静态或错误的运动,但显示了预训练模型学习到的关于遵循不同相机轨迹的自然先验知识。
2、另一个观察结果是视频模型在适应 3D 生成任务方面表现出的有效性。最近的工作发现,利用预训练的视频模型作为初始化有助于极大地提高多视图生成的性能,展示了它们处理视角变化的强大能力。l
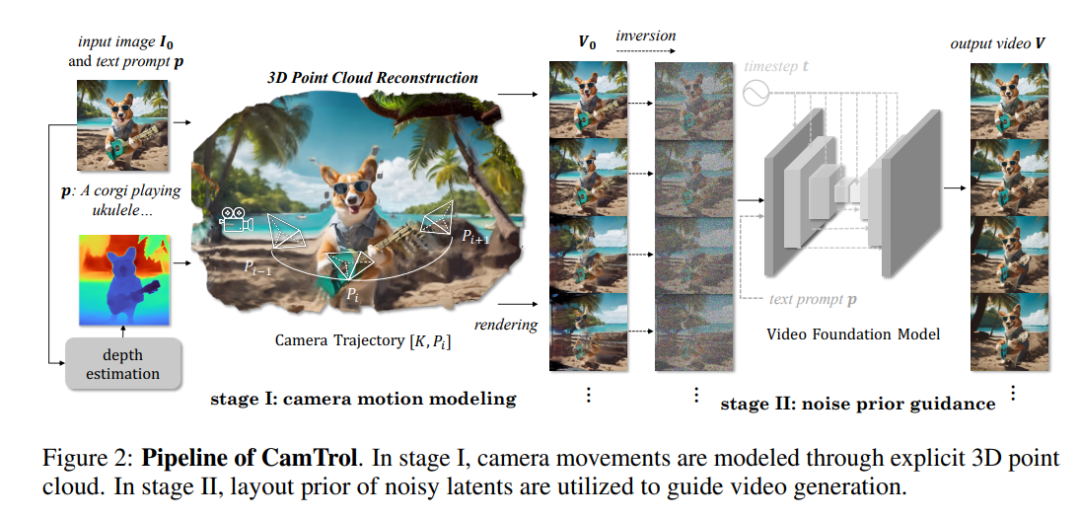
作者提出了 CamTrol,以train-free但稳健的方式为现成的视频扩散模型提供相机控制。CamTrol 的灵感来自于 noise latent 对生成结果的先验布局:当 noise latent 中的像素改变其位置时,输出也会发生相应的重新排列,并导致布局修改。考虑到摄像机移动也可以被视为一种布局重新排列,该先验可以作为为视频模型提供特定摄像机运动信息的有效prompt。具体来说,CamTrol 由两个阶段步骤组成。在第一阶段,显式摄像机运动以 3D 点云表示形式建模,并生成一系列指示特定摄像机运动的渲染图像。在第二阶段,利用 noise latent 的先验布局来指导摄像机移动的视频生成。
2、具体步骤

图1
CamTrol 需要两个阶段来激发隐藏在基本视频模型中的固有摄像机控制能力。
1)如何在点云空间中对显式相机运动进行建模。
2)在噪声布局优先指导下的摄像机可控视频生成。
1)Camera Motion Modeling
为了激发预训练的视频扩散模型处理摄像机视角变化的能力,应以适当的方式将摄像机运动的提示注入扩散模型。
考虑到视频的视角变化最初是由 3D 空间中的摄像机运动引起的,作者采用 3D 表示来为视频扩散模型提供明确的运动prompt。具体来说,选择点云作为中间表示,在该空间中可以方便地操纵相机的姿势和位置来模拟不同的相机运动。除了显式的相机建模之外,引入点云还带来了额外的好处:首先是它的数据效率。通过利用修复技术,整个点云重建只需要一张输入图像,这回避了大规模微调的工作。其次,可以轻松确保多视图渲染之间的一致性,因为重建完成后已知点将保持不变
Point Cloud Initialization 首先将输入图像平面中的像素提升为 3D 点云表示。输入图像可以是用户定义的,也可以由图像生成器(如stable diffusion)创建。给定输入图像,使用现成的单目深度估计器 ZeoDepth 估计其深度图 。
Camera Trajectories 为了从多个视角获得一致的图像,将相机运动设置为外在矩阵{P1,...,PN−1}的预定义轨迹,每个轨迹都包含代表相机姿态和位置的旋转矩阵和平移矩阵。在每一步 i,我们使用函数 ψ 将点云投影回相机平面,并获得具有透视变化的渲染图像:Ii = ψ(Pi , K, Pi)。通过计算相应运动的外在矩阵,获取变焦、俯仰、平移、升降、横滚、横滚、旋转等一系列摄像机运动,实现灵活的摄像机运动。通过组合基本轨迹,可以实现混合摄像机运动并制作具有电影魅力的视频。此外,受益于显式相机运动建模,我们的方法可以支持具有精确坐标的轨迹,这意味着它可以生成具有任何复杂相机运动的视频(图1)。
Multi-view Rendering 当视角改变时,可能会出现空位,因为点云中的某些区域未被占据。为了获得更合理的结果,采用图像修复模型来填补新渲染的漏洞,并使用掩模区分已知点和不存在的点。在2D空间修复后,图像再次提升到3D空间,逐步完成整个点云的表示。在此过程中,由于深度估计器仅估计相对深度,因此相邻视图之间可能会发生未对准,进一步导致渲染图像的不一致。
2)Layout Prior of Noise
通过相机运动建模,我们获得了遵循特定相机轨迹的渲染图像序列 V0 = [I0, ..., IN−1] ∈ R N×3×H×W。请注意,渲染图像的质量并不完美,因为单个输入图像仅导致稀疏点云重建,此外,这些渲染是静态的,因此它们不能直接用作视频帧。为了形成理想的视频,需要找到一种满足以下三个要求的方法:1)保持相机运动;2)鼓励视频更加动态;3)质量缺陷应予以补偿。
Camera Motion Inversion 最近关于扩散模型的工作已经证明了其noise latent的强大可控性,它们对最终输出的因果关系和错误恢复能力使它们成为可控生成扩散模型的便捷而强大的工具。特别是对于初始噪声,即使是从高斯分布采样,它仍然对生成图像的布局有显着影响,因此重新排列噪声像素也会使输出中的内容重新定位。例如,如果初始噪声中的所有像素向右移动一定距离,则生成的输出很可能反映类似的移动。这提醒我们,相机运动对图像的影响也可以被视为一种布局重新排列,即像素因视点变化而改变其位置。以类似的方式,如果视频的潜在噪声发生相应变化,则可以根据相机运动重新组织视频。
Video Generation 在相机运动反演之后,呈现相机运动的噪声潜伏器然后通过视频扩散模型的后向过程,利用其布局可控性来指导视频生成。利用基础视频模型的先验知识,生成过程还赋予视频合理的动态信息。
Trade-off Between Fidelity and Diversity 在扩散模型中利用噪声先验指导可能会导致生成保真度和多样性之间的权衡问题,其中对指导更忠实的结果往往会导致生成质量或多样性下降。在这个任务中,类似的情况也会发生,因为模型需要从一系列不完美的渲染中接收指导,同时生成合理的动态视频。平衡权衡问题的关键在于t0的选择。当应用较大的 t0 时,生成与原始指导 V0 更加相似,但缺乏理性和动态,无法成为有吸引力的视频。相反,较小的 t0 会生成良好的视频,但与所需的相机运动不太一致。在我们的实验中,我们发现较大的 t0 对于中等强度的运动效果更好,对于那些相对剧烈的运动,较小的 t0 显示出更好的性能。
3、效果展示
1、基础相机运动控制,缩放、左右移动等

2、混合和复杂的轨迹
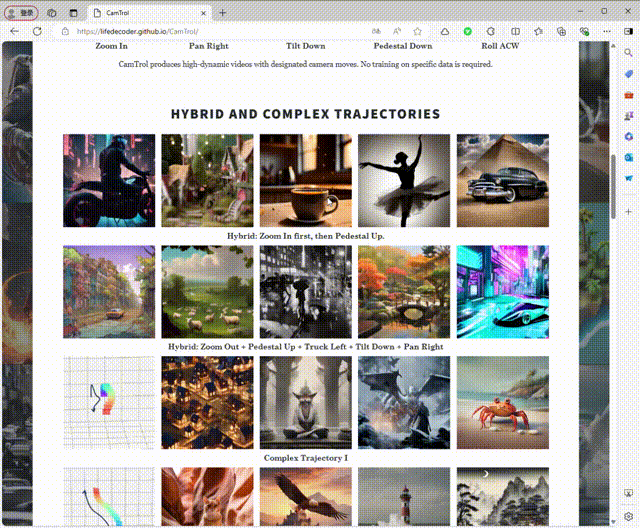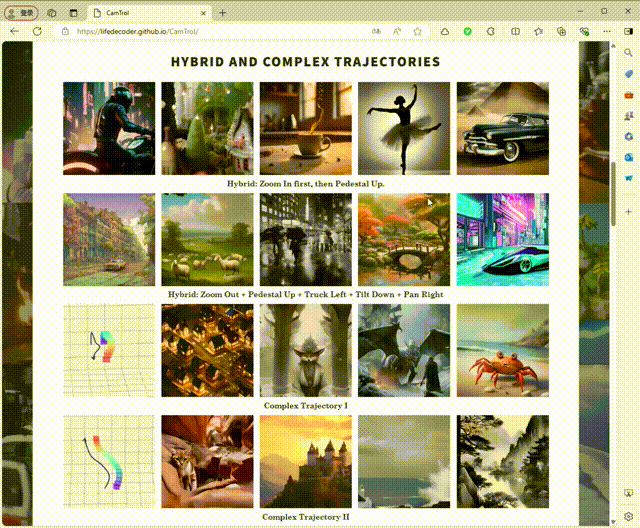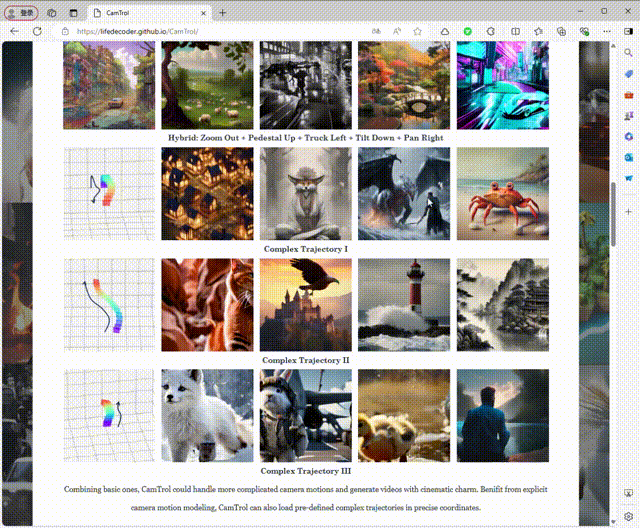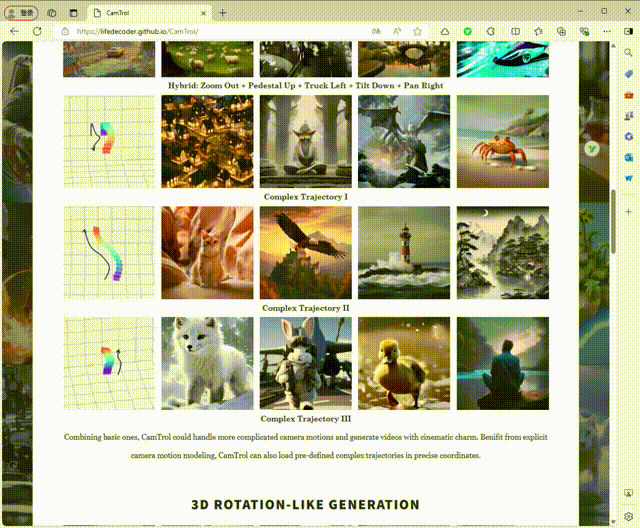
3、3D 类旋转生成

4、不同规模的运动
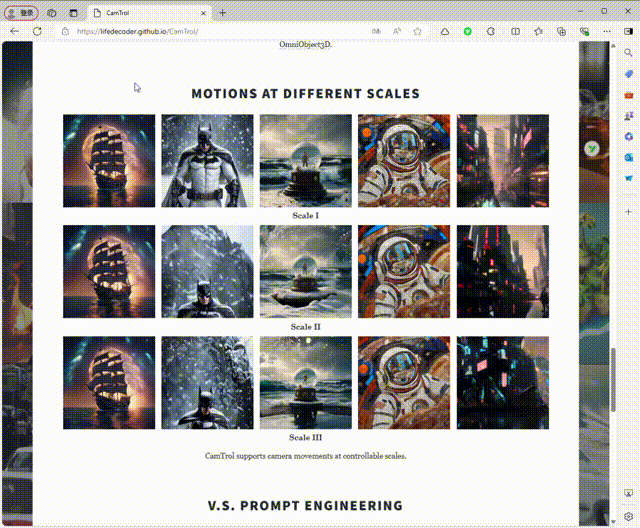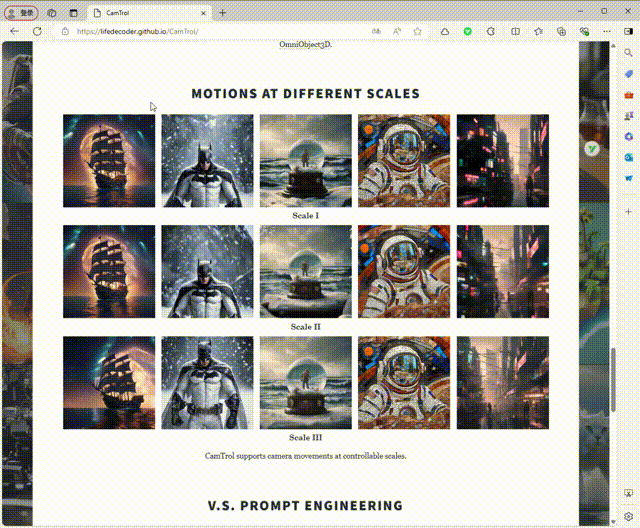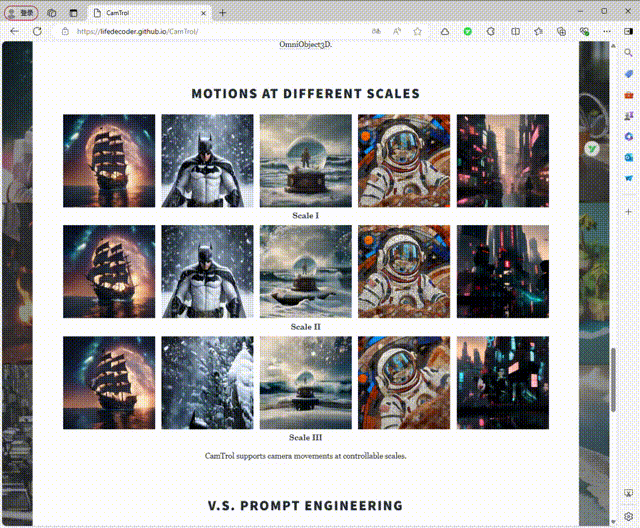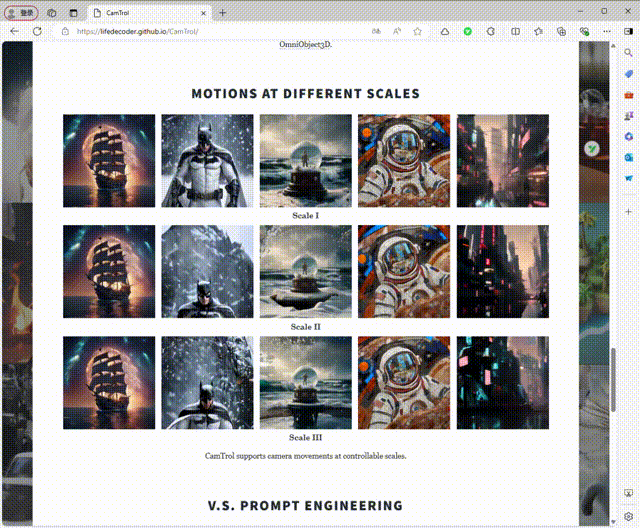
5、对比不同prompt输入

以上就是今天分享的最新成果,如果对大家有帮助,希望能帮忙点赞转发一波,感谢各位小伙伴!!!
课程推荐
对于希望入门 NeRF 或者对这个方向感兴趣但是又担心课程质量,怕被割的小伙伴,可以了解一下哈
下面是课程的大纲和往期学生的一些反馈,内容真实可靠,课程的单价不高,基本上就是赚口碑了,有兴趣的小伙伴可以扫描最下面的二维码了解!!!
课程大纲:

往期学员真实反馈:
扫描了解更多:

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









