






大家好,今天和大家分享一篇关于可控视频生成的最新成果
MotionClone
给定参考视频,MotionClone 可以将视频所包含的动作克隆到新的场景中,具有出色的 prompt-following(指令遵循)能力,而无需针对特定运动进行微调。
prompt-following 更加通俗的解释,就是能够按照你编写的prompt来生成相应的反馈。
如下图所示,通过调整主体以及场景相关的prompt,而不改变运动相关prompt达到生成预期克隆的视频效果。更具体的来说,例如左上角
原本的 prompt:Wolf, turns its head, in the wild
调整后的 prompt:Duck, turns its head, under the water
将主体从 wolf (狼)变成 了 Duck (鸭子),将场景从 in the wild (在野外场景)变成了 under the water(在水里)
除了针对主体动作的克隆外,还可以对相机运动进行克隆,如下图的右侧结果所示,同样通过调整主体和场景的prompt即可生成预期的效果。

实现思路:
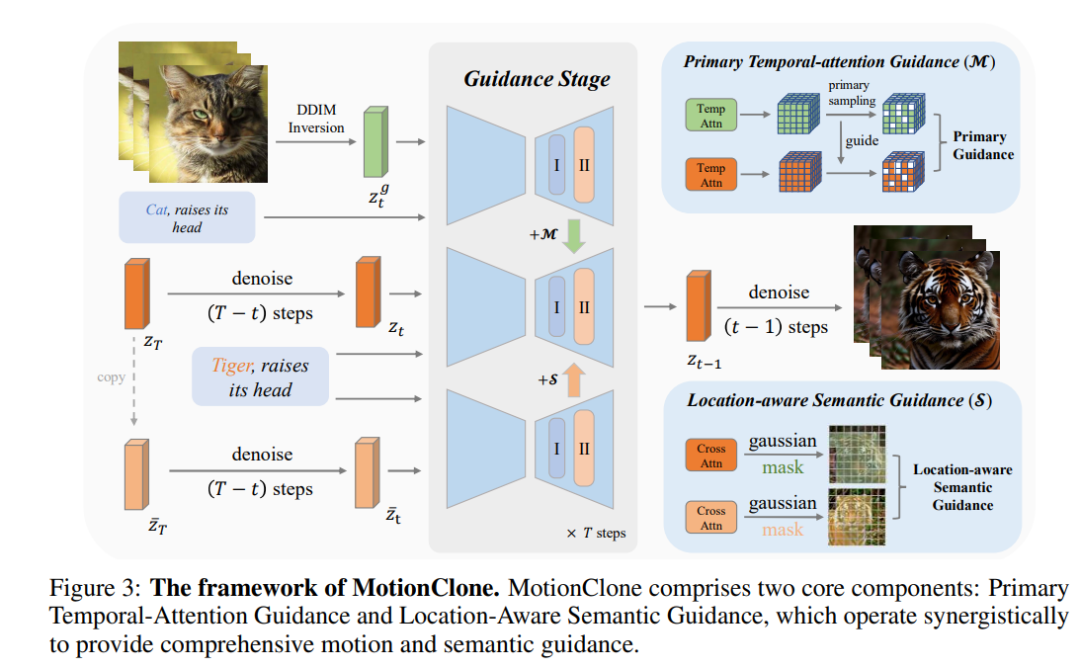
在详细讲解之前,需要提到的是,之前的工作存在的一些不足:
1、当前的工作克隆运动工作,一般的方案是采用光流或运动轨迹,基于光流方案密集的运动线索可能会与参考视频的结构元素纠缠在一起,从而限制了它们对其他对象的迁移性;而基于运动轨迹,虽然捕捉宏观物体运动,但在描述头部转动或举手等更精细的局部运动时,有一定的局限性
2、当前的文本到视频模型有时会合成不合理的空间关系,并且在仅有动作线索的情况下,指令遵循(prompt-following)能力也不尽人意
针对上面两个主要的问题,作者提出了MotionClone 的框架
MotionClone 包含两个核心组件:Primary Temporal-Attention Guidance和Location-Aware Semantic Guidance,它们协同工作以提供全局的运动和语义指导。
1、主成分时序注意力引导,它只利用时序注意力权重的主成分来生成运动引导视频。这种方法能使模型忽略噪声或不太重要的运动,而专注于主要运动,从而显著提高运动克隆的质量。(通俗理解:在视频帧之间构建时序attention的同时,应用时序mask约束)
2、引入主成分时序注意力,依然无法解决生成视频在物理上的不合理。为了解决上述问题,利用参考视频的前景位置和自身视频的外观来提供联合语义引导。
更多测试效果:
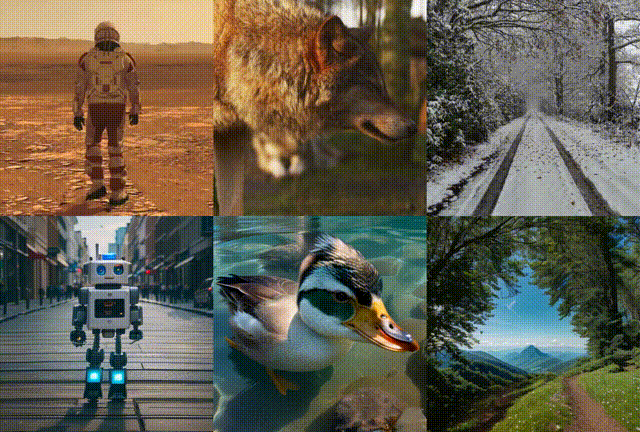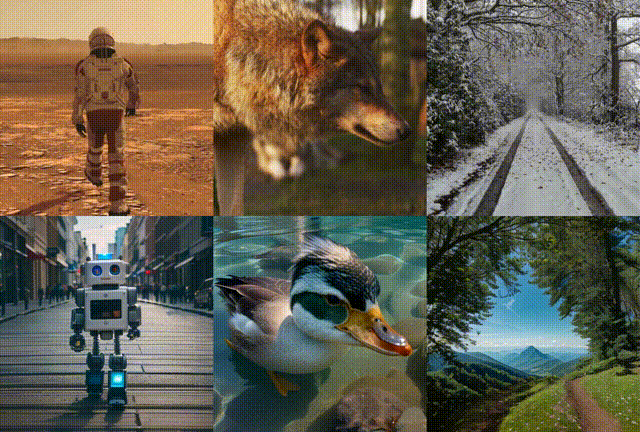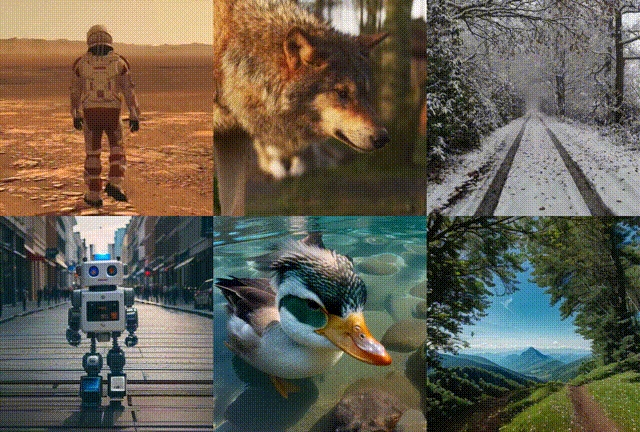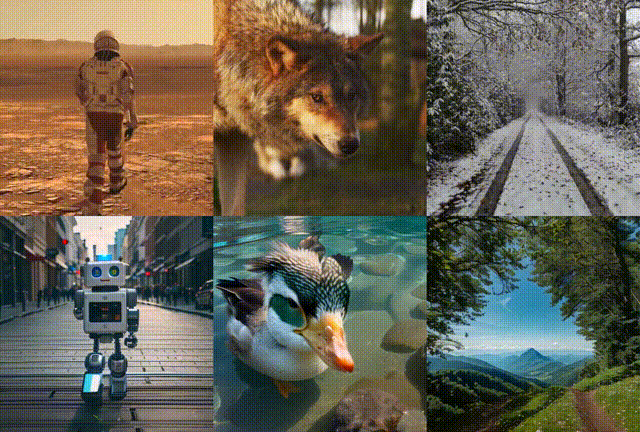




MotionClone 基于相同参考视频生成的多个结果:

论文和项目地址:
https://bujiazi.github.io/motionclone.github.io/
https://arxiv.org/abs/2406.05338
https://github.com/Bujiazi/MotionClone/
更多细节参考论文,由于个人能力有限,部分理解可能存在偏差。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









