







注意事项主要是两个:
第一个,模拟登陆时需要添加header,不然模拟登陆时会报url error:HTTP 403 Forbidden
错误。解决办法也很简单,urllib2 的opener添加opener.addheaders = [('User-agent', 'Mozilla/5.0')]即可。
第二:模拟登陆的参数除了username和password外,另外还有3个参数,其中两个参数是动态生成,这
就要求我们先获取登录页面源码,从中找到这两个动态参数,再写入模拟登陆参数中。如下图两所示:
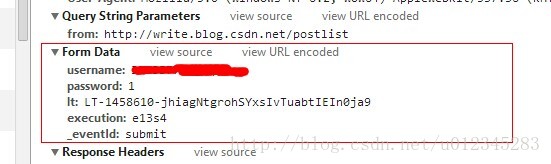

其中,第一幅图的获取涉及抓包插件及post方法。具体情况可参照: [Python]网络爬虫(十):一个爬虫的诞生全过程(以山东大学绩点运算为例)
第二幅图涉及一个方法论:写爬虫一定要具体分析目的页面源码,不能生搬硬套。点击右键-查看页面源代码,即可找到第二幅图片所示代码片段。
源代码如下:
#coding:utf-8
import urllib
import urllib2
import cookielib
import re
filename = 'cookie.txt'
#声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
#动态获取参数,该参数本质为登陆流水号,无该流水号无法成功登陆,采用正则表达式获取
h = opener.open('https://passport.csdn.net').read().decode("utf8")
patten1 = re.compile(r'name="lt" value="(.*?)"')
patten2 = re.compile(r'name="execution" value="(.*?)"')
b1 = patten1.findall(h)
b2 = patten2.findall(h)
postdata = urllib.urlencode({
'username':'你的登录名',
'password':'你的登陆密码',
'rememberMe':'true',
'lt': b1[0],
'execution': b2[0],
'_eventId': 'submit',
})
#登录URL
loginUrl = 'https://passport.csdn.net/account/login'
#模拟登录,并把cookie保存到变量
#添加headers
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
result = opener.open(loginUrl,postdata)
#保存cookie到cookie.txt中
cookie.save(ignore_discard=True, ignore_expires=True)
#利用cookie请求访问另一个网址,此网址是成绩查询网址
gradeUrl = 'http://my.csdn.net/'
#请求访问成绩查询网址
result = opener.open(gradeUrl)
print result.read()















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









