







目录
概率 LSA(Latent Semantic Analysis)潜在语义分析
Latent Dirichlet Allocation潜在狄利克雷分配
理解文本
• 英文维基百科:600 万篇文章
• Twitter:每天 5 亿条推文
• 纽约时报:1500 万篇文章
• arXiv:100 万篇文章
• 如果我们想了解有关这些文档集的一些信息,我们可以做什么?
问题
• 维基百科上不太受欢迎的主题是什么?
• 过去一个月 Twitter 上的主要趋势是什么?
• 从 1900 年代到 2000 年代,《纽约时报》的主题/话题是如何随着时间演变的?
• 有哪些有影响的研究领域?
救援主题模型
• 主题模型学习文档集合中常见的、重叠的主题
• 无监督模型
‣ 无标签; 输入只是文件!
• 主题模型的输出是什么?
‣ 主题:每个主题与单词列表相关联
‣ 主题分配:每个文档关联一个主题列表
主题是什么样的?
• 单词列表
• 集体描述一个概念或主题
• 主题词通常出现在语料库中的同一组文档中
主题模型的应用?
• 个性化广告
• 搜索引擎
• 发现多义词的含义
• 词性标注
大纲
• 主题模型简史
• 潜在狄利克雷分配
• 评估
主题模型简史
之前在第九篇文章中,讲过SVD分解,建议先看一下

其中A 是V*D的,V是单词词表,D是文章
分解后的U代表着词嵌入。
U 是V*m的,我们需要去截断成V*k的,对应Σ就变成k*k,V转置就变成k*D.
问题
• U 和 VT 中的正值和负值
• 难以解释
概率 LSA(Latent Semantic Analysis)潜在语义分析
• 基于概率模型
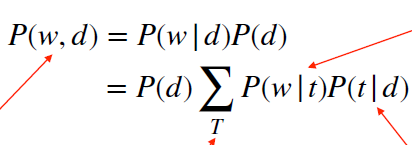
P(w,d):单词和文档的联合概率
P(w|t):主题词分布

P(t|d):文档的主题分布
T:主题数
问题
• 不再有负值!
• PLSA 可以学习训练语料库中文档的主题和主题分配
• 但无法推断新文档的主题分布
• PLSA 需要针对新文件进行再培训
Latent Dirichlet Allocation潜在狄利克雷分配
• 在文档主题和主题词分布之前引入
• 完全生成:经过训练的LDA 模型可以推断未见文档的主题!
• LDA 是 PLSA 的贝叶斯版本
潜在狄利克雷分配
• 核心理念:假设每个文档都包含多个主题
• 但主题结构是隐藏的(潜在的)
• LDA 根据观察到的单词和文档推断主题结构
• LDA 生成文档的软集群(基于主题重叠),而不是硬集群
• 给定一个经过训练的 LDA 模型,它可以推断新文档的主题(不是训练数据的一部分)

输入
• 文档集合
• 词袋
• 良好的预处理实践:
‣ 移除停用词
‣ 去除低频和高频词类型
‣ 词形还原
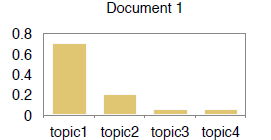
输出
• 主题:每个主题的词分布
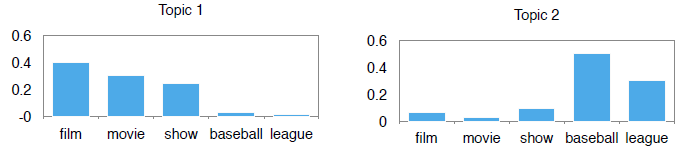
• 主题分配:在每个文档中的主题分布

学习
• 我们如何学习潜在主题?
• 两个主要的算法系列:
‣ 变分方法
‣ 基于采样的方法
采样方法(吉布斯)
1. 给文档中的所有token随机分配topic

2.根据分配收集topic-word和document-topic共现统计

用 β (=0.01) 和 α (=0.1) 先验初始化共现矩阵
3. 遍历语料库中的每个单词标记并采样一个新主题:
![]()
需要在采样前取消分配当前主题分配并更新共现矩阵

![]()
= ![]()
4.转到步骤2并重复直到收敛
我们什么时候停止?
• 训练直到收敛
• 收敛 = 训练集的模型概率变得稳定
• 如何计算模型概率?
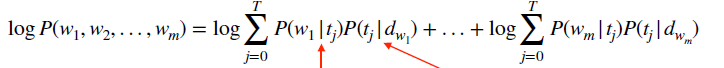
‣ m = #word tokens
超参数
• T:主题数
低 T (<10):广泛的主题
High T (100+):细粒度的、特定的主题
• β:主题词分布的先验
• α:文档主题分布的先验
• 类似于 N-gram LM 中的 add-k 平滑中的 k
• 初始化共生矩阵的伪计数
• 高先验值 → 更平坦的分布
‣ 非常大的值会导致均匀分布
• 低先验值 → 峰值分布
• β:通常很小 (< 0.01)
‣ 词汇量大,但我们希望每个主题都专注于特定主题
• α:通常更大 (> 0.1)
‣ 文档中的多个主题
评估
如何评估主题模型?
• 无监督学习 → 无标签
• 内在评估:
‣ 模拟 logprob / 测试文档的困惑度
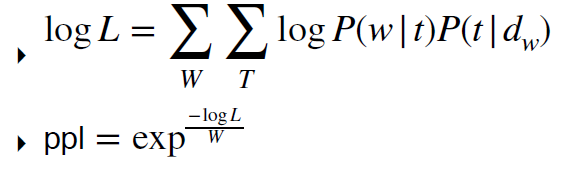
困惑度相关的问题
• 更多主题 = 更好(更低)的困惑
• 更少的词汇量 = 更好的困惑度
‣ 不同语料库或不同标记化/预处理方法的困惑度不可比
• 与人类对主题质量的感知无关
• 外部评估的方法:
‣ 基于下游任务评估主题模型
话题连贯
• 更好的内在评估方法
• 衡量生成的主题的连贯性
• 一个好的主题模型能够生成更连贯的主题
单词入侵
• 想法:为主题注入一个随机词

• 让用户猜测哪个是入侵者词
• 猜对 → 话题连贯
• 尝试猜测以下入侵者的词:
‣ {choice, count, village, i.e., simply, unionist}
• 手动操作; 不缩放
PMI ≈ 一致性?
• 一对词的 PMI高 → 词是相关的;PMI之前的文章有讲过

• 如果主题中的所有词对都具有高 PMI → 主题是连贯的
• 如果大多数主题具有高 PMI → 良好的主题模型
• 哪里可以获得PMI 的词共现统计数据?
‣ 主题模型可以使用相同的语料库
‣ 更好的方法是使用外部语料库(例如维基百科)
PMI
• 计算主题中前 N 个词的成对 PMI
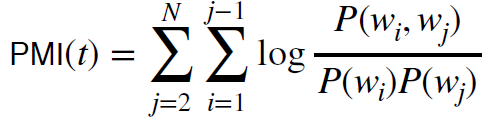
•给定主题: {farmers, farm, food, rice, agriculture}
• 连贯性 = 所有词对的总和 PMI:

变体
• 标准化 PMI

• 条件概率

最后
• 主题模型:一种用于学习文档集合中潜在概念的无监督模型
• LDA:流行的主题模型
‣ 学习
‣ 超参数
• 如何评估主题模型?
‣ 主题连贯性
ok,今天内容到这里就ok,辛苦大家观看!有问题欢迎评论交流!














 3228
3228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









