







概念
树的递归定义:一棵树是N个节点和N-1条边的集合,其中的一个节点叫做根。
根:没有父节点的节点叫做根。
父亲
树叶
兄弟
路径:从节点n1到ni的路径定义为节点n1,n2,…ni的一个序列。这条路径的长,为该路径的边,即i-1。
深度:对节点ni的深度为从根节点到ni的路径长。
高度:对节点ni的高度为从节点ni到叶子节点最长的路径长。
一棵树的高度=一棵树的深度
实现
class TreeNode{
T element;
TreeNode firstChild;
TreeNode nextSibing;
}
遍历
先序遍历、中序遍历、后序遍历。序:相对根节点而言,先处理根节点是先序;先处理左节点,接着处理根节点是中序;先处理左右子节点,接着处理根节点是后序。
二叉树
每个节点子节点数量不大于2的树,称为二叉树。
class BinaryNode{
T element;
BinaryNode leftNode;
BinaryNode rightNode;
}
二叉树应用
表达式
在栈的计算器例子,也可以用树构造,形成表达式树。

二叉查找树
树在查找中的应用形成二叉查找树。二叉树中,如果每个节点X,它的左子树中所有的值都小于X中的值,它的右子树中所有的值都大于X中的值,这样的树称为二叉查找树。节点中存的对象需要可比较,实现Comparable。
二叉查找树的操作
public void makeEmpty()
public boolean isEmpty()
public boolean contains(T x)
public T findMin()
public T findMax()
public void insert(T x)
public void remove(T x)
public void printTree()
删除操作比较复杂,需要考虑要删除的节点有两个子节点、一个子节点、叶子节点的情况。此外还有懒惰删除。
平均情况分析
直观分析,所有操作花费O(logN),因为我们用常数时间,在树中降低了一层,对其操作的树大致减小一半左右。
一棵树的所有节点的深度的和称为内部路径长。
D(N)表示具有N个节点多的二叉查找树树的内部路径长。
D(N) = D(i)+D(N-i-1) +(N-1)
(未完)
AVL树
avl树是一颗带有平衡条件的二叉树。一颗AVL树是其每个节点的左子树和右子树的高度差最多1的二叉查找树。
在高度为h的AVL树中,最少节点数S(h) = S(h-1)+S(h-2)+1。h=0,S(h)=1; h=1,S(h) = 2。这类似于斐波那契数列。因此,除了插入操作外,其他操作(contains findMin findMax)都可以以O(logN)执行。
AVL树保持平衡,需要进行单旋转或者双旋转。写代码实现AVL树。



伸展树
伸展树保证从空树开始,连续M次操作用时O(MlogN),均摊时间就是O(logN)。
二叉查找树的最坏情况是O(N)。如果连续多次发生O(N)就比较糟糕了。伸展树基于我们刚刚被访问过的节点有可能被很快再次访问。
一直旋转到根
伸展树基于想法:一个节点一旦被访问就把这个节点执行多次单旋转,直到根节点。这样的问题是会导致访问其他节点深度变深。最快可能N个节点需要O(n^2)。访问所有元素一次后,树又回到原始状态。
展开
想法同上,只是不依靠每次旋转变为根节点。而是通过AVL树的双旋转。
伸展树适用于内部路径长的树。否则无益。
B树
当要处理的数据已经不能放在内存,必须要放在磁盘上的的时候,怎么优化查找操作呢?这时候大O分析法不再有效。大O模型所有操作耗时相等。但是一台机器 每秒执行5亿条指令,依赖于电的特性;I/O操作,每秒执行120次,是一种机械运动。所以这两种操作的耗时已经不是一个数量级了。当I/O操作量减少一半的时候,耗时减少一半。于是我们需要考虑怎样减少I/O操作。
二叉树平均来看每次查找需要1.38*logN次磁盘访问。1千万数据量,一次查询需要32次磁盘访问,大约5秒。AVL树情形要好些,经常发生logN次,每次查找需要25次访问,大约4秒。
如果减少I/O次数呢?当N一定的时候,有2个分支的树深度一定大于有3个分支的树。如果建立一颗M叉树,可以有效减少树的深度。
M叉树是这样的:1 需要M-1个关键字决定选取哪个分支;2 为防止变为链表,使用B树。B树的特征是:1 数据存储在树叶;2 非叶节点存储知道M-1个关键字以指示搜索的方向;关键字i代表子树i+1中的最小关键字; 3 树的根或者是一片树叶,或者其儿子数在2到M之间; 4 除了根节点外,所有非叶节点的儿子数在M/2到M之间;5 所有的叶子节点都在相同的深度,并有L/2和L之间个数据项。
L怎么确定呢?假设一个区块能容8192个字节,每个关键字32个字节,一条数据256个字节。M阶B树,有M-1个关键字,需要32*(M-1)个字节。每个区块要指向其他数据块,每个指向4字节,共4M字节。32*(M-1)+4M<=8192,M<=228。每个叶子节点最多放L条记录。256*L<=8192,L<=32。最坏情况下树叶将在4层(
4=log228/21千万
) , 也就是说 最坏情况是:
logM/2N
。
以M=5,L=5举例说明B树的添加和删除。
添加
1 可以直接插入的
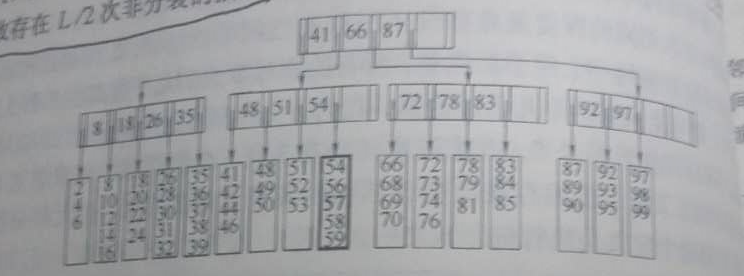
在图4-59插入 57。从根节点开始57<66,下层找第2个子树;57>54,下层找第4个子树。叶子节点只有4个元素,57插入。变为图4-60。

2 需要分裂叶子节点的
在图4-60插入55。找到可以插入的叶子节点发现已经有L个元素了。需要将该叶子节点裂开。插入55一共有6个元素,每个叶子节点3个元素。形成 54 55 56 一个子节点,57 58 59 另外一个子节点。对应的父节点要添加一个关键字57。插入后变为图4-61。

3 需要分裂非叶子节点的
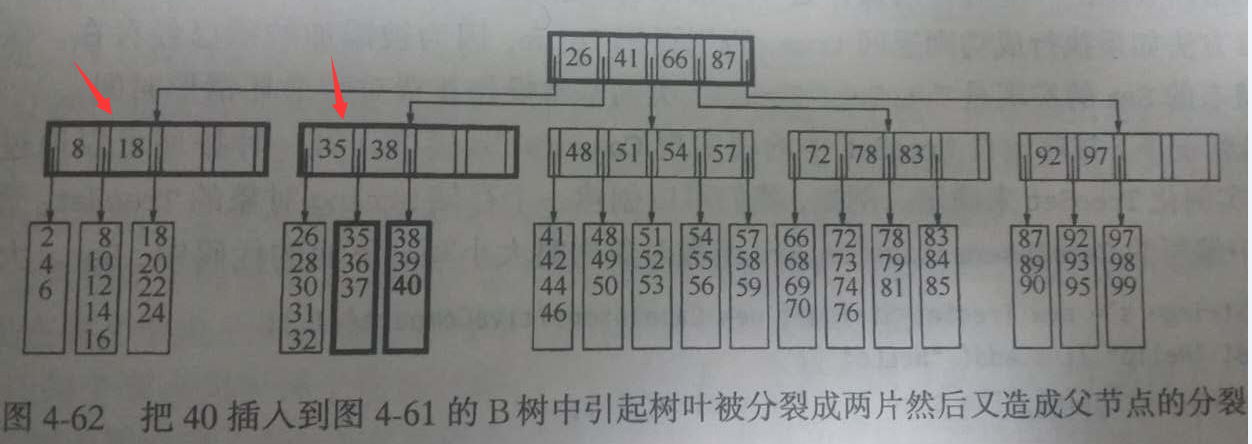
当父节点的儿子个数已满的情况下,怎么办?在上图基础上插入40。出入到第2层第1个子树,第3层第5个叶子节点。叶子节点已满,分裂为 35 36 37;38 39 40;父节点添加40变为:8 18 26 35 40。非叶节点只能存储M-1个值。需要分裂第2层第1个子树,将6个子节点分别挂在两个父节点上。
4 需要分裂根节点的
如果当分裂非叶子节点该层节点数量也满了的时候,就需要分裂上层节点,一直到根。根节点分裂,称为两个树根,再建立一个新的根,两个树根成为新根的子节点。树的高度加1。
5 处理儿子过多的情况的第二种方法–外借
在图4-62中插入29,相邻节点有空间的时候,将最大元素32,移植到相邻空间,修改父节点。这样的处理可以使得节点更慢,在长时间运行中节省空间。

删除
1 删除后不需要合并的
查找到元素,删除即可。
2 删除后合并叶子节点的
如果删除后,发现自己节点与相邻节点合并一下元素个数<=L,则合并。例如删除99,得到下图。序列: 92 93 95 和97 98 合并。


3 继续合并
如果合并后发现父节点个数与相邻节点可以再次合并,则合并。一直合并到根节点。树的高度减1。















 60万+
60万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









