






算法介绍
概念解析
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
贝叶斯定理是以18世纪的一位神学家托马斯.贝叶斯的名字命名,它率先引入先验知识和逻辑推理来处理不确定命题。这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
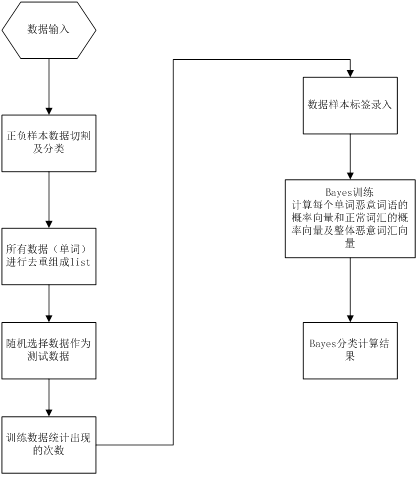
P(A|B)表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:

贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A),贝叶斯定理就为我们打通从P(A|B)获得P(B|A)的道路。
下面不加证明地直接给出贝叶斯定理:
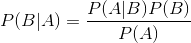
举个例子,某个医院收了6个病人,他们的症状、职业和疾病如下表所示:
| 症状 | 职业 | 疾病 |
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头痛 | 工人 | 脑震荡 |
| 头痛 | 工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头痛 | 教师 | 脑震荡 |
现在又来了第七个病人,是一个打喷嚏的工人。请问他患上感冒的概率有多大?
根据贝叶斯定理:
P(A|B) = P(B|A) P(A) / P(B)
可得
P(感冒|打喷嚏x工人)
= P(打喷嚏x工人|感冒) x P(感冒)
/ P(打喷嚏x工人)
假定"打喷嚏"和"工人"这两个特征是独立的,因此,上面的等式就变成了
P(感冒|打喷嚏x工人)
= P(打喷嚏|感冒) x P(工人|感冒) x P(感冒)
/ P(打喷嚏) x P(工人)
这是可以计算的。
P(感冒|打喷嚏x工人)
= 0.66 x 0.33 x 0.5 / 0.5 x 0.33
= 0.66
因此,这个打喷嚏的工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
朴素贝叶斯模型训练
Python代码实现如下:
deftrainNB0(trainMatrix,trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive =sum(trainCategory)/float(numTrainDocs)
p0Num = ones(numWords); p1Num =ones(numWords) #初始化向量值
p0Denom = 2.0; p1Denom = 2.0 #避免分母为0
for i in range(numTrainDocs):
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom) #恶意单词向量整体相除计算再取log
p0Vect = log(p0Num/p0Denom) #正常单词向量整体相除计算再取log
return p0Vect,p1Vect,pAbusive
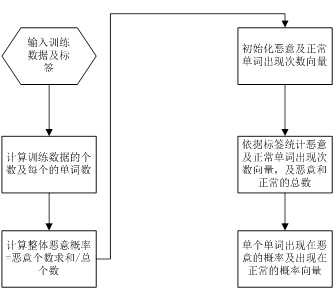
贝叶斯分类计算
Python代码实现如下:
defclassifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) +log(pClass1) #内乘+log
p0 = sum(vec2Classify * p0Vec) + log(1.0 -pClass1)
if p1 > p0:
return 1
else:
return 0
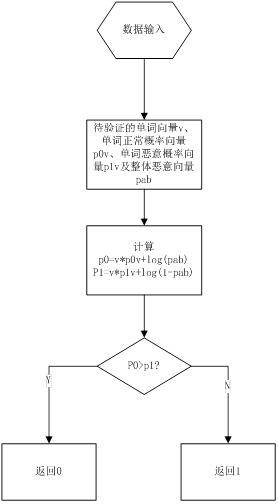
Python基于邮件分类的整体流程如下
优点
可以处理多分类问题
在数据较少的情况下仍然有效
缺点
概率前提是各个特征值是相互独立的,但是现实中这种情况较少,会影响其准确性。另外一种叫贝叶斯网络可以解决特征值关联问题















 3633
3633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









