







https://blog.csdn.net/cnweike/article/details/47398405
https://blog.csdn.net/fisherming/article/details/79509025
https://www.cnblogs.com/DHuifang004/p/11406211.html
https://www.cnblogs.com/elpsycongroo/p/9369171.html
朴素贝叶斯中的朴素一词的来源就是假设各特征之间相互独立。这一假设使得朴素贝叶斯算法变得简单,但有时会牺牲一定的分类准确率。
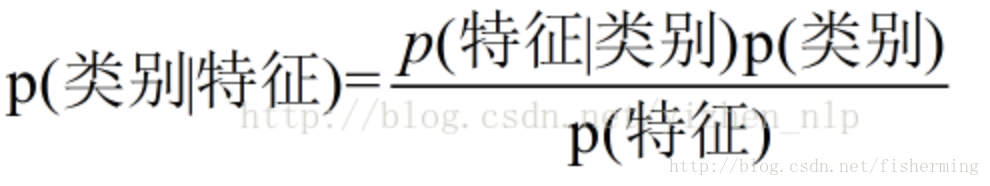

ELEProbDist
expected likelihood estimate = (c+0.5)/(N+B/2)
其中c是这个key的count,也就是label_freqdist [label] 记录的值。N是所以key的值的和,而B若没有明确,则是key的数目。
The
Laplace的smoothing
P( fval | label, fname)
Naive Bayes Introduction
Naive Bayes is a famous probabilistic classifier in the family of machine learning classifiers. Compared to it’s siblings, Naive bayes can be trained very efficiently in a supervised learning setting. In many practical applications, parameter estimation for naive Bayes models uses the method of maximum likelihood; in other words, one can work with the naive Bayes model without accepting Bayesian probability or using any Bayesian methods.(引用维基百科https://en.wikipedia.org/wiki/Naive_Bayes_classifier). Further more, Naive bayes can estimate the necessary parameters (mean and variance of variables) based on a small amount of training data, which means Naive Bayes dose not rely on large data sets. The name naive bayes comes from the assumption of strong conditional independence between the features. The mathematical representation of naive bayes shows as Eq(\ref{equ:**}}):
f
(
x
)
=
arg
min
y
j
P
(
y
j
)
∏
i
=
1
n
P
(
x
i
∣
y
j
)
f(x)=\mathop{\arg\min}_{y_j} P(y_j)\prod_{i=1}^{n}P(x_i|y_j)
f(x)=argminyjP(yj)i=1∏nP(xi∣yj)
Smoothing and Training Estimator
if a certain feature of category
y
j
y_j
yj,
x
i
x_i
xi, does not have the value
v
v
v in the training set, we could get
p
(
x
i
∣
y
j
)
=
0
p(x_i|y_j) = 0
p(xi∣yj)=0 and the probability that the sample with property
x
i
=
v
x_i=v
xi=v and other properties accord with the characteristics of type
y
j
y_j
yj will equal to zero. This is clearly unreasonable.
The problem is essentially that our training set is incomplete and does not include enough samples. To avoid this problem, we typically make corrections while estimating the probabilities, often using a Laplacian smoothing. However, we choose to use the smoothing method used in famous NLP tool NLTK called Expected Likelihood Estimator, shown as:
E
x
p
e
c
t
e
d
L
i
k
e
l
i
h
o
o
d
E
s
t
i
m
a
t
e
=
C
+
0.5
N
+
B
/
2
Expected\ Likelihood\ Estimate = \frac{C+0.5}{N+B/2}
Expected Likelihood Estimate=N+B/2C+0.5
where
C
C
C denotes the size of the samples belonging to the label
y
j
y_j
yj,
N
N
N denotes the total sample size and
B
B
B is the number of sample label types. During training, the Naive Bayes Classifier constructs probability distributions for each feature using the estimator to calculate the probability of a label parameter given a specific feature. So, we can get
P
^
(
y
i
)
\hat{P}(y_i)
P^(yi) and
P
^
(
x
i
∣
y
j
)
\hat{P}(x_i|y_j)
P^(xi∣yj) after training.
(引用Natural Language Processing: Python and NLTK, By Nitin Hardeniya, Jacob Perkins, Deepti Chopra, Nisheeth Joshi, Iti Mathur Packt Publishing Ltd, Nov 22, 2016)
Our Work
过程简述
首先,我们手工创建了三个训练数据集,分别命名为数据集a, 数据集b和数据集c。其中,数据集a和数据集b的格式为(单词,类型),类型分别为’pos’和’neg’,代表积极和消极的单词。数据集a有80条数据,数据集b有283条数据。数据集c是在数据集a的基础上加上400条采样于microwave的review_headline数据(标签规则为:当star_rating>2.5时标记为’pos’,否则标记为’neg’)得到的数据集。我们工作的流程如下图:
First, we manually created three training data sets, named data set a, data set b and data set c. Where, the format of dataset a and dataset b is (word, type), and the types are ‘pos’ and ‘neg’ respectively, representing positive and negative words. Data set a has 80 pieces of data, and data set b has 283 pieces of data. Dataset c is the dataset from dataset a plus 400 ‘review_headline’ data sampled from the microwave (label ‘pos’ when star_rating>2.5, otherwise labeled ‘neg’). The flow of our work is shown below
此处插入那个流程图
三个数据集在三种商品的上的结果为:
结果:插入表格
结果分析:Specific quality descriptors of text-based reviews such as ‘enthusiastic’, ‘disappointed’, and others is strongly associated with rating levels.















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









